 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactic: Adaptive Sparse Attention with Clustering and Distribution Fitting for Long-Context LLMs
Feb 17, 2025Long-context models are essential for many applications but face inefficiencies in loading large KV caches during decoding. Prior methods enforce fixed token budgets for sparse attention, assuming a set number of tokens can approximate full attention. However, these methods overlook variations in the importance of attention across heads, layers, and contexts. To address these limitations, we propose Tactic, a sparsity-adaptive and calibration-free sparse attention mechanism that dynamically selects tokens based on their cumulative attention scores rather than a fixed token budget. By setting a target fraction of total attention scores, Tactic ensures that token selection naturally adapts to variations in attention sparsity. To efficiently approximate this selection, Tactic leverages clustering-based sorting and distribution fitting, allowing it to accurately estimate token importance with minimal computational overhead. We show that Tactic outperforms existing sparse attention algorithms, achieving superior accuracy and up to 7.29x decode attention speedup. This improvement translates to an overall 1.58x end-to-end inference speedup, making Tactic a practical and effective solution for long-context LLM inference in accuracy-sensitive applications.
ForestColl: Efficient Collective Communications on Heterogeneous Network Fabrics
Feb 09, 2024



As modern DNN models grow ever larger, collective communications between the accelerators (allreduce, etc.) emerge as a significant performance bottleneck. Designing efficient communication schedules is challenging given today's highly diverse and heterogeneous network fabrics. In this paper, we present ForestColl, a tool that generates efficient schedules for any network topology. ForestColl constructs broadcast/aggregation spanning trees as the communication schedule, achieving theoretically minimum network congestion. Its schedule generation runs in strongly polynomial time and is highly scalable. ForestColl supports any network fabrics, including both switching fabrics and direct connections, as well as any network graph structure. We evaluated ForestColl on multi-cluster AMD MI250 and NVIDIA A100 platforms. ForestColl's schedules achieved up to 52\% higher performance compared to the vendors' own optimized communication libraries, RCCL and NCCL. ForestColl also outperforms other state-of-the-art schedule generation techniques with both up to 61\% more efficient generated schedules and orders of magnitude faster schedule generation speed.
Bandwidth Optimal Pipeline Schedule for Collective Communication
May 31, 2023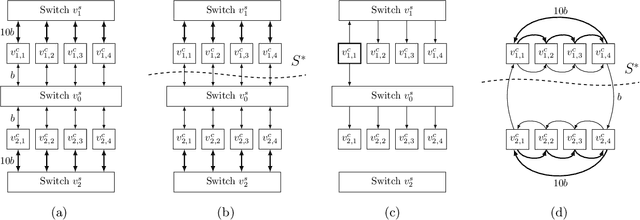
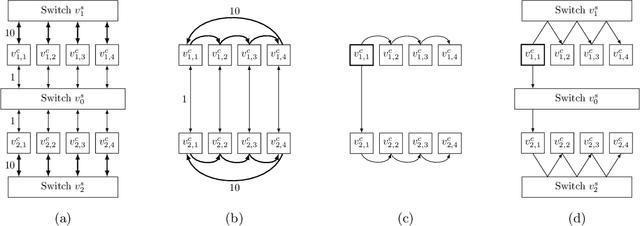
We present a strongly polynomial-time algorithm to generate bandwidth optimal allgather/reduce-scatter on any network topology, with or without switches. Our algorithm constructs pipeline schedules achieving provably the best possible bandwidth performance on a given topology. To provide a universal solution, we model the network topology as a directed graph with heterogeneous link capacities and switches directly as vertices in the graph representation. The algorithm is strongly polynomial-time with respect to the topology size. This work heavily relies on previous graph theory work on edge-disjoint spanning trees and edge splitting. While we focus on allgather, the methods in this paper can be easily extended to generate schedules for reduce, broadcast, reduce-scatter, and allreduce.
