 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Data Lakes
Jun 06, 2025Constructing real-world data-to-insight pipelines often involves data extraction from data lakes, data integration across heterogeneous data sources, and diverse operations from data cleaning to analysis. The design and implementation of data science pipelines require domain knowledge, technical expertise, and even project-specific insights. AI systems have shown remarkable reasoning, coding, and understanding capabilities. However, it remains unclear to what extent these capabilities translate into successful design and execution of such complex pipelines. We introduce KRAMABENCH: a benchmark composed of 104 manually-curated real-world data science pipelines spanning 1700 data files from 24 data sources in 6 different domains. We show that these pipelines test the end-to-end capabilities of AI systems on data processing, requiring data discovery, wrangling and cleaning, efficient processing, statistical reasoning, and orchestrating data processing steps given a high-level task. Our evaluation tests 5 general models and 3 code generation models using our reference framework, DS-GURU, which instructs the AI model to decompose a question into a sequence of subtasks, reason through each step, and synthesize Python code that implements the proposed design. Our results on KRAMABENCH show that, although the models are sufficiently capable of solving well-specified data science code generation tasks, when extensive data processing and domain knowledge are required to construct real-world data science pipelines, existing out-of-box models fall short. Progress on KramaBench represents crucial steps towards developing autonomous data science agents for real-world applications. Our code, reference framework, and data are available at https://github.com/mitdbg/KramaBench.
Optimized Network Architectures for Large Language Model Training with Billions of Parameters
Jul 22, 2023



This paper challenges the well-established paradigm for building any-to-any networks for training Large Language Models (LLMs). We show that LLMs exhibit a unique communication pattern where only small groups of GPUs require high-bandwidth any-to-any communication within them, to achieve near-optimal training performance. Across these groups of GPUs, the communication is insignificant, sparse, and homogeneous. We propose a new network architecture that closely resembles the communication requirement of LLMs. Our architecture partitions the cluster into sets of GPUs interconnected with