 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoRouter: Query-Adaptive Dual Routing for Efficient Long-Video Understanding
May 07, 2026Video large multimodal models increasingly face a scalability bottleneck: long videos produce excessively long visual-token sequences, which sharply increase memory and latency during inference. While existing compression methods are effective in specific settings, most are either weakly query-aware or apply a fixed compression policy across frames, proving suboptimal when visual evidence is unevenly distributed over time. To address this, we present VideoRouter, a query-adaptive dual-router framework built on InternVL for budgeted evidence allocation. The Semantic Router predicts the dominant allocation policy, choosing between broad temporal coverage and adaptive high-resolution preservation, while the Image Router uses early LLM layers to score frame relevance. This enables aggressive compression on less relevant frames while preserving detail on critical evidence frames. To train both routers, we build Video-QTR-10K for allocation-policy supervision and Video-FLR-200K for frame-relevance supervision. Experiments on VideoMME, MLVU, and LongVideoBench show that VideoRouter consistently improves over the InternVL baseline under comparable or lower budgets, achieving up to a 67.9% token reduction.
Dynamic Pondering Sparsity-aware Mixture-of-Experts Transformer for Event Stream based Visual Object Tracking
May 07, 2026Despite significant progress, RGB-based trackers remain vulnerable to challenging imaging conditions, such as low illumination and fast motion. Event cameras offer a promising alternative by asynchronously capturing pixel-wise brightness changes, providing high dynamic range and high temporal resolution. However, existing event-based trackers often neglect the intrinsic spatial sparsity and temporal density of event data, while relying on a single fixed temporal-window sampling strategy that is suboptimal under varying motion dynamics. In this paper, we propose an event sparsity-aware tracking framework that explicitly models event-density variations across multiple temporal scales. Specifically, the proposed framework progressively injects sparse, medium-density, and dense event search regions into a three-stage Vision Transformer backbone, enabling hierarchical multi-density feature learning. Furthermore, we introduce a sparsity-aware Mixture-of-Experts module to encourage expert specialization under different sparsity patterns, and design a dynamic pondering strategy to adaptively adjust the inference depth according to tracking difficulty. Extensive experiments on FE240hz, COESOT, and EventVOT demonstrate that the proposed approach achieves a favorable trade-off between tracking accuracy and computational efficiency. The source code will be released on https://github.com/Event-AHU/OpenEvTracking.
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
Apr 28, 2026On-policy distillation (OPD) has shown strong potential for transferring reasoning ability from frontier or domain-specific models to smaller students. While effective on static single-turn tasks, its behavior in multi-turn agent settings remains underexplored. In this work, we identify a key limitation of vanilla OPD in such settings, which we term Trajectory-Level KL Instability. Specifically, we observe that KL divergence increases together with a drop in success rate, and even after convergence, the KL remains high, leading to unstable training. This instability arises from inter-turn error compounding: as errors accumulate, the student is driven beyond the teacher's effective support, rendering the supervision signal unreliable. To address this, we propose TCOD (Temporal Curriculum On-Policy Distillation), a simple yet effective framework that controls the trajectory depth exposed to the student and progressively expands it from short to long with a curriculum schedule. Experimental results across four student-teacher pairs on three multi-turn agent benchmarks (ALFWorld, WebShop, ScienceWorld) show that TCOD mitigates KL escalation and enhances KL stability throughout training, improving agent performance by up to 18 points over vanilla OPD. Further evaluations show that TCOD can even surpass the teacher's performance and generalize to tasks on which the teacher fails.
