 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALL-PET: A Low-resource and Low-shot PET Foundation Model in the Projection Domain
Sep 11, 2025Building large-scale foundation model for PET imaging is hindered by limited access to labeled data and insufficient computational resources. To overcome data scarcity and efficiency limitations, we propose ALL-PET, a low-resource, low-shot PET foundation model operating directly in the projection domain. ALL-PET leverages a latent diffusion model (LDM) with three key innovations. First, we design a Radon mask augmentation strategy (RMAS) that generates over 200,000 structurally diverse training samples by projecting randomized image-domain masks into sinogram space, significantly improving generalization with minimal data. This is extended by a dynamic multi-mask (DMM) mechanism that varies mask quantity and distribution, enhancing data diversity without added model complexity. Second, we implement positive/negative mask constraints to embed strict geometric consistency, reducing parameter burden while preserving generation quality. Third, we introduce transparent medical attention (TMA), a parameter-free, geometry-driven mechanism that enhances lesion-related regions in raw projection data. Lesion-focused attention maps are derived from coarse segmentation, covering both hypermetabolic and hypometabolic areas, and projected into sinogram space for physically consistent guidance. The system supports clinician-defined ROI adjustments, ensuring flexible, interpretable, and task-adaptive emphasis aligned with PET acquisition physics. Experimental results show ALL-PET achieves high-quality sinogram generation using only 500 samples, with performance comparable to models trained on larger datasets. ALL-PET generalizes across tasks including low-dose reconstruction, attenuation correction, delayed-frame prediction, and tracer separation, operating efficiently with memory use under 24GB.
E-BayesSAM: Efficient Bayesian Adaptation of SAM with Self-Optimizing KAN-Based Interpretation for Uncertainty-Aware Ultrasonic Segmentation
Aug 24, 2025Although the Segment Anything Model (SAM) has advanced medical image segmentation, its Bayesian adaptation for uncertainty-aware segmentation remains hindered by three key issues: (1) instability in Bayesian fine-tuning of large pre-trained SAMs; (2) high computation cost due to SAM's massive parameters; (3) SAM's black-box design limits interpretability. To overcome these, we propose E-BayesSAM, an efficient framework combining Token-wise Variational Bayesian Inference (T-VBI) for efficienty Bayesian adaptation and Self-Optimizing Kolmogorov-Arnold Network (SO-KAN) for improving interpretability. T-VBI innovatively reinterprets SAM's output tokens as dynamic probabilistic weights and reparameterizes them as latent variables without auxiliary training, enabling training-free VBI for uncertainty estimation. SO-KAN improves token prediction with learnable spline activations via self-supervised learning, providing insight to prune redundant tokens to boost efficiency and accuracy. Experiments on five ultrasound datasets demonstrated that E-BayesSAM achieves: (i) real-time inference (0.03s/image), (ii) superior segmentation accuracy (average DSC: Pruned E-BayesSAM's 89.0\% vs. E-BayesSAM's 88.0% vs. MedSAM's 88.3%), and (iii) identification of four critical tokens governing SAM's decisions. By unifying efficiency, reliability, and interpretability, E-BayesSAM bridges SAM's versatility with clinical needs, advancing deployment in safety-critical medical applications. The source code is available at https://github.com/mp31192/E-BayesSAM.
PRO: Projection Domain Synthesis for CT Imaging
Jun 16, 2025Synthesizing high quality CT images remains a signifi-cant challenge due to the limited availability of annotat-ed data and the complex nature of CT imaging. In this work, we present PRO, a novel framework that, to the best of our knowledge, is the first to perform CT image synthesis in the projection domain using latent diffusion models. Unlike previous approaches that operate in the image domain, PRO learns rich structural representa-tions from raw projection data and leverages anatomi-cal text prompts for controllable synthesis. This projec-tion domain strategy enables more faithful modeling of underlying imaging physics and anatomical structures. Moreover, PRO functions as a foundation model, capa-ble of generalizing across diverse downstream tasks by adjusting its generative behavior via prompt inputs. Experimental results demonstrated that incorporating our synthesized data significantly improves perfor-mance across multiple downstream tasks, including low-dose and sparse-view reconstruction, even with limited training data. These findings underscore the versatility and scalability of PRO in data generation for various CT applications. These results highlight the potential of projection domain synthesis as a powerful tool for data augmentation and robust CT imaging. Our source code is publicly available at: https://github.com/yqx7150/PRO.
