 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
NowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024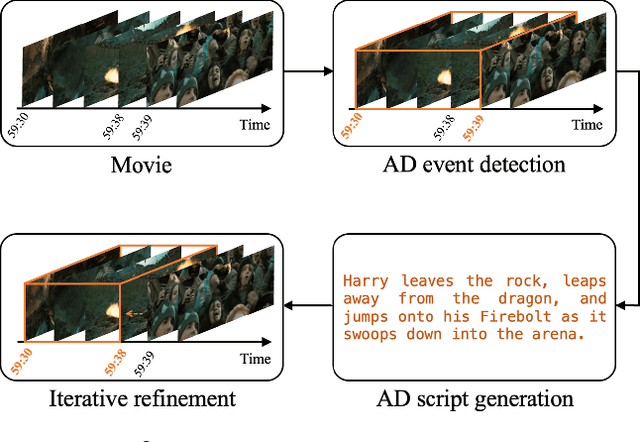
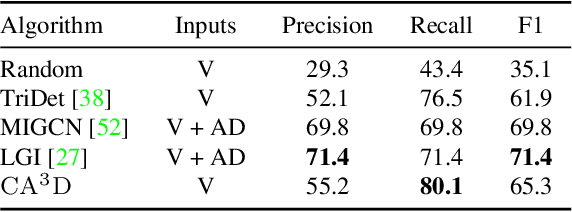
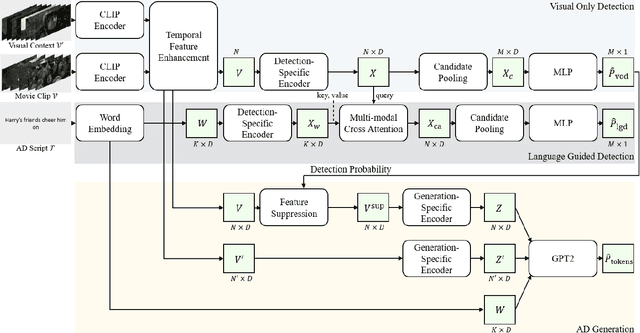

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
GEXIA: Granularity Expansion and Iterative Approximation for Scalable Multi-grained Video-language Learning
Dec 10, 2024
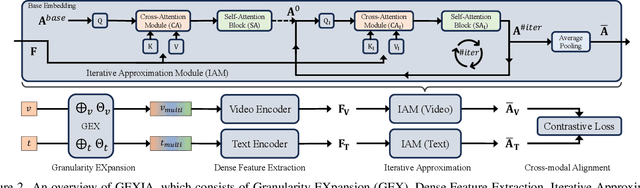
In various video-language learning tasks, the challenge of achieving cross-modality alignment with multi-grained data persists. We propose a method to tackle this challenge from two crucial perspectives: data and modeling. Given the absence of a multi-grained video-text pretraining dataset, we introduce a Granularity EXpansion (GEX) method with Integration and Compression operations to expand the granularity of a single-grained dataset. To better model multi-grained data, we introduce an Iterative Approximation Module (IAM), which embeds multi-grained videos and texts into a unified, low-dimensional semantic space while preserving essential information for cross-modal alignment. Furthermore, GEXIA is highly scalable with no restrictions on the number of video-text granularities for alignment. We evaluate our work on three categories of video tasks across seven benchmark datasets, showcasing state-of-the-art or comparable performance. Remarkably, our model excels in tasks involving long-form video understanding, even though the pretraining dataset only contains short video clips.
Augment the Pairs: Semantics-Preserving Image-Caption Pair Augmentation for Grounding-Based Vision and Language Models
Nov 05, 2023Grounding-based vision and language models have been successfully applied to low-level vision tasks, aiming to precisely locate objects referred in captions. The effectiveness of grounding representation learning heavily relies on the scale of the training dataset. Despite being a useful data enrichment strategy, data augmentation has received minimal attention in existing vision and language tasks as augmentation for image-caption pairs is non-trivial. In this study, we propose a robust phrase grounding model trained with text-conditioned and text-unconditioned data augmentations. Specifically, we apply text-conditioned color jittering and horizontal flipping to ensure semantic consistency between images and captions. To guarantee image-caption correspondence in the training samples, we modify the captions according to pre-defined keywords when applying horizontal flipping. Additionally, inspired by recent masked signal reconstruction, we propose to use pixel-level masking as a novel form of data augmentation. While we demonstrate our data augmentation method with MDETR framework, the proposed approach is applicable to common grounding-based vision and language tasks with other frameworks. Finally, we show that image encoder pretrained on large-scale image and language datasets (such as CLIP) can further improve the results. Through extensive experiments on three commonly applied datasets: Flickr30k, referring expressions and GQA, our method demonstrates advanced performance over the state-of-the-arts with various metrics. Code can be found in https://github.com/amzn/augment-the-pairs-wacv2024.
