 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-GRPO: Stabilizing Multi-Agent Topology Learning via Group Relative Policy Optimization
Mar 03, 2026Optimizing communication topology is fundamental to the efficiency and effectiveness of Large Language Model (LLM)-based Multi-Agent Systems (MAS). While recent approaches utilize reinforcement learning to dynamically construct task-specific graphs, they typically rely on single-sample policy gradients with absolute rewards (e.g., binary correctness). This paradigm suffers from severe gradient variance and the credit assignment problem: simple queries yield non-informative positive rewards for suboptimal structures, while difficult queries often result in failures that provide no learning signal. To address these challenges, we propose Graph-GRPO, a novel topology optimization framework that integrates Group Relative Policy Optimization. Instead of evaluating a single topology in isolation, Graph-GRPO samples a group of diverse communication graphs for each query and computes the advantage of specific edges based on their relative performance within the group. By normalizing rewards across the sampled group, our method effectively mitigates the noise derived from task difficulty variance and enables fine-grained credit assignment. Extensive experiments on reasoning and code generation benchmarks demonstrate that Graph-GRPO significantly outperforms state-of-the-art baselines, achieving superior training stability and identifying critical communication pathways previously obscured by reward noise.
Intelligent Pathological Diagnosis of Gestational Trophoblastic Diseases via Visual-Language Deep Learning Model
Mar 03, 2026The pathological diagnosis of gestational trophoblastic disease(GTD) takes a long time, relies heavily on the experience of pathologists, and the consistency of initial diagnosis is low, which seriously threatens maternal health and reproductive outcomes. We developed an expert model for GTD pathological diagnosis, named GTDoctor. GTDoctor can perform pixel-based lesion segmentation on pathological slides, and output diagnostic conclusions and personalized pathological analysis results. We developed a software system, GTDiagnosis, based on this technology and conducted clinical trials. The retrospective results demonstrated that GTDiagnosis achieved a mean precision of over 0.91 for lesion detection in pathological slides (n=679 slides). In prospective studies, pathologists using GTDiagnosis attained a Positive Predictive Value of 95.59% (n=68 patients). The tool reduced average diagnostic time from 56 to 16 seconds per case (n=285 patients). GTDoctor and GTDiagnosis offer a novel solution for GTD pathological diagnosis, enhancing diagnostic performance and efficiency while maintaining clinical interpretability.
Shared DIFF Transformer
Jan 29, 2025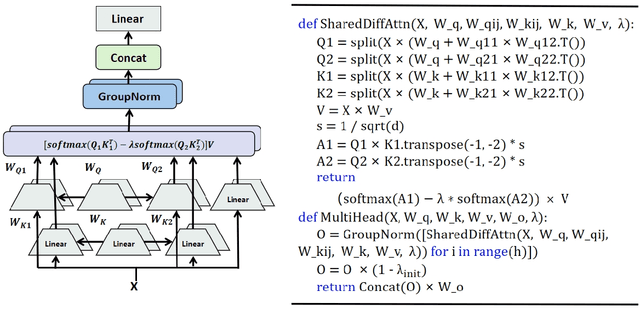
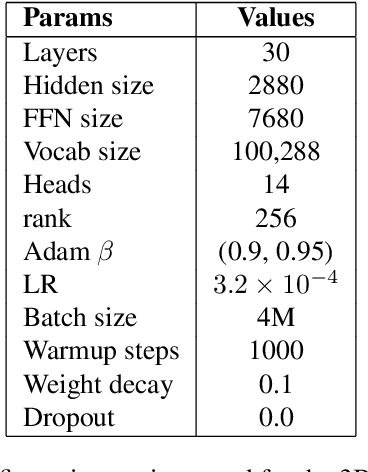
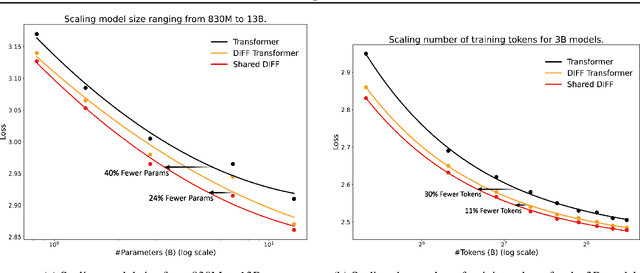
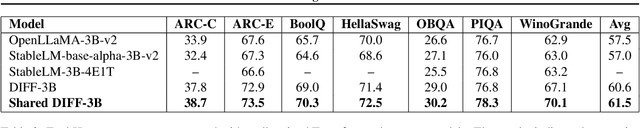
DIFF Transformer improves attention allocation by enhancing focus on relevant context while suppressing noise. It introduces a differential attention mechanism that calculates the difference between two independently generated attention distributions, effectively reducing noise and promoting sparse attention patterns. However, the independent signal generation in DIFF Transformer results in parameter redundancy and suboptimal utilization of information. In this work, we propose Shared DIFF Transformer, which draws on the idea of a differential amplifier by introducing a shared base matrix to model global patterns and incorporating low-rank updates to enhance task-specific flexibility. This design significantly reduces parameter redundancy, improves efficiency, and retains strong noise suppression capabilities. Experimental results show that, compared to DIFF Transformer, our method achieves better performance in tasks such as long-sequence modeling, key information retrieval, and in-context learning. Our work provides a novel and efficient approach to optimizing differential attention mechanisms and advancing robust Transformer architectures.
