 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridSplat: Fast Reflection-baked Gaussian Tracing using Hybrid Splatting
Dec 15, 2025
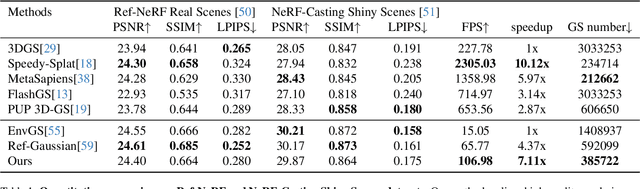


Rendering complex reflection of real-world scenes using 3D Gaussian splatting has been a quite promising solution for photorealistic novel view synthesis, but still faces bottlenecks especially in rendering speed and memory storage. This paper proposes a new Hybrid Splatting(HybridSplat) mechanism for Gaussian primitives. Our key idea is a new reflection-baked Gaussian tracing, which bakes the view-dependent reflection within each Gaussian primitive while rendering the reflection using tile-based Gaussian splatting. Then we integrate the reflective Gaussian primitives with base Gaussian primitives using a unified hybrid splatting framework for high-fidelity scene reconstruction. Moreover, we further introduce a pipeline-level acceleration for the hybrid splatting, and reflection-sensitive Gaussian pruning to reduce the model size, thus achieving much faster rendering speed and lower memory storage while preserving the reflection rendering quality. By extensive evaluation, our HybridSplat accelerates about 7x rendering speed across complex reflective scenes from Ref-NeRF, NeRF-Casting with 4x fewer Gaussian primitives than similar ray-tracing based Gaussian splatting baselines, serving as a new state-of-the-art method especially for complex reflective scenes.
Multi-level Dynamic Style Transfer for NeRFs
Oct 01, 2025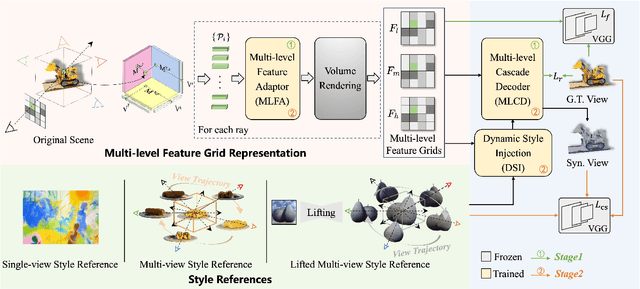
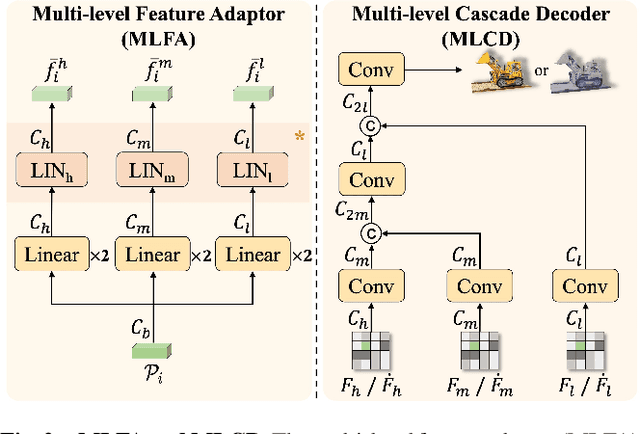


As the application of neural radiance fields (NeRFs) in various 3D vision tasks continues to expand, numerous NeRF-based style transfer techniques have been developed. However, existing methods typically integrate style statistics into the original NeRF pipeline, often leading to suboptimal results in both content preservation and artistic stylization. In this paper, we present multi-level dynamic style transfer for NeRFs (MDS-NeRF), a novel approach that reengineers the NeRF pipeline specifically for stylization and incorporates an innovative dynamic style injection module. Particularly, we propose a multi-level feature adaptor that helps generate a multi-level feature grid representation from the content radiance field, effectively capturing the multi-scale spatial structure of the scene. In addition, we present a dynamic style injection module that learns to extract relevant style features and adaptively integrates them into the content patterns. The stylized multi-level features are then transformed into the final stylized view through our proposed multi-level cascade decoder. Furthermore, we extend our 3D style transfer method to support omni-view style transfer using 3D style references. Extensive experiments demonstrate that MDS-NeRF achieves outstanding performance for 3D style transfer, preserving multi-scale spatial structures while effectively transferring stylistic characteristics.
Aerial Path Planning for Urban Geometry and Texture Co-Capture
Sep 26, 2025Recent advances in image acquisition and scene reconstruction have enabled the generation of high-quality structural urban scene geometry, given sufficient site information. However, current capture techniques often overlook the crucial importance of texture quality, resulting in noticeable visual artifacts in the textured models. In this work, we introduce the urban geometry and texture co-capture problem under limited prior knowledge before a site visit. The only inputs are a 2D building contour map of the target area and a safe flying altitude above the buildings. We propose an innovative aerial path planning framework designed to co-capture images for reconstructing both structured geometry and high-fidelity textures. To evaluate and guide view planning, we introduce a comprehensive texture quality assessment system, including two novel metrics tailored for building facades. Firstly, our method generates high-quality vertical dipping views and horizontal planar views to effectively capture both geometric and textural details. A multi-objective optimization strategy is then proposed to jointly maximize texture fidelity, improve geometric accuracy, and minimize the cost associated with aerial views. Furthermore, we present a sequential path planning algorithm that accounts for texture consistency during image capture. Extensive experiments on large-scale synthetic and real-world urban datasets demonstrate that our approach effectively produces image sets suitable for concurrent geometric and texture reconstruction, enabling the creation of realistic, textured scene proxies at low operational cost.
GTS-LUM: Reshaping User Behavior Modeling with LLMs in Telecommunications Industry
Apr 09, 2025