Selective Structured State-Spaces for Long-Form Video Understanding
Mar 25, 2023
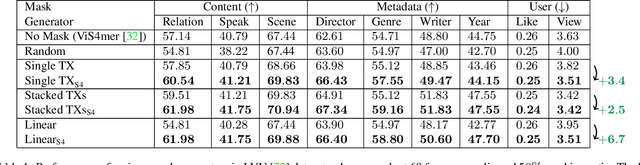
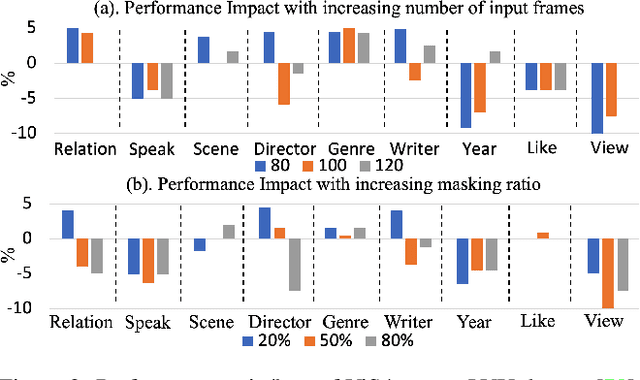
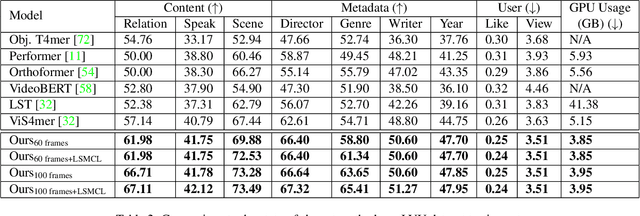
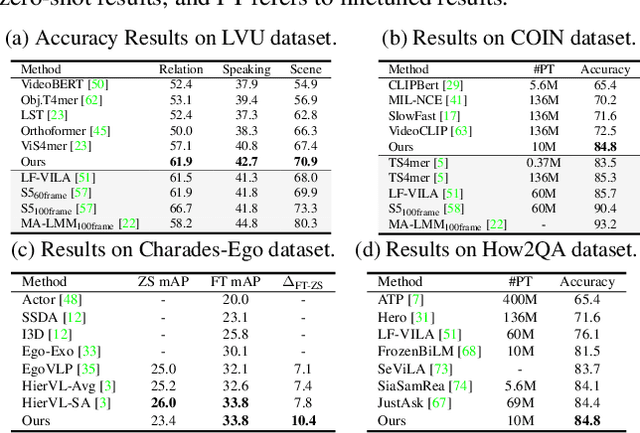
Effective modeling of complex spatiotemporal dependencies in long-form videos remains an open problem. The recently proposed Structured State-Space Sequence (S4) model with its linear complexity offers a promising direction in this space. However, we demonstrate that treating all image-tokens equally as done by S4 model can adversely affect its efficiency and accuracy. To address this limitation, we present a novel Selective S4 (i.e., S5) model that employs a lightweight mask generator to adaptively select informative image tokens resulting in more efficient and accurate modeling of long-term spatiotemporal dependencies in videos. Unlike previous mask-based token reduction methods used in transformers, our S5 model avoids the dense self-attention calculation by making use of the guidance of the momentum-updated S4 model. This enables our model to efficiently discard less informative tokens and adapt to various long-form video understanding tasks more effectively. However, as is the case for most token reduction methods, the informative image tokens could be dropped incorrectly. To improve the robustness and the temporal horizon of our model, we propose a novel long-short masked contrastive learning (LSMCL) approach that enables our model to predict longer temporal context using shorter input videos. We present extensive comparative results using three challenging long-form video understanding datasets (LVU, COIN and Breakfast), demonstrating that our approach consistently outperforms the previous state-of-the-art S4 model by up to 9.6% accuracy while reducing its memory footprint by 23%.
