 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQianfan-OCR: A Unified End-to-End Model for Document Intelligence
Mar 11, 2026We present Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies document parsing, layout analysis, and document understanding within a single architecture. It performs direct image-to-Markdown conversion and supports diverse prompt-driven tasks including table extraction, chart understanding, document QA, and key information extraction. To address the loss of explicit layout analysis in end-to-end OCR, we propose Layout-as-Thought, an optional thinking phase triggered by special think tokens that generates structured layout representations -- bounding boxes, element types, and reading order -- before producing final outputs, recovering layout grounding capabilities while improving accuracy on complex layouts. Qianfan-OCR ranks first among end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8), achieves competitive results on OCRBench, CCOCR, DocVQA, and ChartQA against general VLMs of comparable scale, and attains the highest average score on public key information extraction benchmarks, surpassing Gemini-3.1-Pro, Seed-2.0, and Qwen3-VL-235B. The model is publicly accessible via the Baidu AI Cloud Qianfan platform.
A Hierarchical, Model-Based System for High-Performance Humanoid Soccer
Dec 10, 2025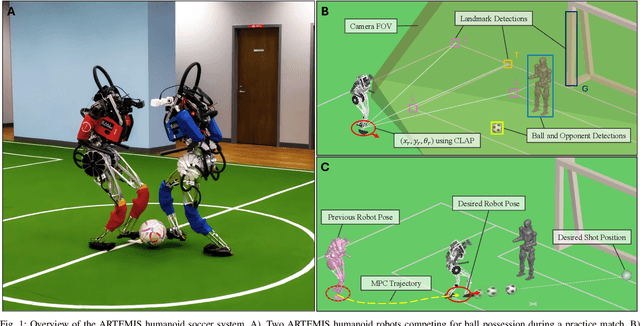
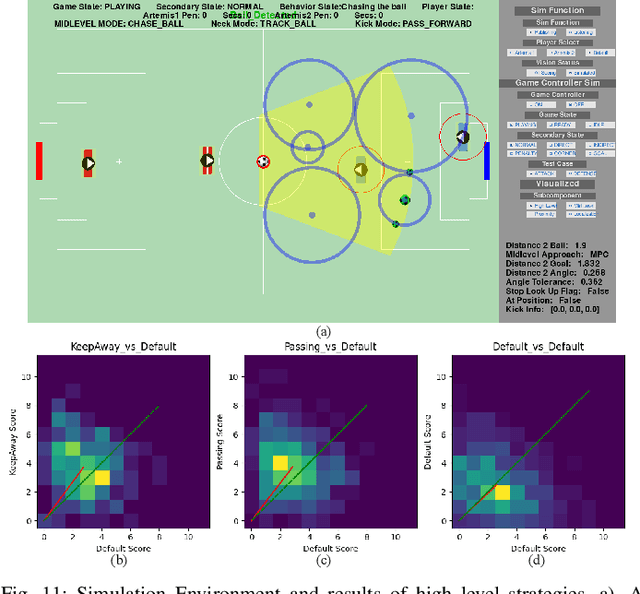

The development of athletic humanoid robots has gained significant attention as advances in actuation, sensing, and control enable increasingly dynamic, real-world capabilities. RoboCup, an international competition of fully autonomous humanoid robots, provides a uniquely challenging benchmark for such systems, culminating in the long-term goal of competing against human soccer players by 2050. This paper presents the hardware and software innovations underlying our team's victory in the RoboCup 2024 Adult-Sized Humanoid Soccer Competition. On the hardware side, we introduce an adult-sized humanoid platform built with lightweight structural components, high-torque quasi-direct-drive actuators, and a specialized foot design that enables powerful in-gait kicks while preserving locomotion robustness. On the software side, we develop an integrated perception and localization framework that combines stereo vision, object detection, and landmark-based fusion to provide reliable estimates of the ball, goals, teammates, and opponents. A mid-level navigation stack then generates collision-aware, dynamically feasible trajectories, while a centralized behavior manager coordinates high-level decision making, role selection, and kick execution based on the evolving game state. The seamless integration of these subsystems results in fast, precise, and tactically effective gameplay, enabling robust performance under the dynamic and adversarial conditions of real matches. This paper presents the design principles, system architecture, and experimental results that contributed to ARTEMIS's success as the 2024 Adult-Sized Humanoid Soccer champion.
