 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Skeleton and Flesh: Efficient Multimodal Table Reasoning with Disentangled Alignment and Structure-aware Guidance
Feb 03, 2026Reasoning over table images remains challenging for Large Vision-Language Models (LVLMs) due to complex layouts and tightly coupled structure-content information. Existing solutions often depend on expensive supervised training, reinforcement learning, or external tools, limiting efficiency and scalability. This work addresses a key question: how to adapt LVLMs to table reasoning with minimal annotation and no external tools? Specifically, we first introduce DiSCo, a Disentangled Structure-Content alignment framework that explicitly separates structural abstraction from semantic grounding during multimodal alignment, efficiently adapting LVLMs to tables structures. Building on DiSCo, we further present Table-GLS, a Global-to-Local Structure-guided reasoning framework that performs table reasoning via structured exploration and evidence-grounded inference. Extensive experiments across diverse benchmarks demonstrate that our framework efficiently enhances LVLM's table understanding and reasoning capabilities, particularly generalizing to unseen table structures.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
From Bias to Balance: Exploring and Mitigating Spatial Bias in LVLMs
Sep 26, 2025
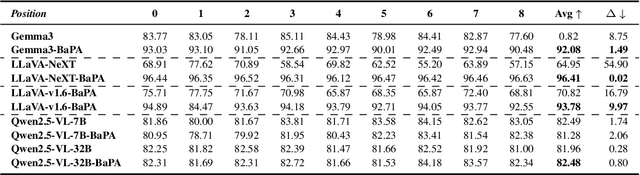
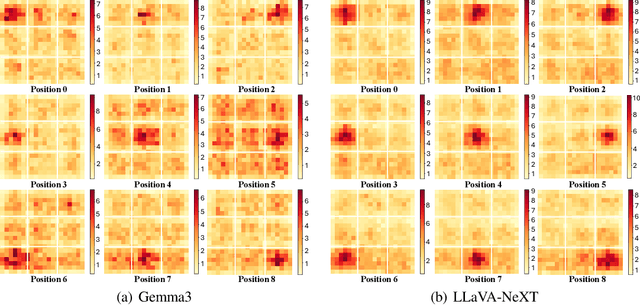
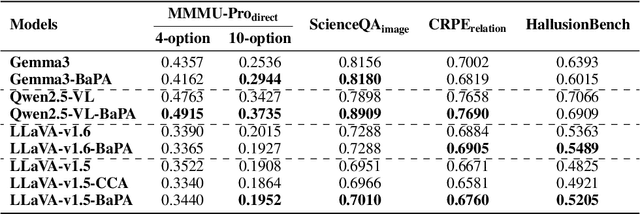
Large Vision-Language Models (LVLMs) have achieved remarkable success across a wide range of multimodal tasks, yet their robustness to spatial variations remains insufficiently understood. In this work, we present a systematic study of the spatial bias of LVLMs, focusing on how models respond when identical key visual information is placed at different locations within an image. Through a carefully designed probing dataset, we demonstrate that current LVLMs often produce inconsistent outputs under such spatial shifts, revealing a fundamental limitation in their spatial-semantic understanding. Further analysis shows that this phenomenon originates not from the vision encoder, which reliably perceives and interprets visual content across positions, but from the unbalanced design of position embeddings in the language model component. In particular, the widely adopted position embedding strategies, such as RoPE, introduce imbalance during cross-modal interaction, leading image tokens at different positions to exert unequal influence on semantic understanding. To mitigate this issue, we introduce Balanced Position Assignment (BaPA), a simple yet effective mechanism that assigns identical position embeddings to all image tokens, promoting a more balanced integration of visual information. Extensive experiments show that BaPA enhances the spatial robustness of LVLMs without retraining and further boosts their performance across diverse multimodal benchmarks when combined with lightweight fine-tuning. Further analysis of information flow reveals that BaPA yields balanced attention, enabling more holistic visual understanding.
P/D-Device: Disaggregated Large Language Model between Cloud and Devices
Aug 12, 2025Serving disaggregated large language models has been widely adopted in industrial practice for enhanced performance. However, too many tokens generated in decoding phase, i.e., occupying the resources for a long time, essentially hamper the cloud from achieving a higher throughput. Meanwhile, due to limited on-device resources, the time to first token (TTFT), i.e., the latency of prefill phase, increases dramatically with the growth on prompt length. In order to concur with such a bottleneck on resources, i.e., long occupation in cloud and limited on-device computing capacity, we propose to separate large language model between cloud and devices. That is, the cloud helps a portion of the content for each device, only in its prefill phase. Specifically, after receiving the first token from the cloud, decoupling with its own prefill, the device responds to the user immediately for a lower TTFT. Then, the following tokens from cloud are presented via a speed controller for smoothed TPOT (the time per output token), until the device catches up with the progress. On-device prefill is then amortized using received tokens while the resource usage in cloud is controlled. Moreover, during cloud prefill, the prompt can be refined, using those intermediate data already generated, to further speed up on-device inference. We implement such a scheme P/D-Device, and confirm its superiority over other alternatives. We further propose an algorithm to decide the best settings. Real-trace experiments show that TTFT decreases at least 60%, maximum TPOT is about tens of milliseconds, and cloud throughput increases by up to 15x.
