 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Class-guided Hashing for Multi-label Cross-modal Retrieval
Oct 20, 2024



Deep hashing, due to its low cost and efficient retrieval advantages, is widely valued in cross-modal retrieval. However, existing cross-modal hashing methods either explore the relationships between data points, which inevitably leads to intra-class dispersion, or explore the relationships between data points and categories while ignoring the preservation of inter-class structural relationships, resulting in the generation of suboptimal hash codes. How to maintain both intra-class aggregation and inter-class structural relationships, In response to this issue, this paper proposes a DCGH method. Specifically, we use proxy loss as the mainstay to maintain intra-class aggregation of data, combined with pairwise loss to maintain inter-class structural relationships, and on this basis, further propose a variance constraint to address the semantic bias issue caused by the combination. A large number of comparative experiments on three benchmark datasets show that the DCGH method has comparable or even better performance compared to existing cross-modal retrieval methods. The code for the implementation of our DCGH framework is available at https://github.com/donnotnormal/DCGH.
FoxNet: A Multi-face Alignment Method
May 15, 2019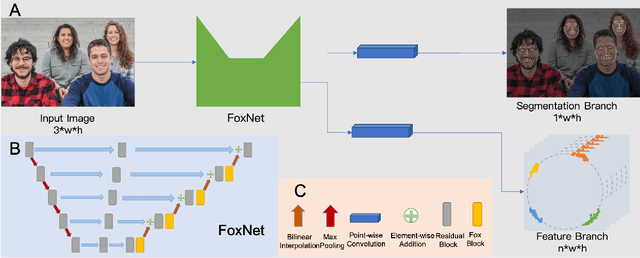

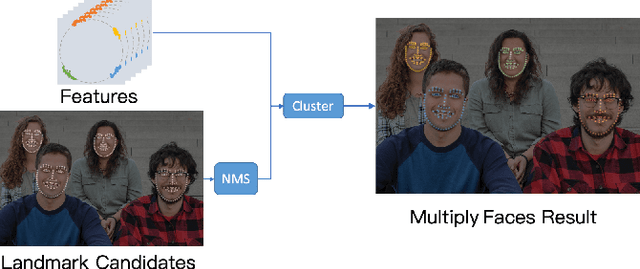
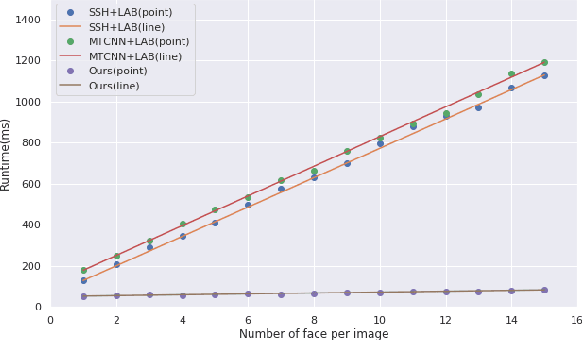
Multi-face alignment aims to identify geometry structures of multiple faces in an image, and its performance is essential for the many practical tasks, such as face recognition, face tracking, and face animation. In this work, we present a fast bottom-up multi-face alignment approach, which can simultaneously localize multi-person facial landmarks with high precision.In more detail, our bottom-up architecture maps the landmarks to the high-dimensional space with which landmarks of all faces are represented. By clustering the features belonging to the same face, our approach can align the multi-person facial landmarks synchronously.Extensive experiments show that our method can achieve high performance in the multi-face landmark alignment task while our model is extremely fast. Moreover, we propose a new multi-face dataset to compare the speed and precision of bottom-up face alignment method with top-down methods. Our dataset is publicly available at https://github.com/AISAResearch/FoxNet