 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircuitSynth: Reliable Synthetic Data Generation
Apr 11, 2026The generation of high-fidelity synthetic data is a cornerstone of modern machine learning, yet Large Language Models (LLMs) frequently suffer from hallucinations, logical inconsistencies, and mode collapse when tasked with structured generation. Existing approaches, such as prompting or retrieval-augmented generation, lack the mechanisms to balance linguistic expressivity with formal guarantees regarding validity and coverage. To address this, we propose CircuitSynth, a novel neuro-symbolic framework that decouples semantic reasoning from surface realization. By distilling the reasoning capabilities of a Teacher LLM into a Probabilistic Sentential Decision Diagram (PSDD), CircuitSynth creates a tractable semantic prior that structurally enforces hard logical constraints. Furthermore, we introduce a convex optimization mechanism to rigorously satisfy soft distributional goals. Empirical evaluations across diverse benchmarks demonstrate that CircuitSynth achieves 100% Schema Validity even in complex logic puzzles where unconstrained baselines fail (12.4%) while significantly outperforming state-of-the-art methods in rare-combination coverage.
Visual Set Program Synthesizer
Mar 16, 2026A user pointing their phone at a supermarket shelf and asking "Which soda has the least sugar?" poses a difficult challenge for current visual Al assistants. Such queries require not only object recognition, but explicit set-based reasoning such as filtering, comparison, and aggregation. Standard endto-end MLLMs often fail at these tasks because they lack an explicit mechanism for compositional logic. We propose treating visual reasoning as Visual Program Synthesis, where the model first generates a symbolic program that is executed by a separate engine grounded in visual scenes. We also introduce Set-VQA, a new benchmark designed specifically for evaluating set-based visual reasoning. Experiments show that our approach significantly outperforms state-of-the-art baselines on complex reasoning tasks, producing more systematic and transparent behavior while substantially improving answer accuracy. These results demonstrate that program-driven reasoning provides a principled alternative to black-box visual-language inference.
* 10 pages, IEEE International Conference on Multimedia and Expo 2026
Provable Defense Framework for LLM Jailbreaks via Noise-Augumented Alignment
Feb 02, 2026Large Language Models (LLMs) remain vulnerable to adaptive jailbreaks that easily bypass empirical defenses like GCG. We propose a framework for certifiable robustness that shifts safety guarantees from single-pass inference to the statistical stability of an ensemble. We introduce Certified Semantic Smoothing (CSS) via Stratified Randomized Ablation, a technique that partitions inputs into immutable structural prompts and mutable payloads to derive rigorous lo norm guarantees using the Hypergeometric distribution. To resolve performance degradation on sparse contexts, we employ Noise-Augmented Alignment Tuning (NAAT), which transforms the base model into a semantic denoiser. Extensive experiments on Llama-3 show that our method reduces the Attack Success Rate of gradient-based attacks from 84.2% to 1.2% while maintaining 94.1% benign utility, significantly outperforming character-level baselines which degrade utility to 74.3%. This framework provides a deterministic certificate of safety, ensuring that a model remains robust against all adversarial variants within a provable radius.
Affinity-Graph-Guided Contractive Learning for Pretext-Free Medical Image Segmentation with Minimal Annotation
Oct 14, 2024



The combination of semi-supervised learning (SemiSL) and contrastive learning (CL) has been successful in medical image segmentation with limited annotations. However, these works often rely on pretext tasks that lack the specificity required for pixel-level segmentation, and still face overfitting issues due to insufficient supervision signals resulting from too few annotations. Therefore, this paper proposes an affinity-graph-guided semi-supervised contrastive learning framework (Semi-AGCL) by establishing additional affinity-graph-based supervision signals between the student and teacher network, to achieve medical image segmentation with minimal annotations without pretext. The framework first designs an average-patch-entropy-driven inter-patch sampling method, which can provide a robust initial feature space without relying on pretext tasks. Furthermore, the framework designs an affinity-graph-guided loss function, which can improve the quality of the learned representation and the model generalization ability by exploiting the inherent structure of the data, thus mitigating overfitting. Our experiments indicate that with merely 10% of the complete annotation set, our model approaches the accuracy of the fully annotated baseline, manifesting a marginal deviation of only 2.52%. Under the stringent conditions where only 5% of the annotations are employed, our model exhibits a significant enhancement in performance surpassing the second best baseline by 23.09% on the dice metric and achieving an improvement of 26.57% on the notably arduous CRAG and ACDC datasets.
