 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Entropy Regularization for Multi-modal Antenna Affiliation Identification
Jan 29, 2026Accurate antenna affiliation identification is crucial for optimizing and maintaining communication networks. Current practice, however, relies on the cumbersome and error-prone process of manual tower inspections. We propose a novel paradigm shift that fuses video footage of base stations, antenna geometric features, and Physical Cell Identity (PCI) signals, transforming antenna affiliation identification into multi-modal classification and matching tasks. Publicly available pretrained transformers struggle with this unique task due to a lack of analogous data in the communications domain, which hampers cross-modal alignment. To address this, we introduce a dedicated training framework that aligns antenna images with corresponding PCI signals. To tackle the representation alignment challenge, we propose a novel Token Entropy Regularization module in the pretraining stage. Our experiments demonstrate that TER accelerates convergence and yields significant performance gains. Further analysis reveals that the entropy of the first token is modality-dependent. Code will be made available upon publication.
NowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024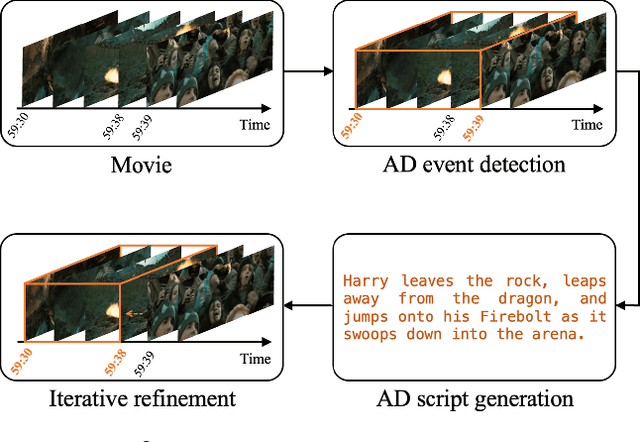
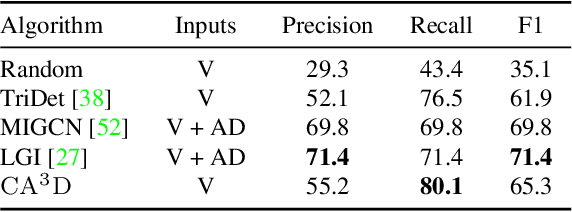
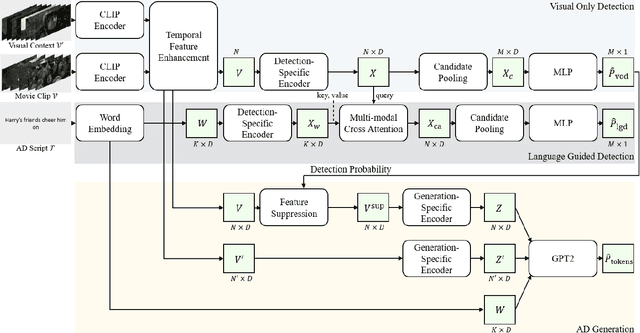