SynGraph: A Dynamic Graph-LLM Synthesis Framework for Sparse Streaming User Sentiment Modeling
Mar 06, 2025User reviews on e-commerce platforms exhibit dynamic sentiment patterns driven by temporal and contextual factors. Traditional sentiment analysis methods focus on static reviews, failing to capture the evolving temporal relationship between user sentiment rating and textual content. Sentiment analysis on streaming reviews addresses this limitation by modeling and predicting the temporal evolution of user sentiments. However, it suffers from data sparsity, manifesting in temporal, spatial, and combined forms. In this paper, we introduce SynGraph, a novel framework designed to address data sparsity in sentiment analysis on streaming reviews. SynGraph alleviates data sparsity by categorizing users into mid-tail, long-tail, and extreme scenarios and incorporating LLM-augmented enhancements within a dynamic graph-based structure. Experiments on real-world datasets demonstrate its effectiveness in addressing sparsity and improving sentiment modeling in streaming reviews.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Benchmarking and Improving Large Vision-Language Models for Fundamental Visual Graph Understanding and Reasoning
Dec 18, 2024



Large Vision-Language Models (LVLMs) have demonstrated remarkable performance across diverse tasks. Despite great success, recent studies show that LVLMs encounter substantial limitations when engaging with visual graphs. To study the reason behind these limitations, we propose VGCure, a comprehensive benchmark covering 22 tasks for examining the fundamental graph understanding and reasoning capacities of LVLMs. Extensive evaluations conducted on 14 LVLMs reveal that LVLMs are weak in basic graph understanding and reasoning tasks, particularly those concerning relational or structurally complex information. Based on this observation, we propose a structure-aware fine-tuning framework to enhance LVLMs with structure learning abilities through 3 self-supervised learning tasks. Experiments validate the effectiveness of our method in improving LVLMs' zero-shot performance on fundamental graph learning tasks, as well as enhancing the robustness of LVLMs against complex visual graphs.
CHECKWHY: Causal Fact Verification via Argument Structure
Aug 20, 2024With the growing complexity of fact verification tasks, the concern with "thoughtful" reasoning capabilities is increasing. However, recent fact verification benchmarks mainly focus on checking a narrow scope of semantic factoids within claims and lack an explicit logical reasoning process. In this paper, we introduce CheckWhy, a challenging dataset tailored to a novel causal fact verification task: checking the truthfulness of the causal relation within claims through rigorous reasoning steps. CheckWhy consists of over 19K "why" claim-evidence-argument structure triplets with supports, refutes, and not enough info labels. Each argument structure is composed of connected evidence, representing the reasoning process that begins with foundational evidence and progresses toward claim establishment. Through extensive experiments on state-of-the-art models, we validate the importance of incorporating the argument structure for causal fact verification. Moreover, the automated and human evaluation of argument structure generation reveals the difficulty in producing satisfying argument structure by fine-tuned models or Chain-of-Thought prompted LLMs, leaving considerable room for future improvements.
TSOM: Small Object Motion Detection Neural Network Inspired by Avian Visual Circuit
Apr 01, 2024



Detecting small moving objects in complex backgrounds from an overhead perspective is a highly challenging task for machine vision systems. As an inspiration from nature, the avian visual system is capable of processing motion information in various complex aerial scenes, and its Retina-OT-Rt visual circuit is highly sensitive to capturing the motion information of small objects from high altitudes. However, more needs to be done on small object motion detection algorithms based on the avian visual system. In this paper, we conducted mathematical modeling based on extensive studies of the biological mechanisms of the Retina-OT-Rt visual circuit. Based on this, we proposed a novel tectum small object motion detection neural network (TSOM). The neural network includes the retina, SGC dendritic, SGC Soma, and Rt layers, each layer corresponding to neurons in the visual pathway. The Retina layer is responsible for accurately projecting input content, the SGC dendritic layer perceives and encodes spatial-temporal information, the SGC Soma layer computes complex motion information and extracts small objects, and the Rt layer integrates and decodes motion information from multiple directions to determine the position of small objects. Extensive experiments on pigeon neurophysiological experiments and image sequence data showed that the TSOM is biologically interpretable and effective in extracting reliable small object motion features from complex high-altitude backgrounds.
EXPLAIN, EDIT, GENERATE: Rationale-Sensitive Counterfactual Data Augmentation for Multi-hop Fact Verification
Oct 23, 2023Automatic multi-hop fact verification task has gained significant attention in recent years. Despite impressive results, these well-designed models perform poorly on out-of-domain data. One possible solution is to augment the training data with counterfactuals, which are generated by minimally altering the causal features of the original data. However, current counterfactual data augmentation techniques fail to handle multi-hop fact verification due to their incapability to preserve the complex logical relationships within multiple correlated texts. In this paper, we overcome this limitation by developing a rationale-sensitive method to generate linguistically diverse and label-flipping counterfactuals while preserving logical relationships. In specific, the diverse and fluent counterfactuals are generated via an Explain-Edit-Generate architecture. Moreover, the checking and filtering modules are proposed to regularize the counterfactual data with logical relations and flipped labels. Experimental results show that the proposed approach outperforms the SOTA baselines and can generate linguistically diverse counterfactual data without disrupting their logical relationships.