 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Paper and Code
Dec 10, 2024
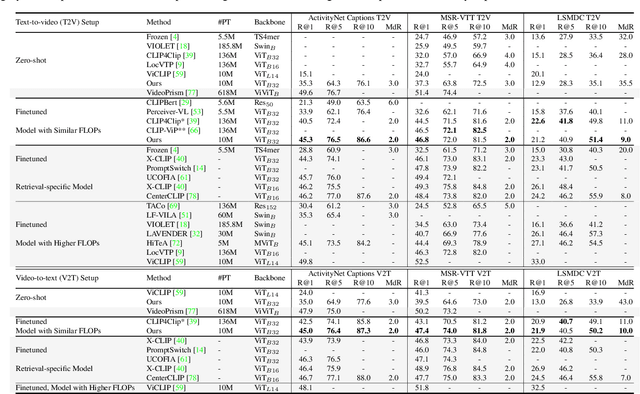
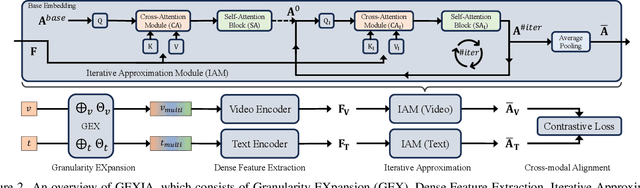
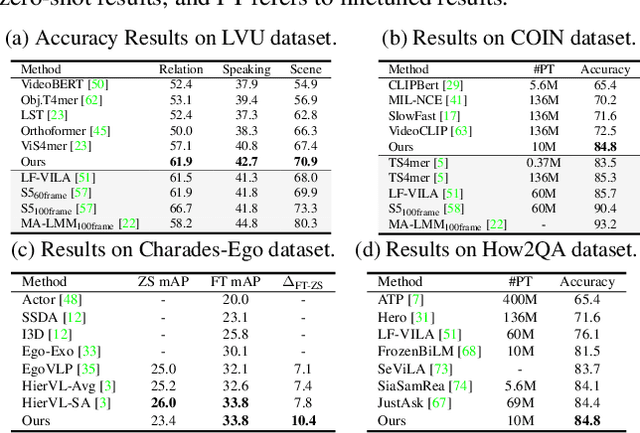
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.