Branching Strategies Based on Subgraph GNNs: A Study on Theoretical Promise versus Practical Reality
Dec 10, 2025Graph Neural Networks (GNNs) have emerged as a promising approach for ``learning to branch'' in Mixed-Integer Linear Programming (MILP). While standard Message-Passing GNNs (MPNNs) are efficient, they theoretically lack the expressive power to fully represent MILP structures. Conversely, higher-order GNNs (like 2-FGNNs) are expressive but computationally prohibitive. In this work, we investigate Subgraph GNNs as a theoretical middle ground. Crucially, while previous work [Chen et al., 2025] demonstrated that GNNs with 3-WL expressive power can approximate Strong Branching, we prove a sharper result: node-anchored Subgraph GNNs whose expressive power is strictly lower than 3-WL [Zhang et al., 2023] are sufficient to approximate Strong Branching scores. However, our extensive empirical evaluation on four benchmark datasets reveals a stark contrast between theory and practice. While node-anchored Subgraph GNNs theoretically offer superior branching decisions, their $O(n)$ complexity overhead results in significant memory bottlenecks and slower solving times than MPNNs and heuristics. Our results indicate that for MILP branching, the computational cost of expressive GNNs currently outweighs their gains in decision quality, suggesting that future research must focus on efficiency-preserving expressivity.
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
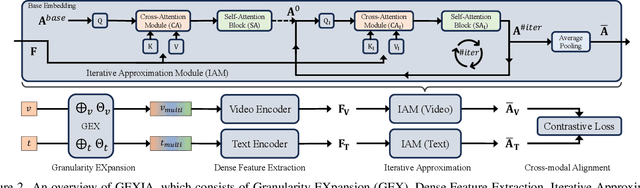
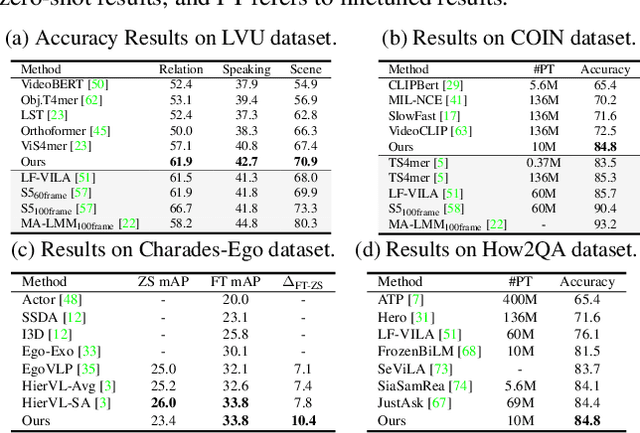
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
DHP Benchmark: Are LLMs Good NLG Evaluators?
Aug 25, 2024Large Language Models (LLMs) are increasingly serving as evaluators in Natural Language Generation (NLG) tasks. However, the capabilities of LLMs in scoring NLG quality remain inadequately explored. Current studies depend on human assessments and simple metrics that fail to capture the discernment of LLMs across diverse NLG tasks. To address this gap, we propose the Discernment of Hierarchical Perturbation (DHP) benchmarking framework, which provides quantitative discernment scores for LLMs utilizing hierarchically perturbed text data and statistical tests to measure the NLG evaluation capabilities of LLMs systematically. We have re-established six evaluation datasets for this benchmark, covering four NLG tasks: Summarization, Story Completion, Question Answering, and Translation. Our comprehensive benchmarking of five major LLM series provides critical insight into their strengths and limitations as NLG evaluators.
CLR-Fact: Evaluating the Complex Logical Reasoning Capability of Large Language Models over Factual Knowledge
Jul 30, 2024



While large language models (LLMs) have demonstrated impressive capabilities across various natural language processing tasks by acquiring rich factual knowledge from their broad training data, their ability to synthesize and logically reason with this knowledge in complex ways remains underexplored. In this work, we present a systematic evaluation of state-of-the-art LLMs' complex logical reasoning abilities through a novel benchmark of automatically generated complex reasoning questions over general domain and biomedical knowledge graphs. Our extensive experiments, employing diverse in-context learning techniques, reveal that LLMs excel at reasoning over general world knowledge but face significant challenges with specialized domain-specific knowledge. We find that prompting with explicit Chain-of-Thought demonstrations can substantially improve LLM performance on complex logical reasoning tasks with diverse logical operations. Interestingly, our controlled evaluations uncover an asymmetry where LLMs display proficiency at set union operations, but struggle considerably with set intersections - a key building block of logical reasoning. To foster further work, we will publicly release our evaluation benchmark and code.