Mitigating Closed-model Adversarial Examples with Bayesian Neural Modeling for Enhanced End-to-End Speech Recognition
Feb 17, 2022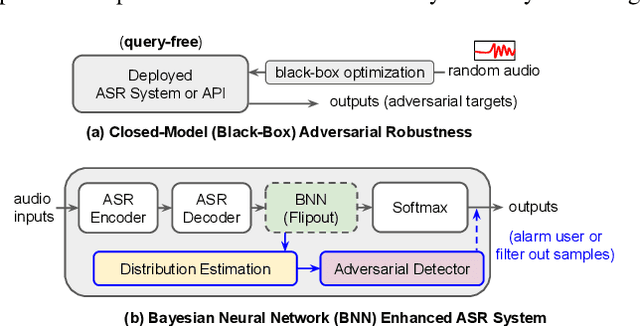

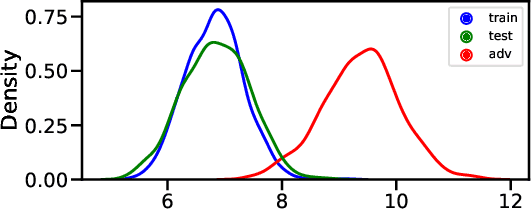
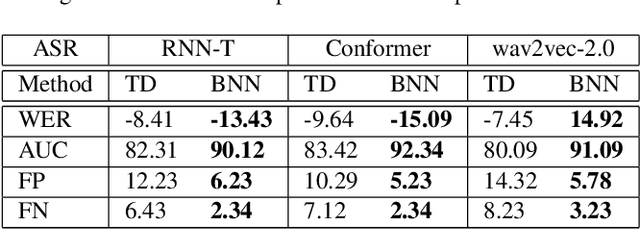
In this work, we aim to enhance the system robustness of end-to-end automatic speech recognition (ASR) against adversarially-noisy speech examples. We focus on a rigorous and empirical "closed-model adversarial robustness" setting (e.g., on-device or cloud applications). The adversarial noise is only generated by closed-model optimization (e.g., evolutionary and zeroth-order estimation) without accessing gradient information of a targeted ASR model directly. We propose an advanced Bayesian neural network (BNN) based adversarial detector, which could model latent distributions against adaptive adversarial perturbation with divergence measurement. We further simulate deployment scenarios of RNN Transducer, Conformer, and wav2vec-2.0 based ASR systems with the proposed adversarial detection system. Leveraging the proposed BNN based detection system, we improve detection rate by +2.77 to +5.42% (relative +3.03 to +6.26%) and reduce the word error rate by 5.02 to 7.47% on LibriSpeech datasets compared to the current model enhancement methods against the adversarial speech examples.
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021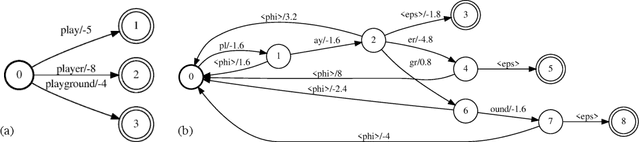
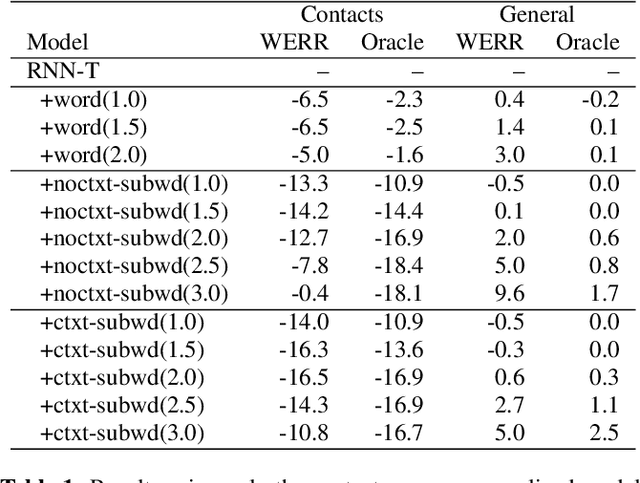
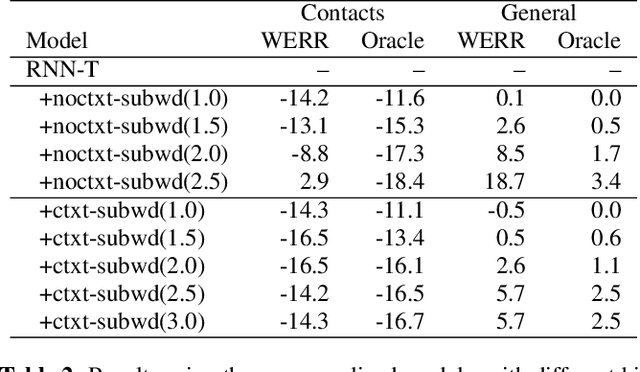
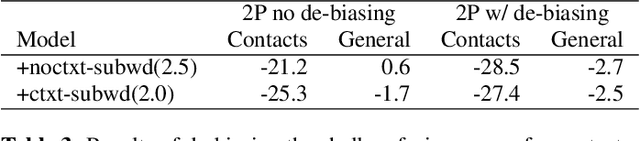
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Domain-aware Neural Language Models for Speech Recognition
Jan 05, 2021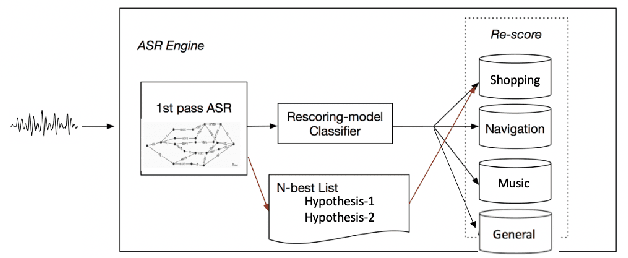
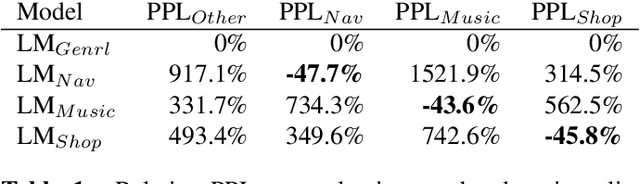

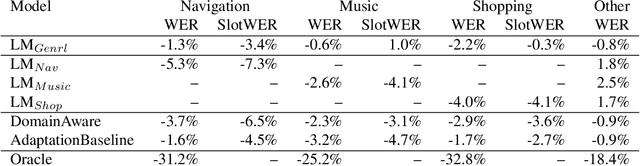
As voice assistants become more ubiquitous, they are increasingly expected to support and perform well on a wide variety of use-cases across different domains. We present a domain-aware rescoring framework suitable for achieving domain-adaptation during second-pass rescoring in production settings. In our framework, we fine-tune a domain-general neural language model on several domains, and use an LSTM-based domain classification model to select the appropriate domain-adapted model to use for second-pass rescoring. This domain-aware rescoring improves the word error rate by up to 2.4% and slot word error rate by up to 4.1% on three individual domains -- shopping, navigation, and music -- compared to domain general rescoring. These improvements are obtained while maintaining accuracy for the general use case.