Ordered-subsets Multi-diffusion Model for Sparse-view CT Reconstruction
May 15, 2025Score-based diffusion models have shown significant promise in the field of sparse-view CT reconstruction. However, the projection dataset is large and riddled with redundancy. Consequently, applying the diffusion model to unprocessed data results in lower learning effectiveness and higher learning difficulty, frequently leading to reconstructed images that lack fine details. To address these issues, we propose the ordered-subsets multi-diffusion model (OSMM) for sparse-view CT reconstruction. The OSMM innovatively divides the CT projection data into equal subsets and employs multi-subsets diffusion model (MSDM) to learn from each subset independently. This targeted learning approach reduces complexity and enhances the reconstruction of fine details. Furthermore, the integration of one-whole diffusion model (OWDM) with complete sinogram data acts as a global information constraint, which can reduce the possibility of generating erroneous or inconsistent sinogram information. Moreover, the OSMM's unsupervised learning framework provides strong robustness and generalizability, adapting seamlessly to varying sparsity levels of CT sinograms. This ensures consistent and reliable performance across different clinical scenarios. Experimental results demonstrate that OSMM outperforms traditional diffusion models in terms of image quality and noise resilience, offering a powerful and versatile solution for advanced CT imaging in sparse-view scenarios.
Sage Deer: A Super-Aligned Driving Generalist Is Your Copilot
May 15, 2025The intelligent driving cockpit, an important part of intelligent driving, needs to match different users' comfort, interaction, and safety needs. This paper aims to build a Super-Aligned and GEneralist DRiving agent, SAGE DeeR. Sage Deer achieves three highlights: (1) Super alignment: It achieves different reactions according to different people's preferences and biases. (2) Generalist: It can understand the multi-view and multi-mode inputs to reason the user's physiological indicators, facial emotions, hand movements, body movements, driving scenarios, and behavioral decisions. (3) Self-Eliciting: It can elicit implicit thought chains in the language space to further increase generalist and super-aligned abilities. Besides, we collected multiple data sets and built a large-scale benchmark. This benchmark measures the deer's perceptual decision-making ability and the super alignment's accuracy.
Diffusion Transformer Meets Random Masks: An Advanced PET Reconstruction Framework
Mar 11, 2025Deep learning has significantly advanced PET image re-construction, achieving remarkable improvements in image quality through direct training on sinogram or image data. Traditional methods often utilize masks for inpainting tasks, but their incorporation into PET reconstruction frameworks introduces transformative potential. In this study, we pro-pose an advanced PET reconstruction framework called Diffusion tRansformer mEets rAndom Masks (DREAM). To the best of our knowledge, this is the first work to integrate mask mechanisms into both the sinogram domain and the latent space, pioneering their role in PET reconstruction and demonstrating their ability to enhance reconstruction fidelity and efficiency. The framework employs a high-dimensional stacking approach, transforming masked data from two to three dimensions to expand the solution space and enable the model to capture richer spatial rela-tionships. Additionally, a mask-driven latent space is de-signed to accelerate the diffusion process by leveraging sinogram-driven and mask-driven compact priors, which reduce computational complexity while preserving essen-tial data characteristics. A hierarchical masking strategy is also introduced, guiding the model from focusing on fi-ne-grained local details in the early stages to capturing broader global patterns over time. This progressive ap-proach ensures a balance between detailed feature preservation and comprehensive context understanding. Experimental results demonstrate that DREAM not only improves the overall quality of reconstructed PET images but also preserves critical clinical details, highlighting its potential to advance PET imaging technology. By inte-grating compact priors and hierarchical masking, DREAM offers a promising and efficient avenue for future research and application in PET imaging. The open-source code is available at: https://github.com/yqx7150/DREAM.
