 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons from the Field: An Adaptable Lifecycle Approach to Applied Dialogue Summarization
Jan 13, 2026Summarization of multi-party dialogues is a critical capability in industry, enhancing knowledge transfer and operational effectiveness across many domains. However, automatically generating high-quality summaries is challenging, as the ideal summary must satisfy a set of complex, multi-faceted requirements. While summarization has received immense attention in research, prior work has primarily utilized static datasets and benchmarks, a condition rare in practical scenarios where requirements inevitably evolve. In this work, we present an industry case study on developing an agentic system to summarize multi-party interactions. We share practical insights spanning the full development lifecycle to guide practitioners in building reliable, adaptable summarization systems, as well as to inform future research, covering: 1) robust methods for evaluation despite evolving requirements and task subjectivity, 2) component-wise optimization enabled by the task decomposition inherent in an agentic architecture, 3) the impact of upstream data bottlenecks, and 4) the realities of vendor lock-in due to the poor transferability of LLM prompts.
CUE Vectors: Modular Training of Language Models Conditioned on Diverse Contextual Signals
Mar 16, 2022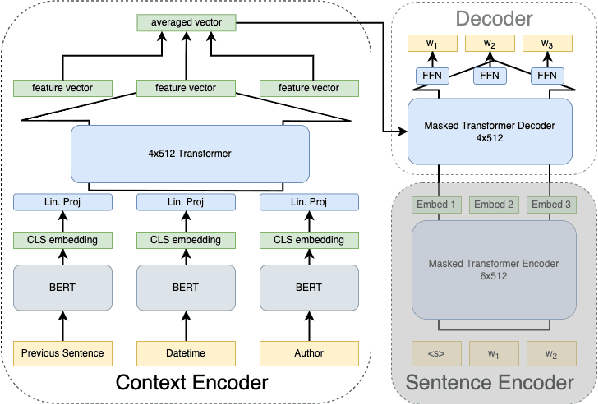
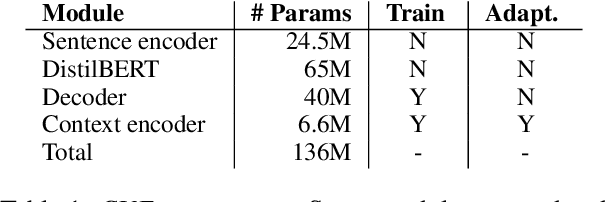

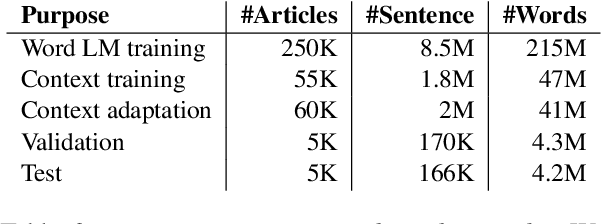
We propose a framework to modularize the training of neural language models that use diverse forms of sentence-external context (including metadata) by eliminating the need to jointly train sentence-external and within-sentence encoders. Our approach, contextual universal embeddings (CUE), trains LMs on one set of context, such as date and author, and adapts to novel metadata types, such as article title, or previous sentence. The model consists of a pretrained neural sentence LM, a BERT-based context encoder, and a masked transformer decoder that estimates LM probabilities using sentence-internal and sentence-external information. When context or metadata are unavailable, our model learns to combine contextual and sentence-internal information using noisy oracle unigram embeddings as a proxy. Real contextual information can be introduced later and used to adapt a small number of parameters that map contextual data into the decoder's embedding space. We validate the CUE framework on a NYTimes text corpus with multiple metadata types, for which the LM perplexity can be lowered from 36.6 to 27.4 by conditioning on context. Bootstrapping a contextual LM with only a subset of the context/metadata during training retains 85\% of the achievable gain. Training the model initially with proxy context retains 67% of the perplexity gain after adapting to real context. Furthermore, we can swap one type of pretrained sentence LM for another without retraining the context encoders, by only adapting the decoder model. Overall, we obtain a modular framework that allows incremental, scalable training of context-enhanced LMs.