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
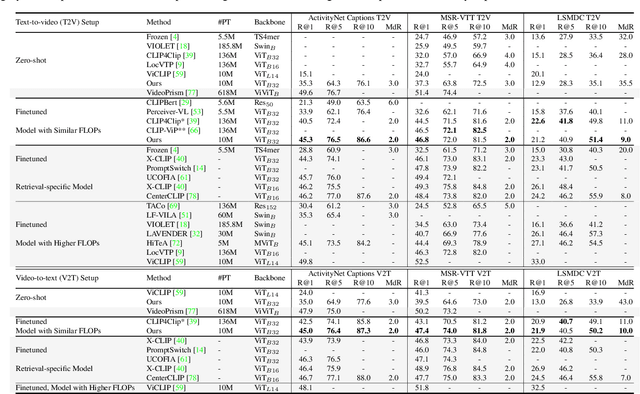
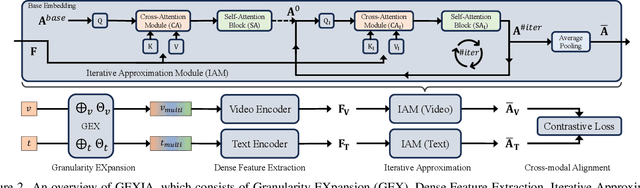
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
Video Token Merging for Long-form Video Understanding
Oct 31, 2024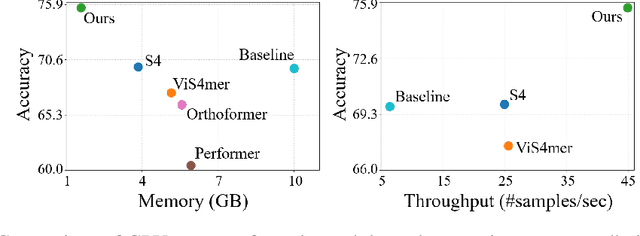
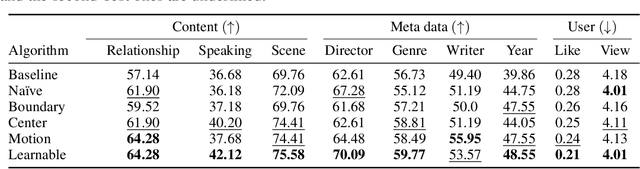
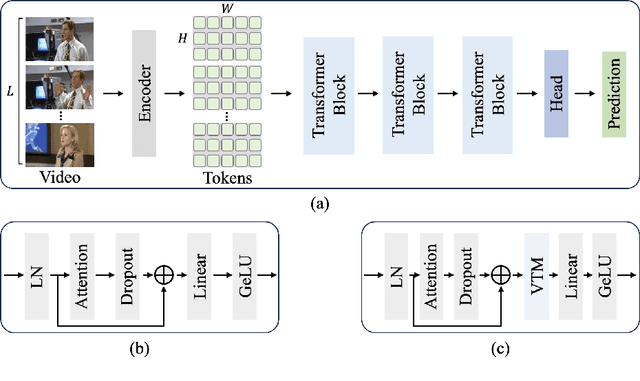
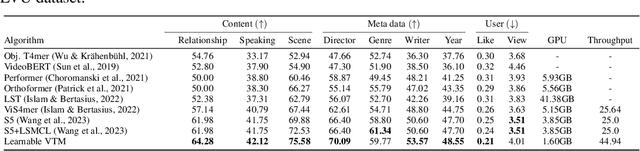
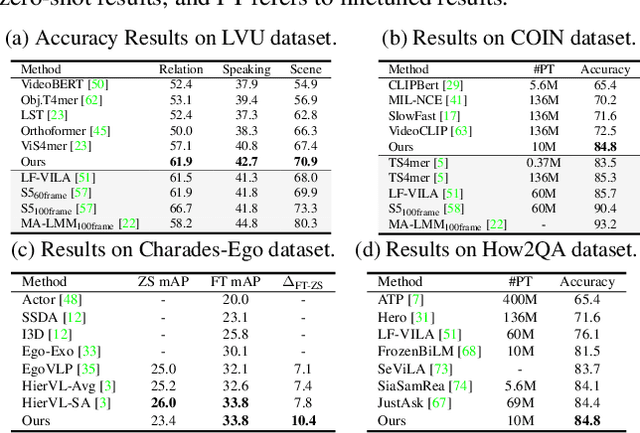
As the scale of data and models for video understanding rapidly expand, handling long-form video input in transformer-based models presents a practical challenge. Rather than resorting to input sampling or token dropping, which may result in information loss, token merging shows promising results when used in collaboration with transformers. However, the application of token merging for long-form video processing is not trivial. We begin with the premise that token merging should not rely solely on the similarity of video tokens; the saliency of tokens should also be considered. To address this, we explore various video token merging strategies for long-form video classification, starting with a simple extension of image token merging, moving to region-concentrated merging, and finally proposing a learnable video token merging (VTM) algorithm that dynamically merges tokens based on their saliency. Extensive experimental results show that we achieve better or comparable performances on the LVU, COIN, and Breakfast datasets. Moreover, our approach significantly reduces memory costs by 84% and boosts throughput by approximately 6.89 times compared to baseline algorithms.
* 21 pages, NeurIPS 2024
Text-Guided Video Masked Autoencoder
Aug 01, 2024



Recent video masked autoencoder (MAE) works have designed improved masking algorithms focused on saliency. These works leverage visual cues such as motion to mask the most salient regions. However, the robustness of such visual cues depends on how often input videos match underlying assumptions. On the other hand, natural language description is an information dense representation of video that implicitly captures saliency without requiring modality-specific assumptions, and has not been explored yet for video MAE. To this end, we introduce a novel text-guided masking algorithm (TGM) that masks the video regions with highest correspondence to paired captions. Without leveraging any explicit visual cues for saliency, our TGM is competitive with state-of-the-art masking algorithms such as motion-guided masking. To further benefit from the semantics of natural language for masked reconstruction, we next introduce a unified framework for joint MAE and masked video-text contrastive learning. We show that across existing masking algorithms, unifying MAE and masked video-text contrastive learning improves downstream performance compared to pure MAE on a variety of video recognition tasks, especially for linear probe. Within this unified framework, our TGM achieves the best relative performance on five action recognition and one egocentric datasets, highlighting the complementary nature of natural language for masked video modeling.
TransUPR: A Transformer-based Uncertain Point Refiner for LiDAR Point Cloud Semantic Segmentation
Feb 20, 2023



