 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Predict-Then-Optimize Framework for Equitable Post-Disaster Power Restoration
Aug 06, 2025The increasing frequency of extreme weather events, such as hurricanes, highlights the urgent need for efficient and equitable power system restoration. Many electricity providers make restoration decisions primarily based on the volume of power restoration requests from each region. However, our data-driven analysis reveals significant disparities in request submission volume, as disadvantaged communities tend to submit fewer restoration requests. This disparity makes the current restoration solution inequitable, leaving these communities vulnerable to extended power outages. To address this, we aim to propose an equity-aware power restoration strategy that balances both restoration efficiency and equity across communities. However, achieving this goal is challenging for two reasons: the difficulty of predicting repair durations under dataset heteroscedasticity, and the tendency of reinforcement learning agents to favor low-uncertainty actions, which potentially undermine equity. To overcome these challenges, we design a predict-then-optimize framework called EPOPR with two key components: (1) Equity-Conformalized Quantile Regression for uncertainty-aware repair duration prediction, and (2) Spatial-Temporal Attentional RL that adapts to varying uncertainty levels across regions for equitable decision-making. Experimental results show that our EPOPR effectively reduces the average power outage duration by 3.60% and decreases inequity between different communities by 14.19% compared to state-of-the-art baselines.
Evaluating the Feasibility and Accuracy of Large Language Models for Medical History-Taking in Obstetrics and Gynecology
Mar 31, 2025Effective physician-patient communications in pre-diagnostic environments, and most specifically in complex and sensitive medical areas such as infertility, are critical but consume a lot of time and, therefore, cause clinic workflows to become inefficient. Recent advancements in Large Language Models (LLMs) offer a potential solution for automating conversational medical history-taking and improving diagnostic accuracy. This study evaluates the feasibility and performance of LLMs in those tasks for infertility cases. An AI-driven conversational system was developed to simulate physician-patient interactions with ChatGPT-4o and ChatGPT-4o-mini. A total of 70 real-world infertility cases were processed, generating 420 diagnostic histories. Model performance was assessed using F1 score, Differential Diagnosis (DDs) Accuracy, and Accuracy of Infertility Type Judgment (ITJ). ChatGPT-4o-mini outperformed ChatGPT-4o in information extraction accuracy (F1 score: 0.9258 vs. 0.9029, p = 0.045, d = 0.244) and demonstrated higher completeness in medical history-taking (97.58% vs. 77.11%), suggesting that ChatGPT-4o-mini is more effective in extracting detailed patient information, which is critical for improving diagnostic accuracy. In contrast, ChatGPT-4o performed slightly better in differential diagnosis accuracy (2.0524 vs. 2.0048, p > 0.05). ITJ accuracy was higher in ChatGPT-4o-mini (0.6476 vs. 0.5905) but with lower consistency (Cronbach's $\alpha$ = 0.562), suggesting variability in classification reliability. Both models demonstrated strong feasibility in automating infertility history-taking, with ChatGPT-4o-mini excelling in completeness and extraction accuracy. In future studies, expert validation for accuracy and dependability in a clinical setting, AI model fine-tuning, and larger datasets with a mix of cases of infertility have to be prioritized.
LREF: A Novel LLM-based Relevance Framework for E-commerce
Mar 12, 2025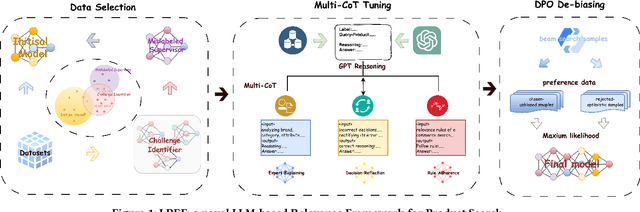
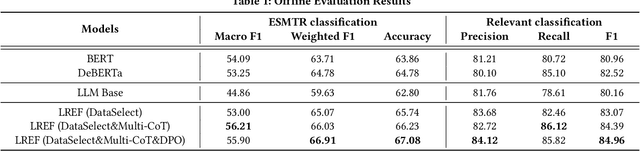