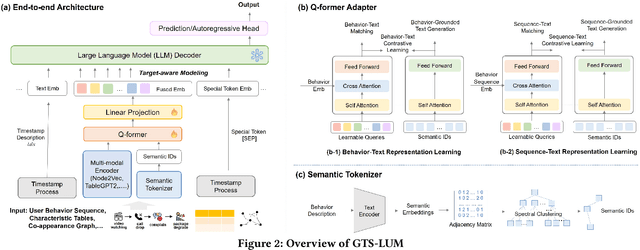

As telecommunication service providers shifting their focus to analyzing user behavior for package design and marketing interventions, a critical challenge lies in developing a unified, end-to-end framework capable of modeling long-term and periodic user behavior sequences with diverse time granularities, multi-modal data inputs, and heterogeneous labels. This paper introduces GTS-LUM, a novel user behavior model that redefines modeling paradigms in telecommunication settings. GTS-LUM adopts a (multi-modal) encoder-adapter-LLM decoder architecture, enhanced with several telecom-specific innovations. Specifically, the model incorporates an advanced timestamp processing method to handle varying time granularities. It also supports multi-modal data inputs -- including structured tables and behavior co-occurrence graphs -- and aligns these with semantic information extracted by a tokenizer using a Q-former structure. Additionally, GTS-LUM integrates a front-placed target-aware mechanism to highlight historical behaviors most relevant to the target. Extensive experiments on industrial dataset validate the effectiveness of this end-to-end framework and also demonstrate that GTS-LUM outperforms LLM4Rec approaches which are popular in recommendation systems, offering an effective and generalizing solution for user behavior modeling in telecommunications.
HyperGCT: A Dynamic Hyper-GNN-Learned Geometric Constraint for 3D Registration
Mar 04, 2025



Geometric constraints between feature matches are critical in 3D point cloud registration problems. Existing approaches typically model unordered matches as a consistency graph and sample consistent matches to generate hypotheses. However, explicit graph construction introduces noise, posing great challenges for handcrafted geometric constraints to render consistency among matches. To overcome this, we propose HyperGCT, a flexible dynamic Hyper-GNN-learned geometric constraint that leverages high-order consistency among 3D correspondences. To our knowledge, HyperGCT is the first method that mines robust geometric constraints from dynamic hypergraphs for 3D registration. By dynamically optimizing the hypergraph through vertex and edge feature aggregation, HyperGCT effectively captures the correlations among correspondences, leading to accurate hypothesis generation. Extensive experiments on 3DMatch, 3DLoMatch, KITTI-LC, and ETH show that HyperGCT achieves state-of-the-art performance. Furthermore, our method is robust to graph noise, demonstrating a significant advantage in terms of generalization. The code will be released.
Revisiting CAD Model Generation by Learning Raster Sketch
Mar 02, 2025The integration of deep generative networks into generating Computer-Aided Design (CAD) models has garnered increasing attention over recent years. Traditional methods often rely on discrete sequences of parametric line/curve segments to represent sketches. Differently, we introduce RECAD, a novel framework that generates Raster sketches and 3D Extrusions for CAD models. Representing sketches as raster images offers several advantages over discrete sequences: 1) it breaks the limitations on the types and numbers of lines/curves, providing enhanced geometric representation capabilities; 2) it enables interpolation within a continuous latent space; and 3) it allows for more intuitive user control over the output. Technically, RECAD employs two diffusion networks: the first network generates extrusion boxes conditioned on the number and types of extrusions, while the second network produces sketch images conditioned on these extrusion boxes. By combining these two networks, RECAD effectively generates sketch-and-extrude CAD models, offering a more robust and intuitive approach to CAD model generation. Experimental results indicate that RECAD achieves strong performance in unconditional generation, while also demonstrating effectiveness in conditional generation and output editing.
DehazeGS: Seeing Through Fog with 3D Gaussian Splatting
Jan 07, 2025