In this work, we target the problem of uncertain points refinement for image-based LiDAR point cloud semantic segmentation (LiDAR PCSS). This problem mainly results from the boundary-blurring problem of convolution neural networks (CNNs) and quantitation loss of spherical projection, which are often hard to avoid for common image-based LiDAR PCSS approaches. We propose a plug-and-play transformer-based uncertain point refiner (TransUPR) to address the problem. Through local feature aggregation, uncertain point localization, and self-attention-based transformer design, TransUPR, integrated into an existing range image-based LiDAR PCSS approach (e.g., CENet), achieves the state-of-the-art performance (68.2% mIoU) on Semantic-KITTI benchmark, which provides a performance improvement of 0.6% on the mIoU.
Enhanced Low-resolution LiDAR-Camera Calibration Via Depth Interpolation and Supervised Contrastive Learning
Nov 08, 2022



Motivated by the increasing application of low-resolution LiDAR recently, we target the problem of low-resolution LiDAR-camera calibration in this work. The main challenges are two-fold: sparsity and noise in point clouds. To address the problem, we propose to apply depth interpolation to increase the point density and supervised contrastive learning to learn noise-resistant features. The experiments on RELLIS-3D demonstrate that our approach achieves an average mean absolute rotation/translation errors of 0.15cm/0.33\textdegree on 32-channel LiDAR point cloud data, which significantly outperforms all reference methods.
Automatic Error Detection in Integrated Circuits Image Segmentation: A Data-driven Approach
Nov 08, 2022
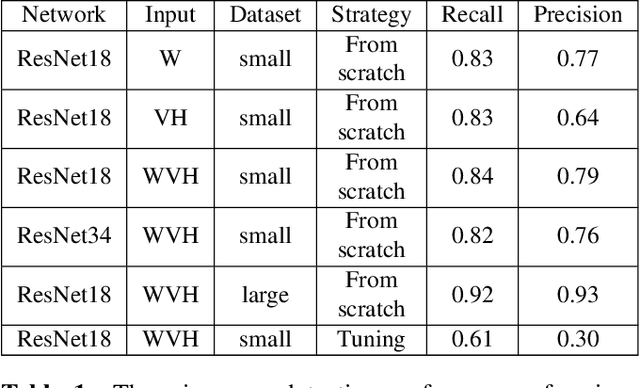
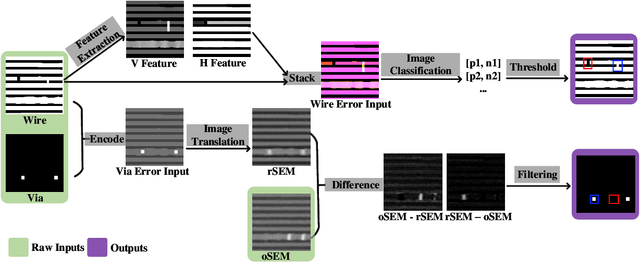

Due to the complicated nanoscale structures of current integrated circuits(IC) builds and low error tolerance of IC image segmentation tasks, most existing automated IC image segmentation approaches require human experts for visual inspection to ensure correctness, which is one of the major bottlenecks in large-scale industrial applications. In this paper, we present the first data-driven automatic error detection approach targeting two types of IC segmentation errors: wire errors and via errors. On an IC image dataset collected from real industry, we demonstrate that, by adapting existing CNN-based approaches of image classification and image translation with additional pre-processing and post-processing techniques, we are able to achieve recall/precision of 0.92/0.93 in wire error detection and 0.96/0.90 in via error detection, respectively.
OpenICS: Open Image Compressive Sensing Toolbox and Benchmark
Mar 04, 2021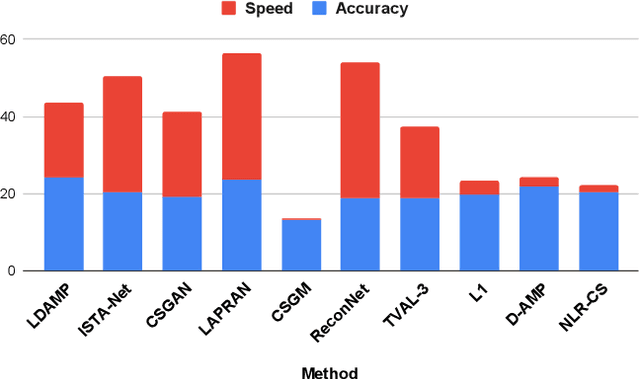