SoccerNet 2024 Challenges Results
Sep 16, 2024

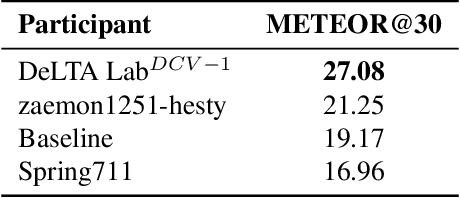
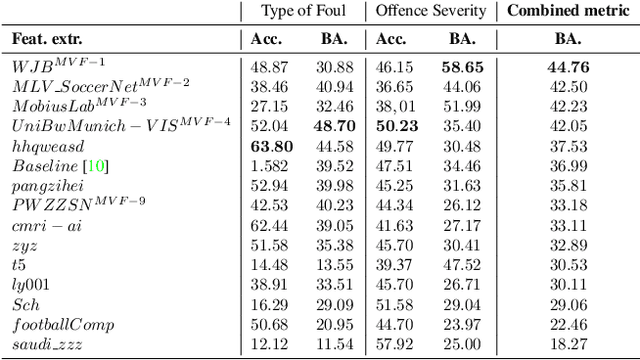
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Does DetectGPT Fully Utilize Perturbation? Selective Perturbation on Model-Based Contrastive Learning Detector would be Better
Feb 04, 2024



The burgeoning capabilities of large language models (LLMs) have raised growing concerns about abuse. DetectGPT, a zero-shot metric-based unsupervised machine-generated text detector, first introduces perturbation and shows great performance improvement. However, DetectGPT's random perturbation strategy might introduce noise, limiting the distinguishability and further performance improvements. Moreover, its logit regression module relies on setting the threshold, which harms the generalizability and applicability of individual or small-batch inputs. Hence, we propose a novel detector, Pecola, which uses selective strategy perturbation to relieve the information loss caused by random masking, and multi-pair contrastive learning to capture the implicit pattern information during perturbation, facilitating few-shot performance. The experiments show that Pecola outperforms the SOTA method by 1.20% in accuracy on average on four public datasets. We further analyze the effectiveness, robustness, and generalization of our perturbation method.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
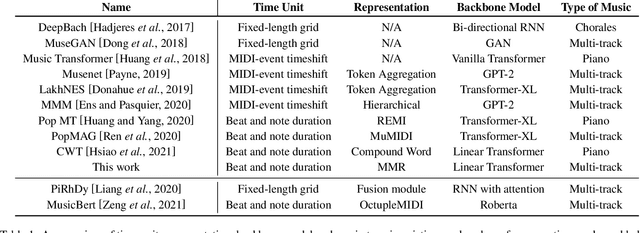
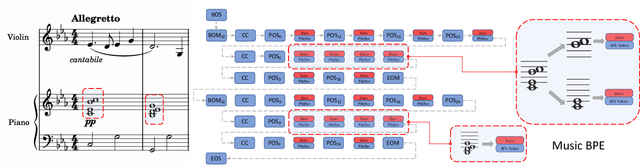
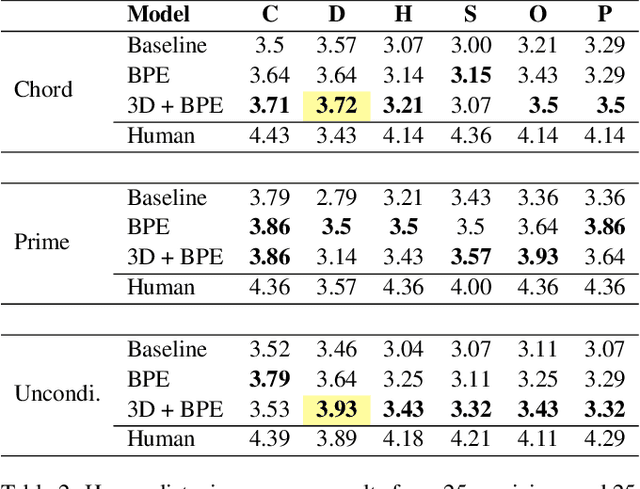
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.