Optimal Direct-Connect Topologies for Collective Communications
Feb 07, 2022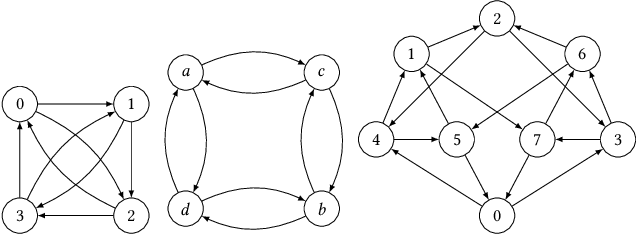
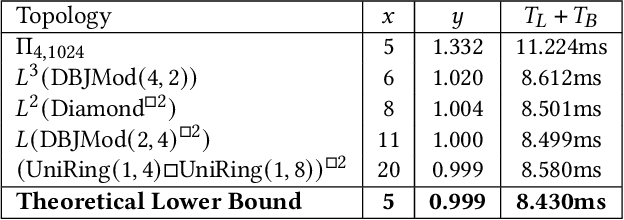
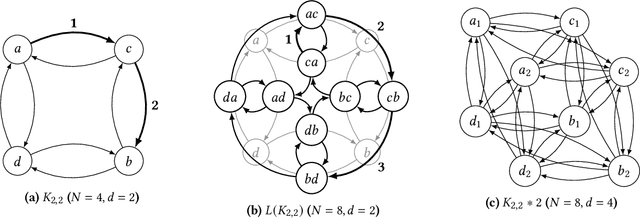
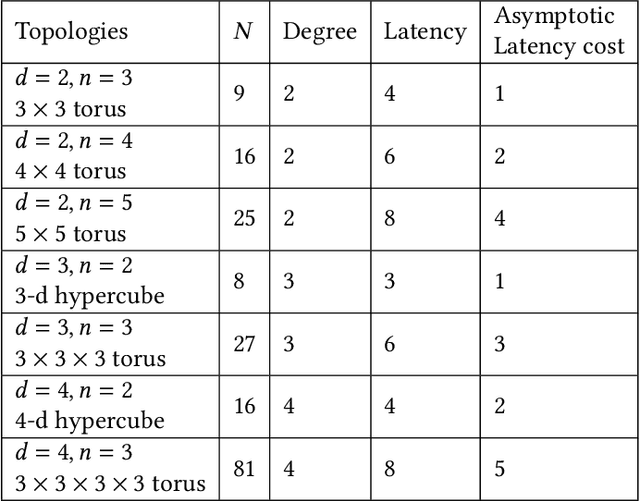
We consider the problem of distilling optimal network topologies for collective communications. We provide an algorithmic framework for constructing direct-connect topologies optimized for the latency-bandwidth tradeoff given a collective communication workload. Our algorithmic framework allows us to start from small base topologies and associated communication schedules and use a set of techniques that can be iteratively applied to derive much larger topologies and associated schedules. Our approach allows us to synthesize many different topologies and schedules for a given cluster size and degree constraint, and then identify the optimal topology for a given workload. We provide an analytical-model-based evaluation of the derived topologies and results on a small-scale optical testbed that uses patch panels for configuring a topology for the duration of an application's execution. We show that the derived topologies and schedules provide significant performance benefits over existing collective communications implementations.
AutoLRS: Automatic Learning-Rate Schedule by Bayesian Optimization on the Fly
May 22, 2021
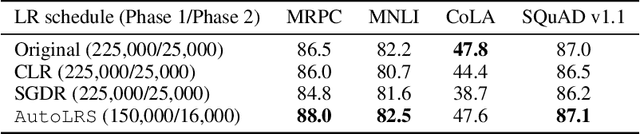
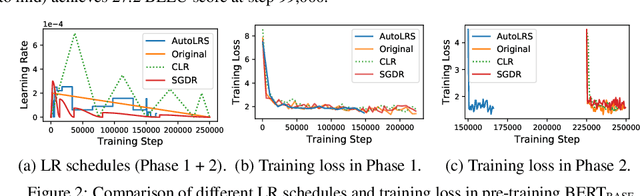

The learning rate (LR) schedule is one of the most important hyper-parameters needing careful tuning in training DNNs. However, it is also one of the least automated parts of machine learning systems and usually costs significant manual effort and computing. Though there are pre-defined LR schedules and optimizers with adaptive LR, they introduce new hyperparameters that need to be tuned separately for different tasks/datasets. In this paper, we consider the question: Can we automatically tune the LR over the course of training without human involvement? We propose an efficient method, AutoLRS, which automatically optimizes the LR for each training stage by modeling training dynamics. AutoLRS aims to find an LR applied to every $\tau$ steps that minimizes the resulted validation loss. We solve this black-box optimization on the fly by Bayesian optimization (BO). However, collecting training instances for BO requires a system to evaluate each LR queried by BO's acquisition function for $\tau$ steps, which is prohibitively expensive in practice. Instead, we apply each candidate LR for only $\tau'\ll\tau$ steps and train an exponential model to predict the validation loss after $\tau$ steps. This mutual-training process between BO and the loss-prediction model allows us to limit the training steps invested in the BO search. We demonstrate the advantages and the generality of AutoLRS through extensive experiments of training DNNs for tasks from diverse domains using different optimizers. The LR schedules auto-generated by AutoLRS lead to a speedup of $1.22\times$, $1.43\times$, and $1.5\times$ when training ResNet-50, Transformer, and BERT, respectively, compared to the LR schedules in their original papers, and an average speedup of $1.31\times$ over state-of-the-art heavily-tuned LR schedules.