Exclusive Style Removal for Cross Domain Novel Class Discovery
Jun 26, 2024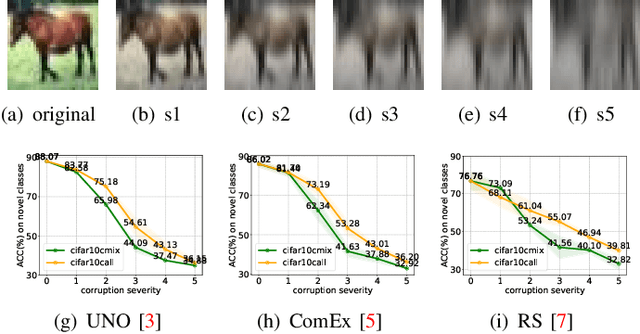
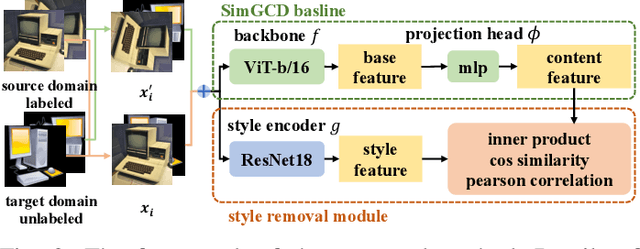
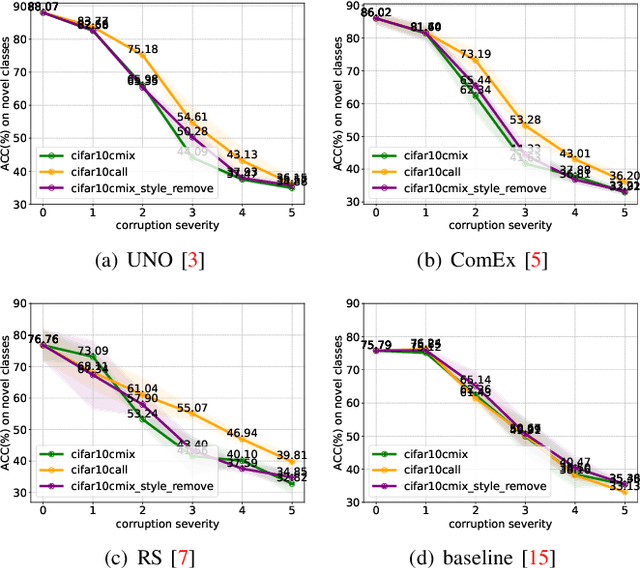

As a promising field in open-world learning, \textit{Novel Class Discovery} (NCD) is usually a task to cluster unseen novel classes in an unlabeled set based on the prior knowledge of labeled data within the same domain. However, the performance of existing NCD methods could be severely compromised when novel classes are sampled from a different distribution with the labeled ones. In this paper, we explore and establish the solvability of NCD in cross domain setting with the necessary condition that style information must be removed. Based on the theoretical analysis, we introduce an exclusive style removal module for extracting style information that is distinctive from the baseline features, thereby facilitating inference. Moreover, this module is easy to integrate with other NCD methods, acting as a plug-in to improve performance on novel classes with different distributions compared to the seen labeled set. Additionally, recognizing the non-negligible influence of different backbones and pre-training strategies on the performance of the NCD methods, we build a fair benchmark for future NCD research. Extensive experiments on three common datasets demonstrate the effectiveness of our proposed module.