Distributed Low Precision Training Without Mixed Precision
Dec 27, 2019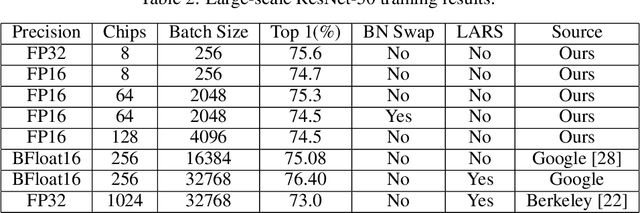
Low precision training is one of the most popular strategies for deploying the deep model on limited hardware resources. Fixed point implementation of DCNs has the potential to alleviate complexities and facilitate potential deployment on embedded hardware. However, most low precision training solution is based on a mixed precision strategy. In this paper, we have presented an ablation study on different low precision training strategy and propose a solution for IEEE FP-16 format throughout the training process. We tested the ResNet50 on 128 GPU cluster on ImageNet-full dataset. We have viewed that it is not essential to use FP32 format to train the deep models. We have viewed that communication cost reduction, model compression, and large-scale distributed training are three coupled problems.
Segmentation is All You Need
May 26, 2019
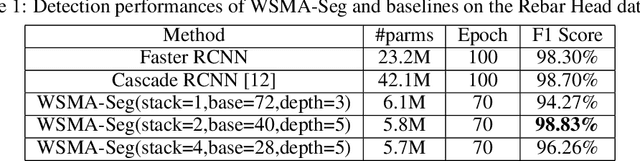
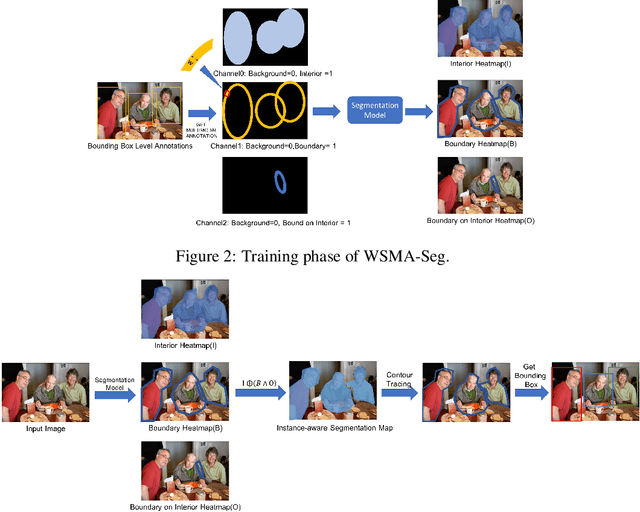

Region proposal mechanisms are essential for existing deep learning approaches to object detection in images. Although they can generally achieve a good detection performance under normal circumstances, their recall in a scene with extreme cases is unacceptably low. This is mainly because bounding box annotations contain much environment noise information, and non-maximum suppression (NMS) is required to select target boxes. Therefore, in this paper, we propose the first anchor-free and NMS-free object detection model called weakly supervised multimodal annotation segmentation (WSMA-Seg), which utilizes segmentation models to achieve an accurate and robust object detection without NMS. In WSMA-Seg, multimodal annotations are proposed to achieve an instance-aware segmentation using weakly supervised bounding boxes; we also develop a run-data-based following algorithm to trace contours of objects. In addition, we propose a multi-scale pooling segmentation (MSP-Seg) as the underlying segmentation model of WSMA-Seg to achieve a more accurate segmentation and to enhance the detection accuracy of WSMA-Seg. Experimental results on multiple datasets show that the proposed WSMA-Seg approach outperforms the state-of-the-art detectors.