Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiniu Submission to ActivityNet Challenge 2018
Paper and Code
Jun 12, 2018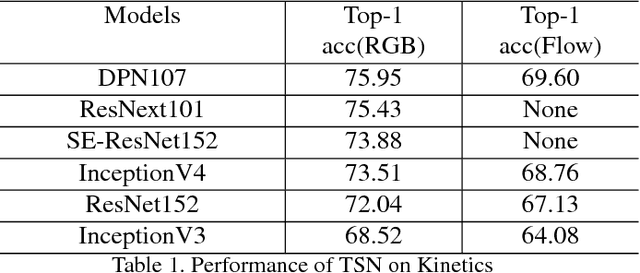
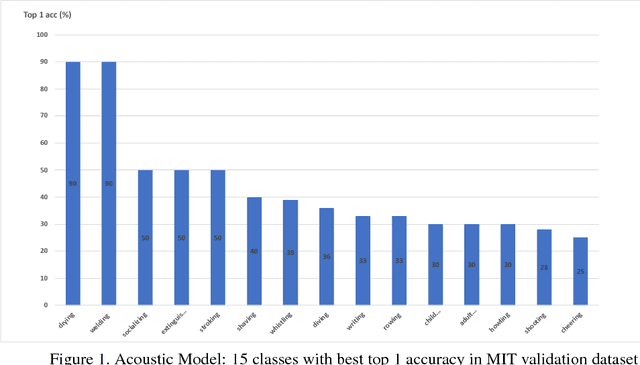
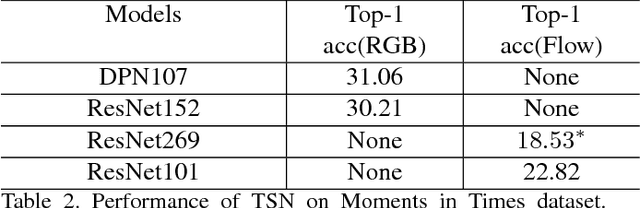
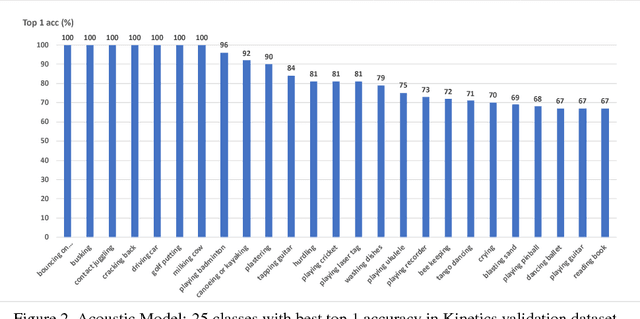
In this paper, we introduce our submissions for the tasks of trimmed activity recognition (Kinetics) and trimmed event recognition (Moments in Time) for Activitynet Challenge 2018. In the two tasks, non-local neural networks and temporal segment networks are implemented as our base models. Multi-modal cues such as RGB image, optical flow and acoustic signal have also been used in our method. We also propose new non-local-based models for further improvement on the recognition accuracy. The final submissions after ensembling the models achieve 83.5% top-1 accuracy and 96.8% top-5 accuracy on the Kinetics validation set, 35.81% top-1 accuracy and 62.59% top-5 accuracy on the MIT validation set.
* 4 pages, 3 figures, CVPR workshop
View paper on