RED: Residual Estimation Diffusion for Low-Dose PET Sinogram Reconstruction
Nov 08, 2024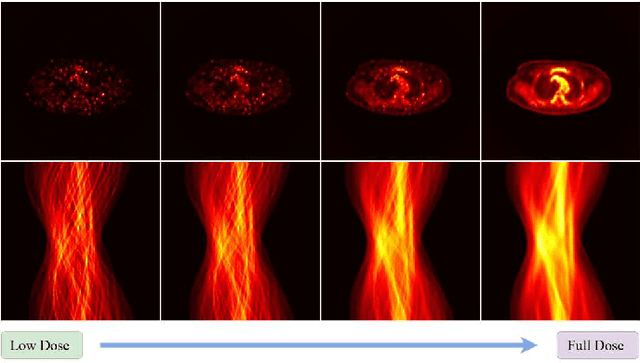

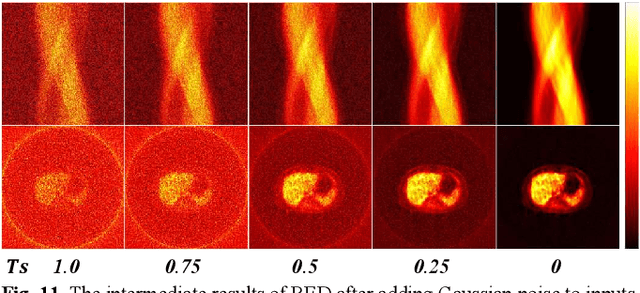
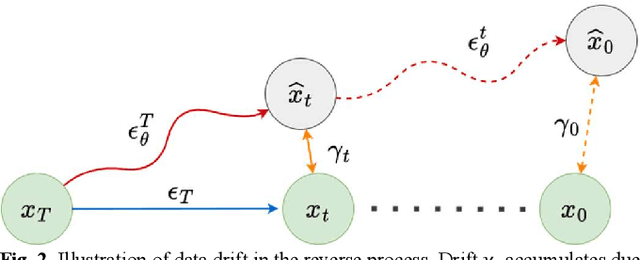
Recent advances in diffusion models have demonstrated exceptional performance in generative tasks across vari-ous fields. In positron emission tomography (PET), the reduction in tracer dose leads to information loss in sino-grams. Using diffusion models to reconstruct missing in-formation can improve imaging quality. Traditional diffu-sion models effectively use Gaussian noise for image re-constructions. However, in low-dose PET reconstruction, Gaussian noise can worsen the already sparse data by introducing artifacts and inconsistencies. To address this issue, we propose a diffusion model named residual esti-mation diffusion (RED). From the perspective of diffusion mechanism, RED uses the residual between sinograms to replace Gaussian noise in diffusion process, respectively sets the low-dose and full-dose sinograms as the starting point and endpoint of reconstruction. This mechanism helps preserve the original information in the low-dose sinogram, thereby enhancing reconstruction reliability. From the perspective of data consistency, RED introduces a drift correction strategy to reduce accumulated prediction errors during the reverse process. Calibrating the inter-mediate results of reverse iterations helps maintain the data consistency and enhances the stability of reconstruc-tion process. Experimental results show that RED effec-tively improves the quality of low-dose sinograms as well as the reconstruction results. The code is available at: https://github.com/yqx7150/RED.
Precise Drive with VLM: First Prize Solution for PRCV 2024 Drive LM challenge
Nov 05, 2024



This technical report outlines the methodologies we applied for the PRCV Challenge, focusing on cognition and decision-making in driving scenarios. We employed InternVL-2.0, a pioneering open-source multi-modal model, and enhanced it by refining both the model input and training methodologies. For the input data, we strategically concatenated and formatted the multi-view images. It is worth mentioning that we utilized the coordinates of the original images without transformation. In terms of model training, we initially pre-trained the model on publicly available autonomous driving scenario datasets to bolster its alignment capabilities of the challenge tasks, followed by fine-tuning on the DriveLM-nuscenes Dataset. During the fine-tuning phase, we innovatively modified the loss function to enhance the model's precision in predicting coordinate values. These approaches ensure that our model possesses advanced cognitive and decision-making capabilities in driving scenarios. Consequently, our model achieved a score of 0.6064, securing the first prize on the competition's final results.
VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding
Oct 11, 2024Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding, which hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic \underline{V}id\underline{E}o-text annotation pipeline to generate captions with \underline{R}el\underline{I}able \underline{FI}n\underline{E}-grained statics and \underline{D}ynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR. Code and Datasets are in \href{https://github.com/hlchen23/VERIFIED}{https://github.com/hlchen23/VERIFIED}.
Diffusion Transformer Model With Compact Prior for Low-dose PET Reconstruction
Jul 01, 2024Positron emission tomography (PET) is an advanced medical imaging technique that plays a crucial role in non-invasive clinical diagnosis. However, while reducing radiation exposure through low-dose PET scans is beneficial for patient safety, it often results in insufficient statistical data. This scarcity of data poses significant challenges for accurately reconstructing high-quality images, which are essential for reliable diagnostic outcomes. In this research, we propose a diffusion transformer model (DTM) guided by joint compact prior (JCP) to enhance the reconstruction quality of low-dose PET imaging. In light of current research findings, we present a pioneering PET reconstruction model that integrates diffusion and transformer models for joint optimization. This model combines the powerful distribution mapping abilities of diffusion models with the capacity of transformers to capture long-range dependencies, offering significant advantages for low-dose PET reconstruction. Additionally, the incorporation of the lesion refining block and penalized weighted least squares (PWLS) enhance the recovery capability of lesion regions and preserves detail information, solving blurring problems in lesion areas and texture details of most deep learning frameworks. Experimental results demonstrate the effectiveness of DTM in enhancing image quality and preserving critical clinical information for low-dose PET scans. Our approach not only reduces radiation exposure risks but also provides a more reliable PET imaging tool for early disease detection and patient management.