 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stationarity-and-Coupling Criterion for Training-Free Time-Lagged Spectral Embeddings of Multivariate Time Series
Jun 11, 2026We study training-free fixed-length descriptors for multivariate time series and ask not merely whether such a descriptor performs well, but when it can be expected to work at all. Our object of study is $D(τ)$, built from a time-lagged correlation matrix truncated at the Marchenko-Pastur edge so that only signal-bearing eigenvalues survive and classified by cosine similarity to class centroids with zero learned parameters. The central contribution is not the descriptor but a falsifiable applicability criterion for it. Working from a stationary Gaussian VAR(1) model, we argue that $D(τ)$ separates two classes when the signals are approximately stationary and the class information lives in their cross-channel temporal coupling rather than in marginal per-channel power. We derive, semi-formally, three consequences: a distinguishability condition, why the static ($τ=0$) covariance collapses to chance, and why a stationary but power-discriminated paradigm defeats the descriptor. The criterion is operational: a two-part pre-flight test -- an augmented Dickey-Fuller stationarity check and a power-baseline saturation check -- predicts applicability before any training. We validate both halves on a mixed assortment. On four paradigms that satisfy the criterion (Sleep-EDF, BCI-IV-2a, MIT-BIH, ESC-50) the descriptor is competitive with strong baselines at a fraction of their cost, reaching $88.5\pm4.5\%$ under 20-subject leave-one-subject-out on Sleep-EDF on a single CPU thread. On three that violate it -- non-stationary ERPs, and financial-volatility and wearable-stress regimes that are power-discriminated -- it fails exactly as the pre-flight predicts, and these negatives are the more informative half. We are explicit that $D(τ)$ is not the most accurate representation; its value is a compact, training-free embedding whose domain of validity is known in advance.
Optimal Direct-Connect Topologies for Collective Communications
Feb 07, 2022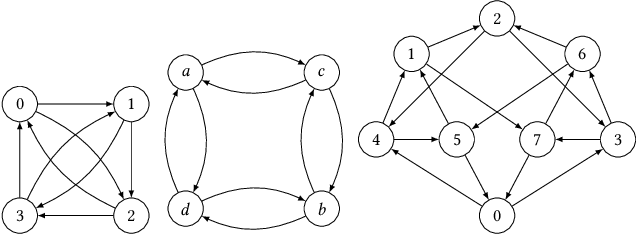
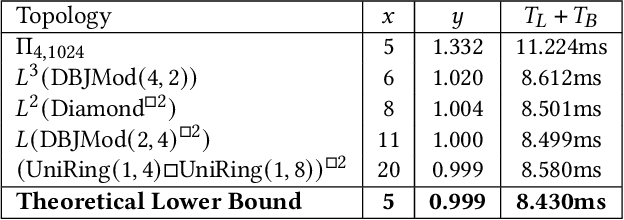
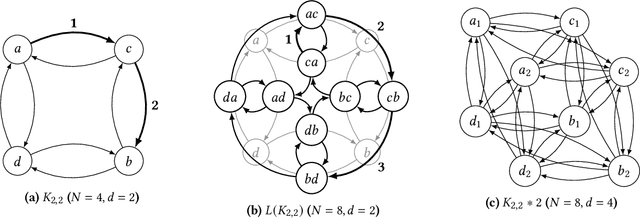
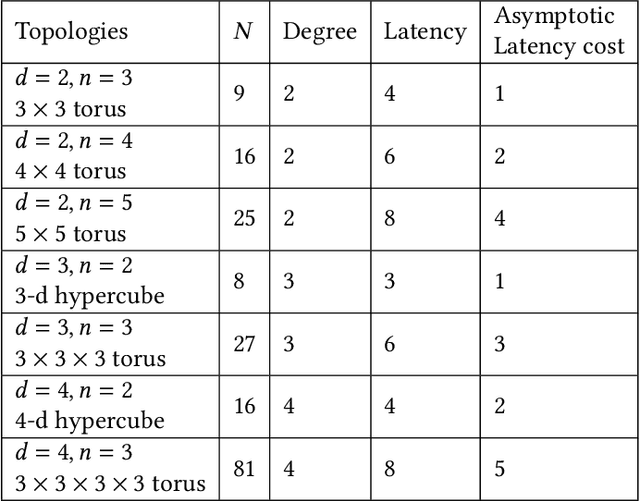
We consider the problem of distilling optimal network topologies for collective communications. We provide an algorithmic framework for constructing direct-connect topologies optimized for the latency-bandwidth tradeoff given a collective communication workload. Our algorithmic framework allows us to start from small base topologies and associated communication schedules and use a set of techniques that can be iteratively applied to derive much larger topologies and associated schedules. Our approach allows us to synthesize many different topologies and schedules for a given cluster size and degree constraint, and then identify the optimal topology for a given workload. We provide an analytical-model-based evaluation of the derived topologies and results on a small-scale optical testbed that uses patch panels for configuring a topology for the duration of an application's execution. We show that the derived topologies and schedules provide significant performance benefits over existing collective communications implementations.
Sparse Diffusion-Convolutional Neural Networks
Oct 26, 2017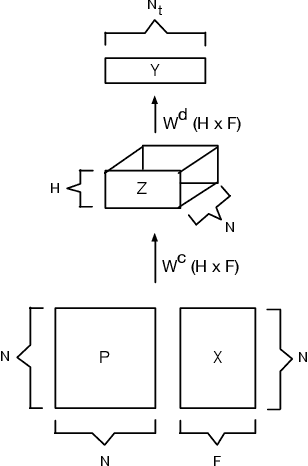
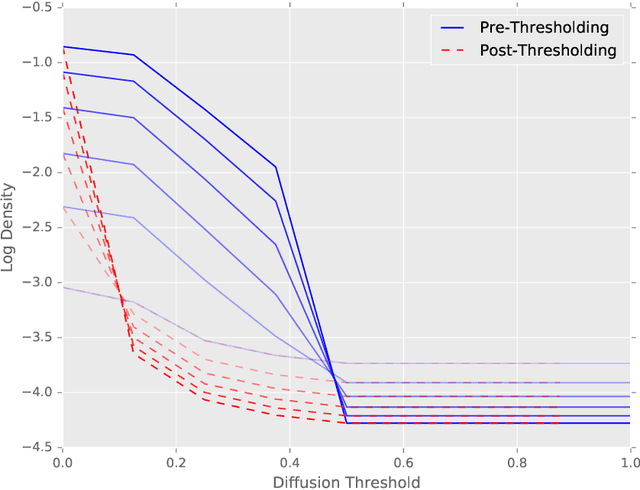
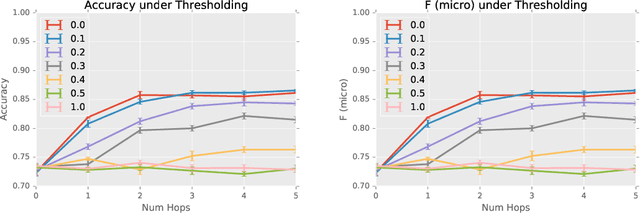
The predictive power and overall computational efficiency of Diffusion-convolutional neural networks make them an attractive choice for node classification tasks. However, a naive dense-tensor-based implementation of DCNNs leads to $\mathcal{O}(N^2)$ memory complexity which is prohibitive for large graphs. In this paper, we introduce a simple method for thresholding input graphs that provably reduces memory requirements of DCNNs to O(N) (i.e. linear in the number of nodes in the input) without significantly affecting predictive performance.