non-blocking any-to-any high-bandwidth interconnects that we call HB domains. Across the HB domains, the network only connects GPUs with communication demands. We call this network a "rail-only" connection, and show that our proposed architecture reduces the network cost by up to 75% compared to the state-of-the-art any-to-any Clos networks without compromising the performance of LLM training.
Optimal Direct-Connect Topologies for Collective Communications
Feb 07, 2022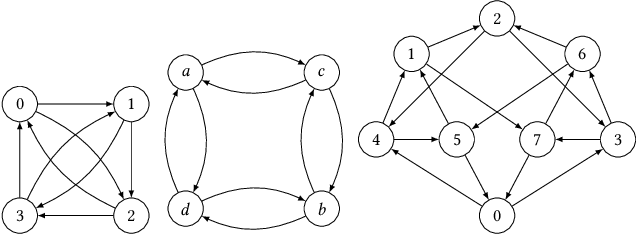
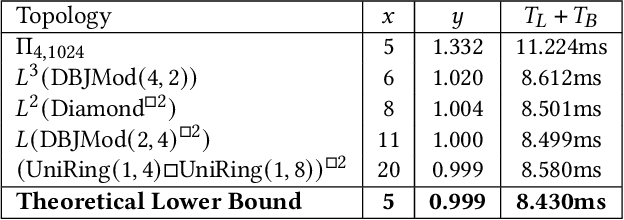
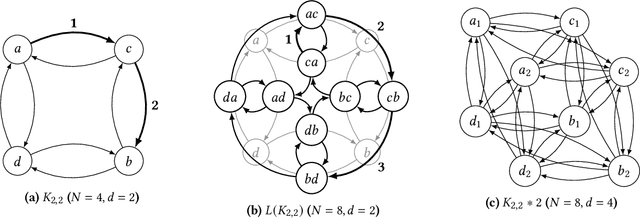
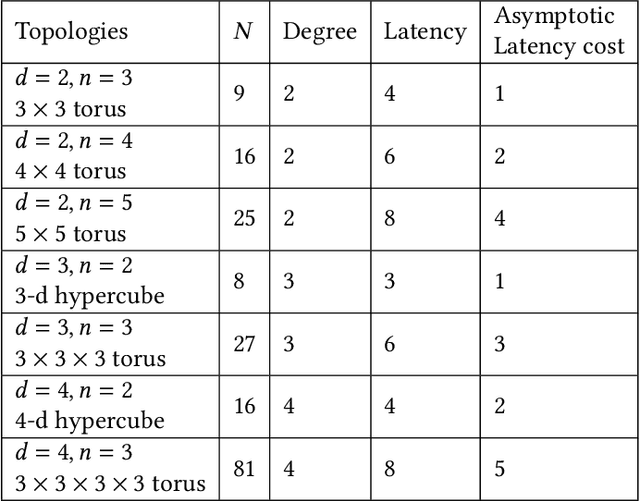
We consider the problem of distilling optimal network topologies for collective communications. We provide an algorithmic framework for constructing direct-connect topologies optimized for the latency-bandwidth tradeoff given a collective communication workload. Our algorithmic framework allows us to start from small base topologies and associated communication schedules and use a set of techniques that can be iteratively applied to derive much larger topologies and associated schedules. Our approach allows us to synthesize many different topologies and schedules for a given cluster size and degree constraint, and then identify the optimal topology for a given workload. We provide an analytical-model-based evaluation of the derived topologies and results on a small-scale optical testbed that uses patch panels for configuring a topology for the duration of an application's execution. We show that the derived topologies and schedules provide significant performance benefits over existing collective communications implementations.
Distributed Low Precision Training Without Mixed Precision
Dec 27, 2019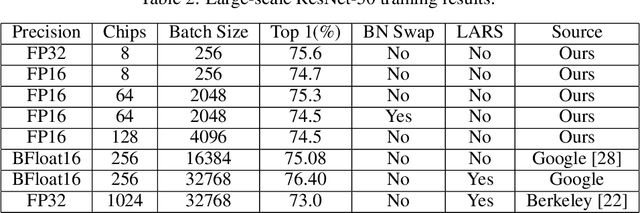
Low precision training is one of the most popular strategies for deploying the deep model on limited hardware resources. Fixed point implementation of DCNs has the potential to alleviate complexities and facilitate potential deployment on embedded hardware. However, most low precision training solution is based on a mixed precision strategy. In this paper, we have presented an ablation study on different low precision training strategy and propose a solution for IEEE FP-16 format throughout the training process. We tested the ResNet50 on 128 GPU cluster on ImageNet-full dataset. We have viewed that it is not essential to use FP32 format to train the deep models. We have viewed that communication cost reduction, model compression, and large-scale distributed training are three coupled problems.