Polynomial Expansion Rank Adaptation: Enhancing Low-Rank Fine-Tuning with High-Order Interactions
Apr 12, 2026Low-rank adaptation (LoRA) is a widely used strategy for efficient fine-tuning of large language models (LLMs), but its strictly linear structure fundamentally limits expressive capacity. The bilinear formulation of weight updates captures only first-order dependencies between low-rank factors, restricting the modeling of nonlinear and higher-order parameter interactions. In this paper, we propose Polynomial Expansion Rank Adaptation (PERA), a novel method that introduces structured polynomial expansion directly into the low-rank factor space. By expanding each low-rank factor to synthesize high-order interaction terms before composition, PERA transforms the adaptation space into a polynomial manifold capable of modeling richer nonlinear coupling without increasing rank or inference cost. We provide theoretical analysis demonstrating that PERA offers enhanced expressive capacity and more effective feature utilization compare to existing linear adaptation approaches. Empirically, PERA consistently outperforms state-of-the-art methods across diverse benchmarks. Notably, our experiments show that incorporating high-order nonlinear components particularly square terms is crucial for enhancing expressive capacity and maintaining strong and robust performance under various rank settings. Our code is available at https://github.com/zhangwenhao6/PERA
HiMAC: Hierarchical Macro-Micro Learning for Long-Horizon LLM Agents
Mar 01, 2026Large language model (LLM) agents have recently demonstrated strong capabilities in interactive decision-making, yet they remain fundamentally limited in long-horizon tasks that require structured planning and reliable execution. Existing approaches predominantly rely on flat autoregressive policies, where high-level reasoning and low-level actions are generated within a single token sequence, leading to inefficient exploration and severe error propagation over extended trajectories. In this work, we propose HiMAC, a hierarchical agentic RL framework that explicitly decomposes long-horizon decision-making into macro-level planning and micro-level execution. HiMAC models reasoning as a structured blueprint generation process followed by goal-conditioned action execution, enabling robust long-horizon planning within LLM-based agents. To train this hierarchy efficiently, we introduce a critic-free hierarchical policy optimization paradigm that extends group-based reinforcement learning to bi-level structures through hierarchical relative advantage estimation. Furthermore, we propose an iterative co-evolution training strategy that alternates between planner exploration and executor adaptation, mitigating the non-stationarity inherent in hierarchical learning. Extensive experiments on ALFWorld, WebShop, and Sokoban demonstrate that HiMAC consistently outperforms strong prompting and reinforcement learning baselines, achieving state-of-the-art performance and substantially improved sample efficiency across both text-based and visually grounded environments. Our results show that introducing structured hierarchy, rather than increasing model scale alone, is a key factor for enabling robust long-horizon agentic intelligence.
On the Entropy Dynamics in Reinforcement Fine-Tuning of Large Language Models
Feb 03, 2026Entropy serves as a critical metric for measuring the diversity of outputs generated by large language models (LLMs), providing valuable insights into their exploration capabilities. While recent studies increasingly focus on monitoring and adjusting entropy to better balance exploration and exploitation in reinforcement fine-tuning (RFT), a principled understanding of entropy dynamics during this process is yet to be thoroughly investigated. In this paper, we establish a theoretical framework for analyzing the entropy dynamics during the RFT process, which begins with a discriminant expression that quantifies entropy change under a single logit update. This foundation enables the derivation of a first-order expression for entropy change, which can be further extended to the update formula of Group Relative Policy Optimization (GRPO). The corollaries and insights drawn from the theoretical analysis inspire the design of entropy control methods, and also offer a unified lens for interpreting various entropy-based methods in existing studies. We provide empirical evidence to support the main conclusions of our analysis and demonstrate the effectiveness of the derived entropy-discriminator clipping methods. This study yields novel insights into RFT training dynamics, providing theoretical support and practical strategies for optimizing the exploration-exploitation balance during LLM fine-tuning.
IntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning
Feb 03, 2026Deep Research (DR) agents extend Large Language Models (LLMs) beyond parametric knowledge by autonomously retrieving and synthesizing evidence from large web corpora into long-form reports, enabling a long-horizon agentic paradigm. However, unlike real-time conversational assistants, DR is computationally expensive and time-consuming, creating an autonomy-interaction dilemma: high autonomy on ambiguous user queries often leads to prolonged execution with unsatisfactory outcomes. To address this, we propose IntentRL, a framework that trains proactive agents to clarify latent user intents before starting long-horizon research. To overcome the scarcity of open-ended research data, we introduce a scalable pipeline that expands a few seed samples into high-quality dialogue turns via a shallow-to-deep intent refinement graph. We further adopt a two-stage reinforcement learning (RL) strategy: Stage I applies RL on offline dialogues to efficiently learn general user-interaction behavior, while Stage II uses the trained agent and a user simulator for online rollouts to strengthen adaptation to diverse user feedback. Extensive experiments show that IntentRL significantly improves both intent hit rate and downstream task performance, outperforming the built-in clarify modules of closed-source DR agents and proactive LLM baselines.
VideoCuRL: Video Curriculum Reinforcement Learning with Orthogonal Difficulty Decomposition
Dec 31, 2025Reinforcement Learning (RL) is crucial for empowering VideoLLMs with complex spatiotemporal reasoning. However, current RL paradigms predominantly rely on random data shuffling or naive curriculum strategies based on scalar difficulty metrics. We argue that scalar metrics fail to disentangle two orthogonal challenges in video understanding: Visual Temporal Perception Load and Cognitive Reasoning Depth. To address this, we propose VideoCuRL, a novel framework that decomposes difficulty into these two axes. We employ efficient, training-free proxies, optical flow and keyframe entropy for visual complexity, Calibrated Surprisal for cognitive complexity, to map data onto a 2D curriculum grid. A competence aware Diagonal Wavefront strategy then schedules training from base alignment to complex reasoning. Furthermore, we introduce Dynamic Sparse KL and Structured Revisiting to stabilize training against reward collapse and catastrophic forgetting. Extensive experiments show that VideoCuRL surpasses strong RL baselines on reasoning (+2.5 on VSI-Bench) and perception (+2.9 on VideoMME) tasks. Notably, VideoCuRL eliminates the prohibitive inference overhead of generation-based curricula, offering a scalable solution for robust video post-training.
StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Dec 26, 2025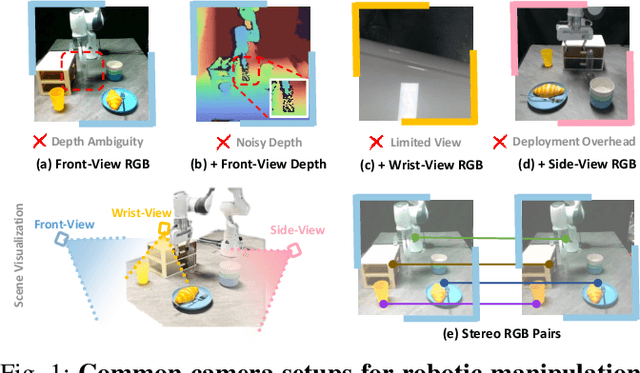
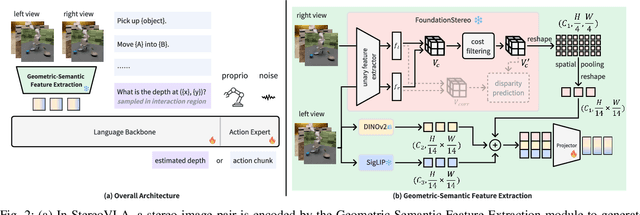
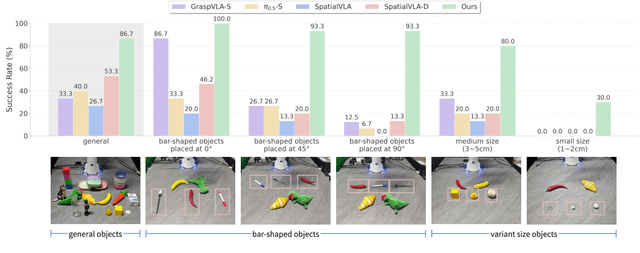
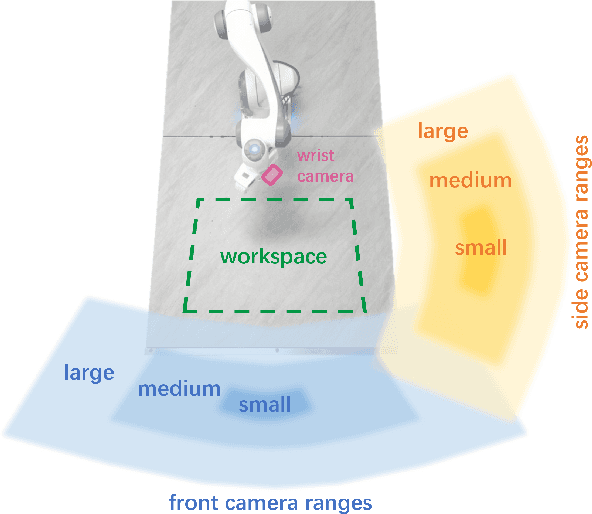
Stereo cameras closely mimic human binocular vision, providing rich spatial cues critical for precise robotic manipulation. Despite their advantage, the adoption of stereo vision in vision-language-action models (VLAs) remains underexplored. In this work, we present StereoVLA, a VLA model that leverages rich geometric cues from stereo vision. We propose a novel Geometric-Semantic Feature Extraction module that utilizes vision foundation models to extract and fuse two key features: 1) geometric features from subtle stereo-view differences for spatial perception; 2) semantic-rich features from the monocular view for instruction following. Additionally, we propose an auxiliary Interaction-Region Depth Estimation task to further enhance spatial perception and accelerate model convergence. Extensive experiments show that our approach outperforms baselines by a large margin in diverse tasks under the stereo setting and demonstrates strong robustness to camera pose variations.
DiSE: A diffusion probabilistic model for automatic structure elucidation of organic compounds
Oct 30, 2025Automatic structure elucidation is essential for self-driving laboratories as it enables the system to achieve truly autonomous. This capability closes the experimental feedback loop, ensuring that machine learning models receive reliable structure information for real-time decision-making and optimization. Herein, we present DiSE, an end-to-end diffusion-based generative model that integrates multiple spectroscopic modalities, including MS, 13C and 1H chemical shifts, HSQC, and COSY, to achieve automated yet accurate structure elucidation of organic compounds. By learning inherent correlations among spectra through data-driven approaches, DiSE achieves superior accuracy, strong generalization across chemically diverse datasets, and robustness to experimental data despite being trained on calculated spectra. DiSE thus represents a significant advance toward fully automated structure elucidation, with broad potential in natural product research, drug discovery, and self-driving laboratories.