 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Scheduling for LLM Inference
Jun 13, 2025Conventional operating system scheduling algorithms are largely content-ignorant, making decisions based on factors such as latency or fairness without considering the actual intents or semantics of processes. Consequently, these algorithms often do not prioritize tasks that require urgent attention or carry higher importance, such as in emergency management scenarios. However, recent advances in language models enable semantic analysis of processes, allowing for more intelligent and context-aware scheduling decisions. In this paper, we introduce the concept of semantic scheduling in scheduling of requests from large language models (LLM), where the semantics of the process guide the scheduling priorities. We present a novel scheduling algorithm with optimal time complexity, designed to minimize the overall waiting time in LLM-based prompt scheduling. To illustrate its effectiveness, we present a medical emergency management application, underscoring the potential benefits of semantic scheduling for critical, time-sensitive tasks. The code and data are available at https://github.com/Wenyueh/latency_optimization_with_priority_constraints.
TeleRAG: Efficient Retrieval-Augmented Generation Inference with Lookahead Retrieval
Feb 28, 2025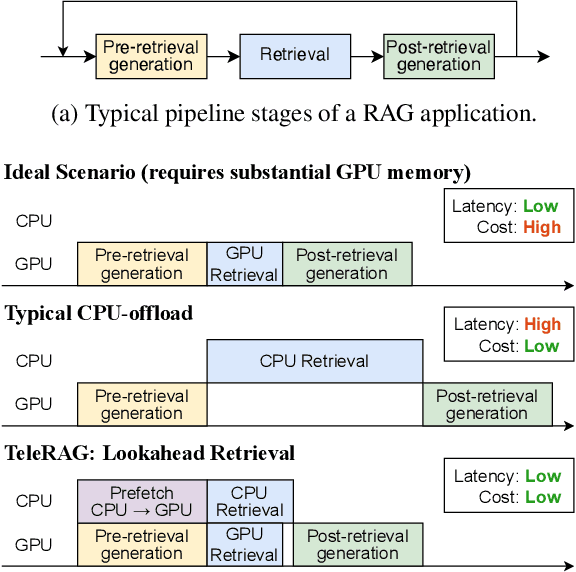



Retrieval-augmented generation (RAG) extends large language models (LLMs) with external data sources to enhance factual correctness and domain coverage. Modern RAG pipelines rely on large datastores, leading to system challenges in latency-sensitive deployments, especially when limited GPU memory is available. To address these challenges, we propose TeleRAG, an efficient inference system that reduces RAG latency with minimal GPU memory requirements. The core innovation of TeleRAG is lookahead retrieval, a prefetching mechanism that anticipates required data and transfers it from CPU to GPU in parallel with LLM generation. By leveraging the modularity of RAG pipelines, the inverted file index (IVF) search algorithm and similarities between queries, TeleRAG optimally overlaps data movement and computation. Experimental results show that TeleRAG reduces end-to-end RAG inference latency by up to 1.72x on average compared to state-of-the-art systems, enabling faster, more memory-efficient deployments of advanced RAG applications.
Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context LLMs
Feb 17, 2025Long-context models are essential for many applications but face inefficiencies in loading large KV caches during decoding. Prior methods enforce fixed token budgets for sparse attention, assuming a set number of tokens can approximate full attention. However, these methods overlook variations in the importance of attention across heads, layers, and contexts. To address these limitations, we propose Tactic, a sparsity-adaptive and calibration-free sparse attention mechanism that dynamically selects tokens based on their cumulative attention scores rather than a fixed token budget. By setting a target fraction of total attention scores, Tactic ensures that token selection naturally adapts to variations in attention sparsity. To efficiently approximate this selection, Tactic leverages clustering-based sorting and distribution fitting, allowing it to accurately estimate token importance with minimal computational overhead. We show that Tactic outperforms existing sparse attention algorithms, achieving superior accuracy and up to 7.29x decode attention speedup. This improvement translates to an overall 1.58x end-to-end inference speedup, making Tactic a practical and effective solution for long-context LLM inference in accuracy-sensitive applications.
Argos: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
Jan 24, 2025



Observability in cloud infrastructure is critical for service providers, driving the widespread adoption of anomaly detection systems for monitoring metrics. However, existing systems often struggle to simultaneously achieve explainability, reproducibility, and autonomy, which are three indispensable properties for production use. We introduce Argos, an agentic system for detecting time-series anomalies in cloud infrastructure by leveraging large language models (LLMs). Argos proposes to use explainable and reproducible anomaly rules as intermediate representation and employs LLMs to autonomously generate such rules. The system will efficiently train error-free and accuracy-guaranteed anomaly rules through multiple collaborative agents and deploy the trained rules for low-cost online anomaly detection. Through evaluation results, we demonstrate that Argos outperforms state-of-the-art methods, increasing $F_1$ scores by up to $9.5\%$ and $28.3\%$ on public anomaly detection datasets and an internal dataset collected from Microsoft, respectively.
Align-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback
Nov 04, 2024