Segmentation is All You Need
May 26, 2019
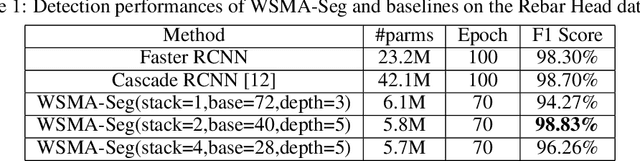
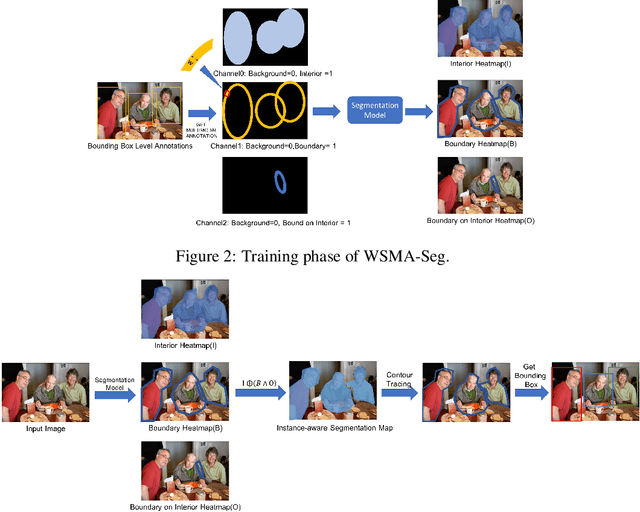

Region proposal mechanisms are essential for existing deep learning approaches to object detection in images. Although they can generally achieve a good detection performance under normal circumstances, their recall in a scene with extreme cases is unacceptably low. This is mainly because bounding box annotations contain much environment noise information, and non-maximum suppression (NMS) is required to select target boxes. Therefore, in this paper, we propose the first anchor-free and NMS-free object detection model called weakly supervised multimodal annotation segmentation (WSMA-Seg), which utilizes segmentation models to achieve an accurate and robust object detection without NMS. In WSMA-Seg, multimodal annotations are proposed to achieve an instance-aware segmentation using weakly supervised bounding boxes; we also develop a run-data-based following algorithm to trace contours of objects. In addition, we propose a multi-scale pooling segmentation (MSP-Seg) as the underlying segmentation model of WSMA-Seg to achieve a more accurate segmentation and to enhance the detection accuracy of WSMA-Seg. Experimental results on multiple datasets show that the proposed WSMA-Seg approach outperforms the state-of-the-art detectors.
FoxNet: A Multi-face Alignment Method
May 15, 2019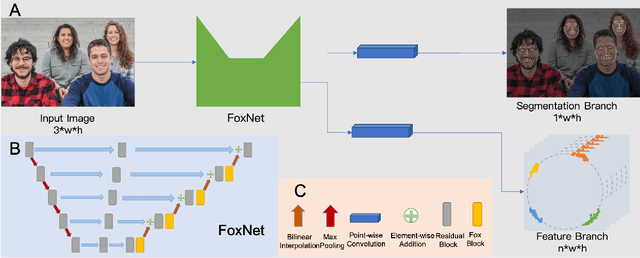

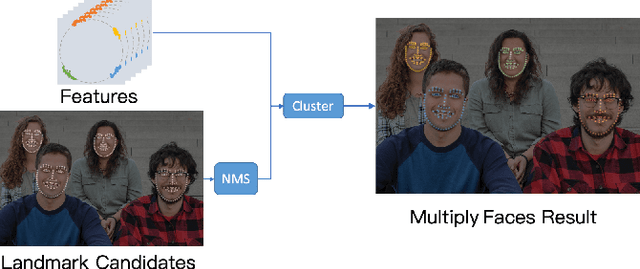
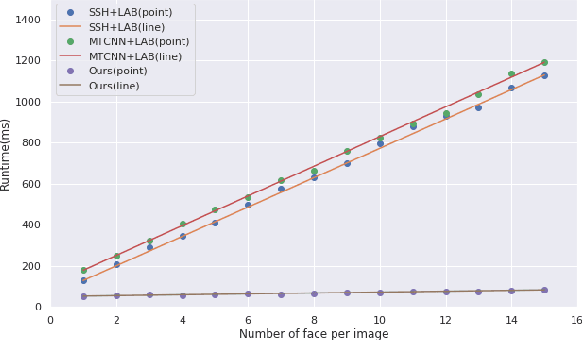
Multi-face alignment aims to identify geometry structures of multiple faces in an image, and its performance is essential for the many practical tasks, such as face recognition, face tracking, and face animation. In this work, we present a fast bottom-up multi-face alignment approach, which can simultaneously localize multi-person facial landmarks with high precision.In more detail, our bottom-up architecture maps the landmarks to the high-dimensional space with which landmarks of all faces are represented. By clustering the features belonging to the same face, our approach can align the multi-person facial landmarks synchronously.Extensive experiments show that our method can achieve high performance in the multi-face landmark alignment task while our model is extremely fast. Moreover, we propose a new multi-face dataset to compare the speed and precision of bottom-up face alignment method with top-down methods. Our dataset is publicly available at https://github.com/AISAResearch/FoxNet