DINT Transformer
Jan 29, 2025DIFF Transformer addresses the issue of irrelevant context interference by introducing a differential attention mechanism that enhances the robustness of local attention. However, it has two critical limitations: the lack of global context modeling, which is essential for identifying globally significant tokens, and numerical instability due to the absence of strict row normalization in the attention matrix. To overcome these challenges, we propose DINT Transformer, which extends DIFF Transformer by incorporating a differential-integral mechanism. By computing global importance scores and integrating them into the attention matrix, DINT Transformer improves its ability to capture global dependencies. Moreover, the unified parameter design enforces row-normalized attention matrices, improving numerical stability. Experimental results demonstrate that DINT Transformer excels in accuracy and robustness across various practical applications, such as long-context language modeling and key information retrieval. These results position DINT Transformer as a highly effective and promising architecture.
RetCompletion:High-Speed Inference Image Completion with Retentive Network
Oct 05, 2024



Time cost is a major challenge in achieving high-quality pluralistic image completion. Recently, the Retentive Network (RetNet) in natural language processing offers a novel approach to this problem with its low-cost inference capabilities. Inspired by this, we apply RetNet to the pluralistic image completion task in computer vision. We present RetCompletion, a two-stage framework. In the first stage, we introduce Bi-RetNet, a bidirectional sequence information fusion model that integrates contextual information from images. During inference, we employ a unidirectional pixel-wise update strategy to restore consistent image structures, achieving both high reconstruction quality and fast inference speed. In the second stage, we use a CNN for low-resolution upsampling to enhance texture details. Experiments on ImageNet and CelebA-HQ demonstrate that our inference speed is 10$\times$ faster than ICT and 15$\times$ faster than RePaint. The proposed RetCompletion significantly improves inference speed and delivers strong performance, especially when masks cover large areas of the image.
TSOM: Small Object Motion Detection Neural Network Inspired by Avian Visual Circuit
Apr 01, 2024



Detecting small moving objects in complex backgrounds from an overhead perspective is a highly challenging task for machine vision systems. As an inspiration from nature, the avian visual system is capable of processing motion information in various complex aerial scenes, and its Retina-OT-Rt visual circuit is highly sensitive to capturing the motion information of small objects from high altitudes. However, more needs to be done on small object motion detection algorithms based on the avian visual system. In this paper, we conducted mathematical modeling based on extensive studies of the biological mechanisms of the Retina-OT-Rt visual circuit. Based on this, we proposed a novel tectum small object motion detection neural network (TSOM). The neural network includes the retina, SGC dendritic, SGC Soma, and Rt layers, each layer corresponding to neurons in the visual pathway. The Retina layer is responsible for accurately projecting input content, the SGC dendritic layer perceives and encodes spatial-temporal information, the SGC Soma layer computes complex motion information and extracts small objects, and the Rt layer integrates and decodes motion information from multiple directions to determine the position of small objects. Extensive experiments on pigeon neurophysiological experiments and image sequence data showed that the TSOM is biologically interpretable and effective in extracting reliable small object motion features from complex high-altitude backgrounds.