Attention-based Contextual Language Model Adaptation for Speech Recognition
Jun 02, 2021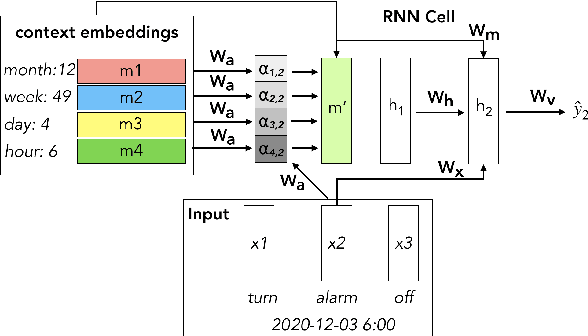
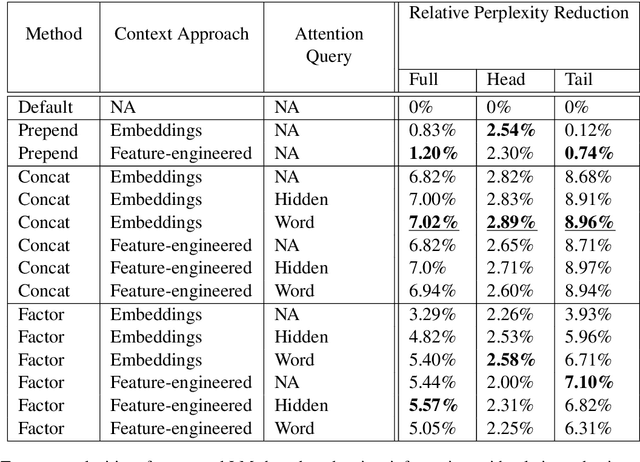
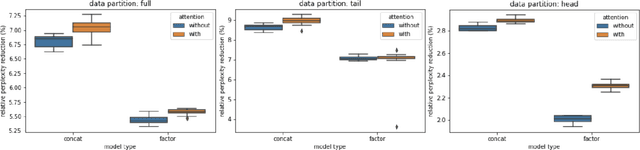
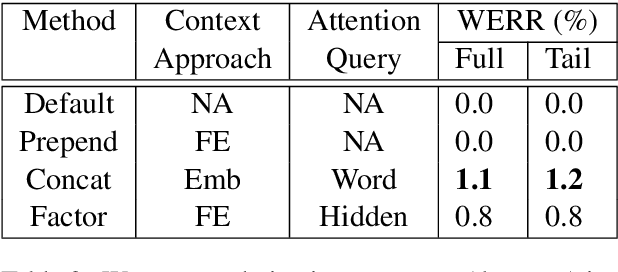
Language modeling (LM) for automatic speech recognition (ASR) does not usually incorporate utterance level contextual information. For some domains like voice assistants, however, additional context, such as the time at which an utterance was spoken, provides a rich input signal. We introduce an attention mechanism for training neural speech recognition language models on both text and non-linguistic contextual data. When applied to a large de-identified dataset of utterances collected by a popular voice assistant platform, our method reduces perplexity by 7.0% relative over a standard LM that does not incorporate contextual information. When evaluated on utterances extracted from the long tail of the dataset, our method improves perplexity by 9.0% relative over a standard LM and by over 2.8% relative when compared to a state-of-the-art model for contextual LM.
Improving accuracy of rare words for RNN-Transducer through unigram shallow fusion
Nov 30, 2020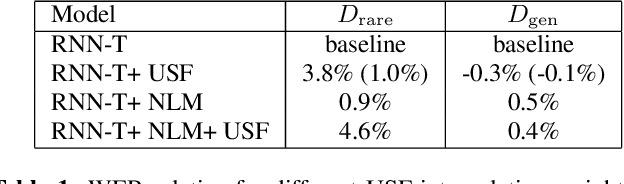

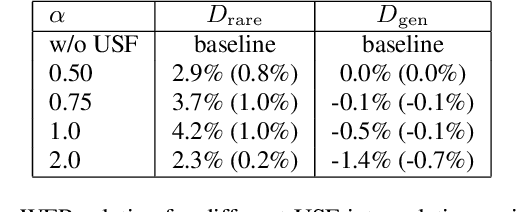
End-to-end automatic speech recognition (ASR) systems, such as recurrent neural network transducer (RNN-T), have become popular, but rare word remains a challenge. In this paper, we propose a simple, yet effective method called unigram shallow fusion (USF) to improve rare words for RNN-T. In USF, we extract rare words from RNN-T training data based on unigram count, and apply a fixed reward when the word is encountered during decoding. We show that this simple method can improve performance on rare words by 3.7% WER relative without degradation on general test set, and the improvement from USF is additive to any additional language model based rescoring. Then, we show that the same USF does not work on conventional hybrid system. Finally, we reason that USF works by fixing errors in probability estimates of words due to Viterbi search used during decoding with subword-based RNN-T.