Query and product relevance prediction is a critical component for ensuring a smooth user experience in e-commerce search. Traditional studies mainly focus on BERT-based models to assess the semantic relevance between queries and products. However, the discriminative paradigm and limited knowledge capacity of these approaches restrict their ability to comprehend the relevance between queries and products fully. With the rapid advancement of Large Language Models (LLMs), recent research has begun to explore their application to industrial search systems, as LLMs provide extensive world knowledge and flexible optimization for reasoning processes. Nonetheless, directly leveraging LLMs for relevance prediction tasks introduces new challenges, including a high demand for data quality, the necessity for meticulous optimization of reasoning processes, and an optimistic bias that can result in over-recall. To overcome the above problems, this paper proposes a novel framework called the LLM-based RElevance Framework (LREF) aimed at enhancing e-commerce search relevance. The framework comprises three main stages: supervised fine-tuning (SFT) with Data Selection, Multiple Chain of Thought (Multi-CoT) tuning, and Direct Preference Optimization (DPO) for de-biasing. We evaluate the performance of the framework through a series of offline experiments on large-scale real-world datasets, as well as online A/B testing. The results indicate significant improvements in both offline and online metrics. Ultimately, the model was deployed in a well-known e-commerce application, yielding substantial commercial benefits.
Tactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context LLMs
Feb 17, 2025Long-context models are essential for many applications but face inefficiencies in loading large KV caches during decoding. Prior methods enforce fixed token budgets for sparse attention, assuming a set number of tokens can approximate full attention. However, these methods overlook variations in the importance of attention across heads, layers, and contexts. To address these limitations, we propose Tactic, a sparsity-adaptive and calibration-free sparse attention mechanism that dynamically selects tokens based on their cumulative attention scores rather than a fixed token budget. By setting a target fraction of total attention scores, Tactic ensures that token selection naturally adapts to variations in attention sparsity. To efficiently approximate this selection, Tactic leverages clustering-based sorting and distribution fitting, allowing it to accurately estimate token importance with minimal computational overhead. We show that Tactic outperforms existing sparse attention algorithms, achieving superior accuracy and up to 7.29x decode attention speedup. This improvement translates to an overall 1.58x end-to-end inference speedup, making Tactic a practical and effective solution for long-context LLM inference in accuracy-sensitive applications.
Twilight: Adaptive Attention Sparsity with Hierarchical Top-$p$ Pruning
Feb 06, 2025



Leveraging attention sparsity to accelerate long-context large language models (LLMs) has been a hot research topic. However, current algorithms such as sparse attention or key-value (KV) cache compression tend to use a fixed budget, which presents a significant challenge during deployment because it fails to account for the dynamic nature of real-world scenarios, where the optimal balance between accuracy and efficiency can vary greatly. In this paper, we find that borrowing top-$p$ sampling (nucleus sampling) to sparse attention can surprisingly achieve adaptive budgeting. Based on this, we propose Twilight, a framework to bring adaptive sparsity to any existing sparse attention algorithm without sacrificing their accuracy. Empirical results show that Twilight can adaptively prune at most 98% of redundant tokens, leading to $15.4\times$ acceleration in self-attention operations and $3.9\times$ acceleration in end-to-end per token latency in long context LLM decoding.
Fast CRDNN: Towards on Site Training of Mobile Construction Machines
Jun 04, 2020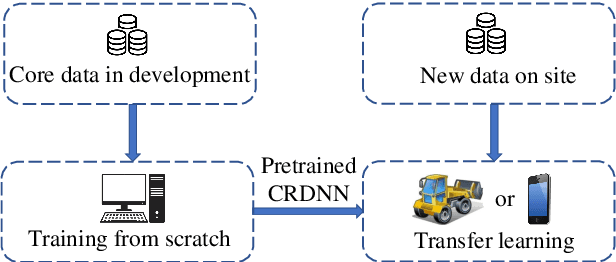

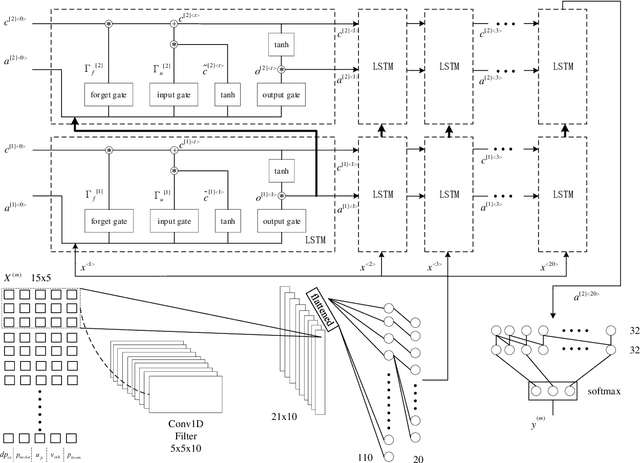

The CRDNN is a combined neural network that can increase the holistic efficiency of torque based mobile working machines by about 9% by means of accurately detecting the truck loading cycles. On the one hand, it is a robust but offline learning algorithm so that it is more accurate and much quicker than the previous methods. However, on the other hand, its accuracy can not always be guaranteed because of the diversity of the mobile machines industry and the nature of the offline method. To address the problem, we utilize the transfer learning algorithm and the Internet of Things (IoT) technology. Concretely, the CRDNN is first trained by computer and then saved in the on-board ECU. In case that the pre-trained CRDNN is not suitable for the new machine, the operator can label some new data by our App connected to the on-board ECU of that machine through Bluetooth. With the newly labeled data, we can directly further train the pretrained CRDNN on the ECU without overloading since transfer learning requires less computation effort than training the networks from scratch. In our paper, we prove this idea and show that CRDNN is always competent, with the help of transfer learning and IoT technology by field experiment, even the new machine may have a different distribution. Also, we compared the performance of other SOTA multivariate time series algorithms on predicting the working state of the mobile machines, which denotes that the CRDNNs are still the most suitable solution. As a by-product, we build up a human-machine communication system to label the dataset, which can be operated by engineers without knowledge about Artificial Intelligence (AI).