We present OpenICS, an image compressive sensing toolbox that includes multiple image compressive sensing and reconstruction algorithms proposed in the past decade. Due to the lack of standardization in the implementation and evaluation of the proposed algorithms, the application of image compressive sensing in the real-world is limited. We believe this toolbox is the first framework that provides a unified and standardized implementation of multiple image compressive sensing algorithms. In addition, we also conduct a benchmarking study on the methods included in this framework from two aspects: reconstruction accuracy and reconstruction efficiency. We wish this toolbox and benchmark can serve the growing research community of compressive sensing and the industry applying image compressive sensing to new problems as well as developing new methods more efficiently. Code and models are available at https://github.com/PSCLab-ASU/OpenICS. The project is still under maintenance, and we will keep this document updated.
LAPRAN: A Scalable Laplacian Pyramid Reconstructive Adversarial Network for Flexible Compressive Sensing Reconstruction
Nov 03, 2018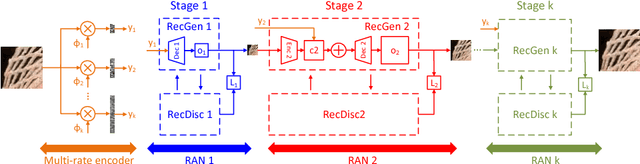

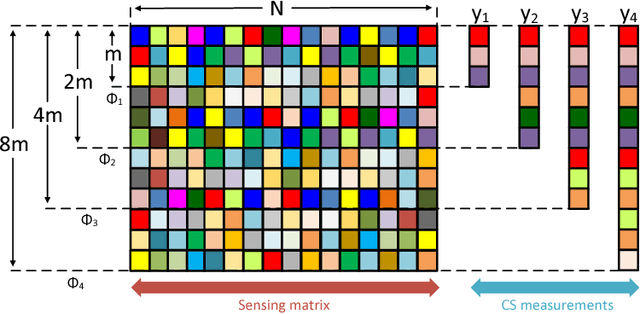
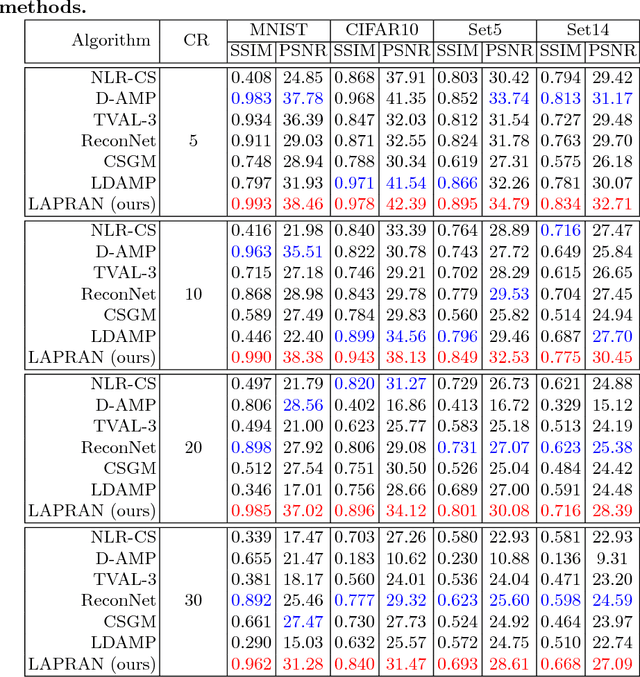
This paper addresses the single-image compressive sensing (CS) and reconstruction problem. We propose a scalable Laplacian pyramid reconstructive adversarial network (LAPRAN) that enables high-fidelity, flexible and fast CS images reconstruction. LAPRAN progressively reconstructs an image following the concept of Laplacian pyramid through multiple stages of reconstructive adversarial networks (RANs). At each pyramid level, CS measurements are fused with a contextual latent vector to generate a high-frequency image residual. Consequently, LAPRAN can produce hierarchies of reconstructed images and each with an incremental resolution and improved quality. The scalable pyramid structure of LAPRAN enables high-fidelity CS reconstruction with a flexible resolution that is adaptive to a wide range of compression ratios (CRs), which is infeasible with existing methods. Experimental results on multiple public datasets show that LAPRAN offers an average 7.47dB and 5.98dB PSNR, and an average 57.93% and 33.20% SSIM improvement compared to model-based and data-driven baselines, respectively.