HVDetFusion: A Simple and Robust Camera-Radar Fusion Framework
Jul 21, 2023



In the field of autonomous driving, 3D object detection is a very important perception module. Although the current SOTA algorithm combines Camera and Lidar sensors, limited by the high price of Lidar, the current mainstream landing schemes are pure Camera sensors or Camera+Radar sensors. In this study, we propose a new detection algorithm called HVDetFusion, which is a multi-modal detection algorithm that not only supports pure camera data as input for detection, but also can perform fusion input of radar data and camera data. The camera stream does not depend on the input of Radar data, thus addressing the downside of previous methods. In the pure camera stream, we modify the framework of Bevdet4D for better perception and more efficient inference, and this stream has the whole 3D detection output. Further, to incorporate the benefits of Radar signals, we use the prior information of different object positions to filter the false positive information of the original radar data, according to the positioning information and radial velocity information recorded by the radar sensors to supplement and fuse the BEV features generated by the original camera data, and the effect is further improved in the process of fusion training. Finally, HVDetFusion achieves the new state-of-the-art 67.4\% NDS on the challenging nuScenes test set among all camera-radar 3D object detectors. The code is available at https://github.com/HVXLab/HVDetFusion
Qiniu Submission to ActivityNet Challenge 2018
Jun 12, 2018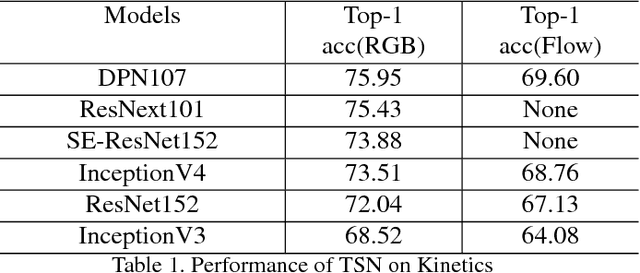
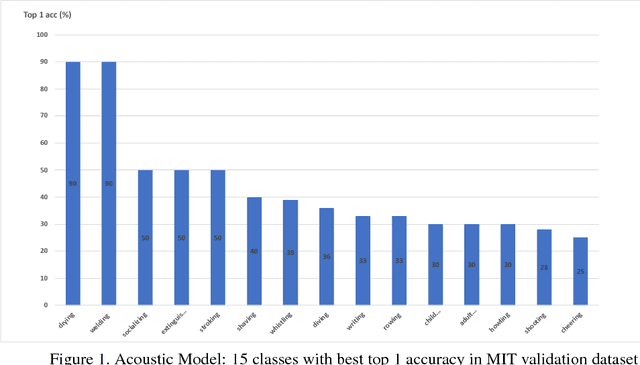
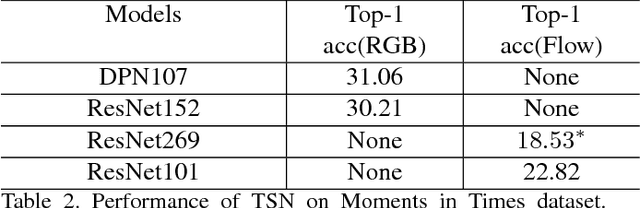
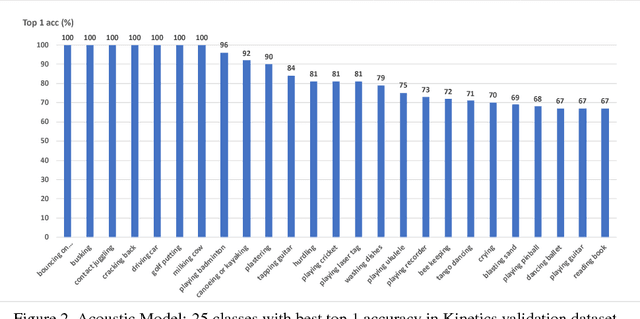
In this paper, we introduce our submissions for the tasks of trimmed activity recognition (Kinetics) and trimmed event recognition (Moments in Time) for Activitynet Challenge 2018. In the two tasks, non-local neural networks and temporal segment networks are implemented as our base models. Multi-modal cues such as RGB image, optical flow and acoustic signal have also been used in our method. We also propose new non-local-based models for further improvement on the recognition accuracy. The final submissions after ensembling the models achieve 83.5% top-1 accuracy and 96.8% top-5 accuracy on the Kinetics validation set, 35.81% top-1 accuracy and 62.59% top-5 accuracy on the MIT validation set.