While textless Spoken Language Models (SLMs) have shown potential in end-to-end speech-to-speech modeling, they still lag behind text-based Large Language Models (LLMs) in terms of semantic coherence and relevance. This work introduces the Align-SLM framework, which leverages preference optimization inspired by Reinforcement Learning with AI Feedback (RLAIF) to enhance the semantic understanding of SLMs. Our approach generates multiple speech continuations from a given prompt and uses semantic metrics to create preference data for Direct Preference Optimization (DPO). We evaluate the framework using ZeroSpeech 2021 benchmarks for lexical and syntactic modeling, the spoken version of the StoryCloze dataset for semantic coherence, and other speech generation metrics, including the GPT4-o score and human evaluation. Experimental results show that our method achieves state-of-the-art performance for SLMs on most benchmarks, highlighting the importance of preference optimization to improve the semantics of SLMs.
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jun 13, 2024



Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
Feb 10, 2024Large Language Models (LLMs) based on Mixture-of-Experts (MoE) architecture are showing promising performance on various tasks. However, running them on resource-constrained settings, where GPU memory resources are not abundant, is challenging due to huge model sizes. Existing systems that offload model weights to CPU memory suffer from the significant overhead of frequently moving data between CPU and GPU. In this paper, we propose Fiddler, a resource-efficient inference engine with CPU-GPU orchestration for MoE models. The key idea of Fiddler is to use the computation ability of the CPU to minimize the data movement between the CPU and GPU. Our evaluation shows that Fiddler can run the uncompressed Mixtral-8x7B model, which exceeds 90GB in parameters, to generate over $3$ tokens per second on a single GPU with 24GB memory, showing an order of magnitude improvement over existing methods. The code of Fiddler is publicly available at \url{https://github.com/efeslab/fiddler}
Paralinguistics-Enhanced Large Language Modeling of Spoken Dialogue
Jan 17, 2024Large Language Models (LLMs) have demonstrated superior abilities in tasks such as chatting, reasoning, and question-answering. However, standard LLMs may ignore crucial paralinguistic information, such as sentiment, emotion, and speaking style, which are essential for achieving natural, human-like spoken conversation, especially when such information is conveyed by acoustic cues. We therefore propose Paralinguistics-enhanced Generative Pretrained Transformer (ParalinGPT), an LLM that utilizes text and speech modalities to better model the linguistic content and paralinguistic attributes of spoken dialogue. The model takes the conversational context of text, speech embeddings, and paralinguistic attributes as input prompts within a serialized multitasking multimodal framework. Specifically, our framework serializes tasks in the order of current paralinguistic attribute prediction, response paralinguistic attribute prediction, and response text generation with autoregressive conditioning. We utilize the Switchboard-1 corpus, including its sentiment labels as the paralinguistic attribute, as our spoken dialogue dataset. Experimental results indicate the proposed serialized multitasking method outperforms typical sequence classification techniques on current and response sentiment classification. Furthermore, leveraging conversational context and speech embeddings significantly improves both response text generation and sentiment prediction. Our proposed framework achieves relative improvements of 6.7%, 12.0%, and 3.5% in current sentiment accuracy, response sentiment accuracy, and response text BLEU score, respectively.
Towards ASR Robust Spoken Language Understanding Through In-Context Learning With Word Confusion Networks
Jan 05, 2024



In the realm of spoken language understanding (SLU), numerous natural language understanding (NLU) methodologies have been adapted by supplying large language models (LLMs) with transcribed speech instead of conventional written text. In real-world scenarios, prior to input into an LLM, an automated speech recognition (ASR) system generates an output transcript hypothesis, where inherent errors can degrade subsequent SLU tasks. Here we introduce a method that utilizes the ASR system's lattice output instead of relying solely on the top hypothesis, aiming to encapsulate speech ambiguities and enhance SLU outcomes. Our in-context learning experiments, covering spoken question answering and intent classification, underline the LLM's resilience to noisy speech transcripts with the help of word confusion networks from lattices, bridging the SLU performance gap between using the top ASR hypothesis and an oracle upper bound. Additionally, we delve into the LLM's robustness to varying ASR performance conditions and scrutinize the aspects of in-context learning which prove the most influential.
Perseus: Removing Energy Bloat from Large Model Training
Dec 12, 2023Training large AI models on numerous GPUs consumes a massive amount of energy. We observe that not all energy consumed during training directly contributes to end-to-end training throughput, and a significant portion can be removed without slowing down training, which we call energy bloat. In this work, we identify two independent sources of energy bloat in large model training, intrinsic and extrinsic, and propose Perseus, a unified optimization framework that mitigates both. Perseus obtains the "iteration time-energy" Pareto frontier of any large model training job using an efficient iterative graph cut-based algorithm and schedules energy consumption of its forward and backward computations across time to remove intrinsic and extrinsic energy bloat. Evaluation on large models like GPT-3 and Bloom shows that Perseus reduces energy consumption of large model training by up to 30%, enabling savings otherwise unobtainable before.