Improving accuracy of rare words for RNN-Transducer through unigram shallow fusion
Nov 30, 2020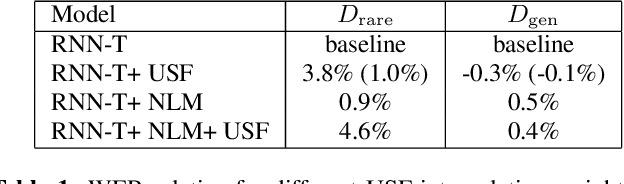

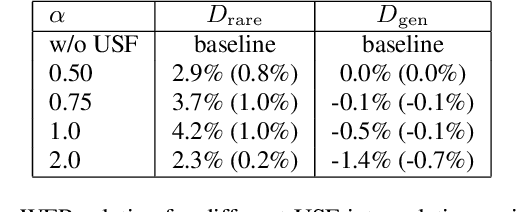
End-to-end automatic speech recognition (ASR) systems, such as recurrent neural network transducer (RNN-T), have become popular, but rare word remains a challenge. In this paper, we propose a simple, yet effective method called unigram shallow fusion (USF) to improve rare words for RNN-T. In USF, we extract rare words from RNN-T training data based on unigram count, and apply a fixed reward when the word is encountered during decoding. We show that this simple method can improve performance on rare words by 3.7% WER relative without degradation on general test set, and the improvement from USF is additive to any additional language model based rescoring. Then, we show that the same USF does not work on conventional hybrid system. Finally, we reason that USF works by fixing errors in probability estimates of words due to Viterbi search used during decoding with subword-based RNN-T.
Multi-task Language Modeling for Improving Speech Recognition of Rare Words
Nov 25, 2020

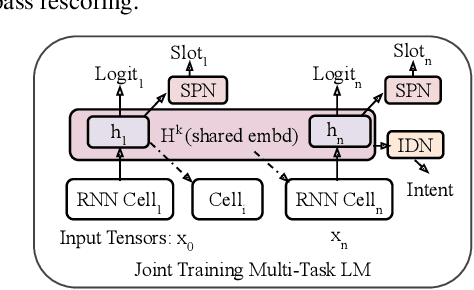
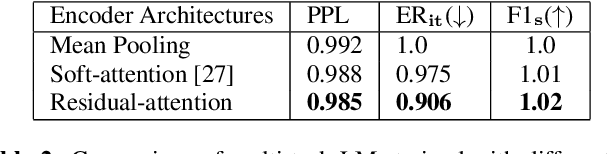
End-to-end automatic speech recognition (ASR) systems are increasingly popular due to their relative architectural simplicity and competitive performance. However, even though the average accuracy of these systems may be high, the performance on rare content words often lags behind hybrid ASR systems. To address this problem, second-pass rescoring is often applied. In this paper, we propose a second-pass system with multi-task learning, utilizing semantic targets (such as intent and slot prediction) to improve speech recognition performance. We show that our rescoring model with trained with these additional tasks outperforms the baseline rescoring model, trained with only the language modeling task, by 1.4% on a general test and by 2.6% on a rare word test set in term of word-error-rate relative (WERR).