FairLENS: Assessing Fairness in Law Enforcement Speech Recognition
May 21, 2024Automatic speech recognition (ASR) techniques have become powerful tools, enhancing efficiency in law enforcement scenarios. To ensure fairness for demographic groups in different acoustic environments, ASR engines must be tested across a variety of speakers in realistic settings. However, describing the fairness discrepancies between models with confidence remains a challenge. Meanwhile, most public ASR datasets are insufficient to perform a satisfying fairness evaluation. To address the limitations, we built FairLENS - a systematic fairness evaluation framework. We propose a novel and adaptable evaluation method to examine the fairness disparity between different models. We also collected a fairness evaluation dataset covering multiple scenarios and demographic dimensions. Leveraging this framework, we conducted fairness assessments on 1 open-source and 11 commercially available state-of-the-art ASR models. Our results reveal that certain models exhibit more biases than others, serving as a fairness guideline for users to make informed choices when selecting ASR models for a given real-world scenario. We further explored model biases towards specific demographic groups and observed that shifts in the acoustic domain can lead to the emergence of new biases.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Stabilizing Sharpness-aware Minimization Through A Simple Renormalization Strategy
Jan 14, 2024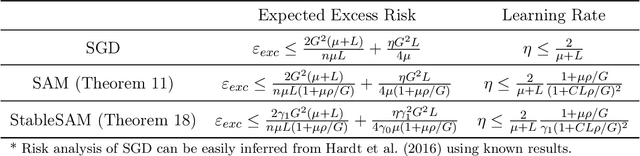
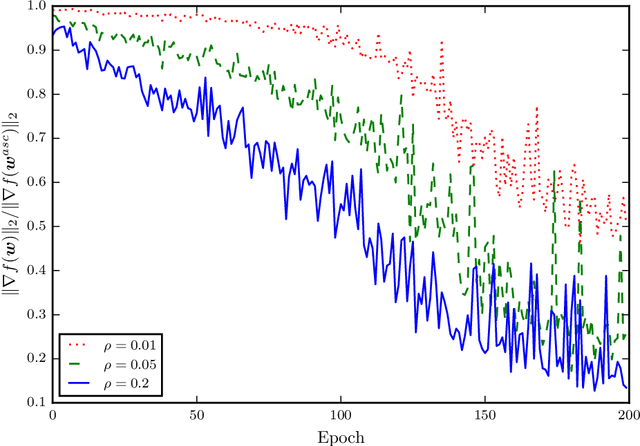
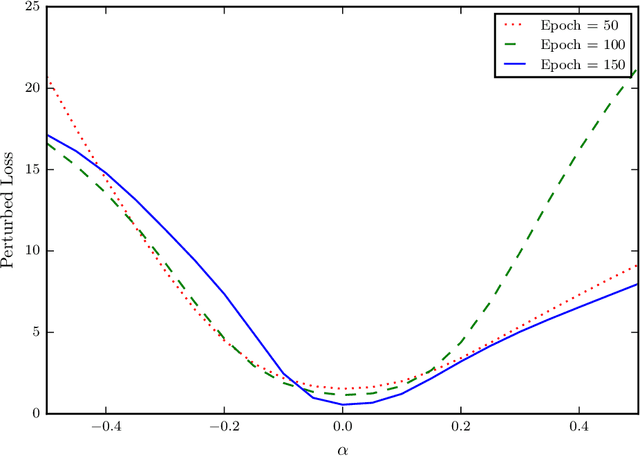
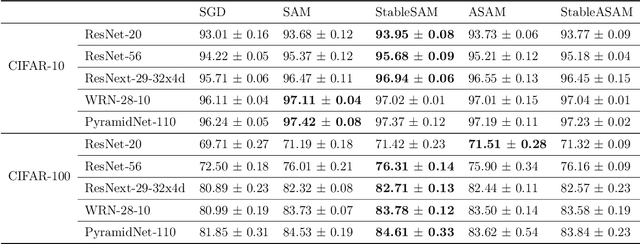
Recently, sharpness-aware minimization (SAM) has attracted a lot of attention because of its surprising effectiveness in improving generalization performance.However, training neural networks with SAM can be highly unstable since the loss does not decrease along the direction of the exact gradient at the current point, but instead follows the direction of a surrogate gradient evaluated at another point nearby. To address this issue, we propose a simple renormalization strategy, dubbed StableSAM, so that the norm of the surrogate gradient maintains the same as that of the exact gradient. Our strategy is easy to implement and flexible enough to integrate with SAM and its variants, almost at no computational cost. With elementary tools from convex optimization and learning theory, we also conduct a theoretical analysis of sharpness-aware training, revealing that compared to stochastic gradient descent (SGD), the effectiveness of SAM is only assured in a limited regime of learning rate. In contrast, we show how StableSAM extends this regime of learning rate and when it can consistently perform better than SAM with minor modification. Finally, we demonstrate the improved performance of StableSAM on several representative data sets and tasks.