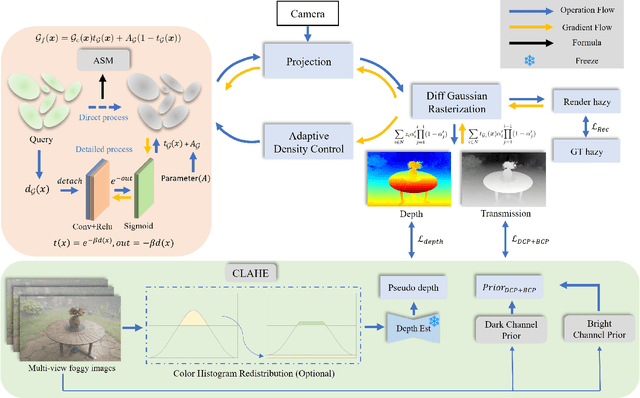

Current novel view synthesis tasks primarily rely on high-quality and clear images. However, in foggy scenes, scattering and attenuation can significantly degrade the reconstruction and rendering quality. Although NeRF-based dehazing reconstruction algorithms have been developed, their use of deep fully connected neural networks and per-ray sampling strategies leads to high computational costs. Moreover, NeRF's implicit representation struggles to recover fine details from hazy scenes. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction by explicitly modeling point clouds into 3D Gaussians. In this paper, we propose leveraging the explicit Gaussian representation to explain the foggy image formation process through a physically accurate forward rendering process. We introduce DehazeGS, a method capable of decomposing and rendering a fog-free background from participating media using only muti-view foggy images as input. We model the transmission within each Gaussian distribution to simulate the formation of fog. During this process, we jointly learn the atmospheric light and scattering coefficient while optimizing the Gaussian representation of the hazy scene. In the inference stage, we eliminate the effects of scattering and attenuation on the Gaussians and directly project them onto a 2D plane to obtain a clear view. Experiments on both synthetic and real-world foggy datasets demonstrate that DehazeGS achieves state-of-the-art performance in terms of both rendering quality and computational efficiency.
TwinTex: Geometry-aware Texture Generation for Abstracted 3D Architectural Models
Sep 20, 2023Coarse architectural models are often generated at scales ranging from individual buildings to scenes for downstream applications such as Digital Twin City, Metaverse, LODs, etc. Such piece-wise planar models can be abstracted as twins from 3D dense reconstructions. However, these models typically lack realistic texture relative to the real building or scene, making them unsuitable for vivid display or direct reference. In this paper, we present TwinTex, the first automatic texture mapping framework to generate a photo-realistic texture for a piece-wise planar proxy. Our method addresses most challenges occurring in such twin texture generation. Specifically, for each primitive plane, we first select a small set of photos with greedy heuristics considering photometric quality, perspective quality and facade texture completeness. Then, different levels of line features (LoLs) are extracted from the set of selected photos to generate guidance for later steps. With LoLs, we employ optimization algorithms to align texture with geometry from local to global. Finally, we fine-tune a diffusion model with a multi-mask initialization component and a new dataset to inpaint the missing region. Experimental results on many buildings, indoor scenes and man-made objects of varying complexity demonstrate the generalization ability of our algorithm. Our approach surpasses state-of-the-art texture mapping methods in terms of high-fidelity quality and reaches a human-expert production level with much less effort. Project page: https://vcc.tech/research/2023/TwinTex.
SECAD-Net: Self-Supervised CAD Reconstruction by Learning Sketch-Extrude Operations
Mar 19, 2023

Reverse engineering CAD models from raw geometry is a classic but strenuous research problem. Previous learning-based methods rely heavily on labels due to the supervised design patterns or reconstruct CAD shapes that are not easily editable. In this work, we introduce SECAD-Net, an end-to-end neural network aimed at reconstructing compact and easy-to-edit CAD models in a self-supervised manner. Drawing inspiration from the modeling language that is most commonly used in modern CAD software, we propose to learn 2D sketches and 3D extrusion parameters from raw shapes, from which a set of extrusion cylinders can be generated by extruding each sketch from a 2D plane into a 3D body. By incorporating the Boolean operation (i.e., union), these cylinders can be combined to closely approximate the target geometry. We advocate the use of implicit fields for sketch representation, which allows for creating CAD variations by interpolating latent codes in the sketch latent space. Extensive experiments on both ABC and Fusion 360 datasets demonstrate the effectiveness of our method, and show superiority over state-of-the-art alternatives including the closely related method for supervised CAD reconstruction. We further apply our approach to CAD editing and single-view CAD reconstruction. The code is released at https://github.com/BunnySoCrazy/SECAD-Net.
SARNet: Semantic Augmented Registration of Large-Scale Urban Point Clouds
Jun 27, 2022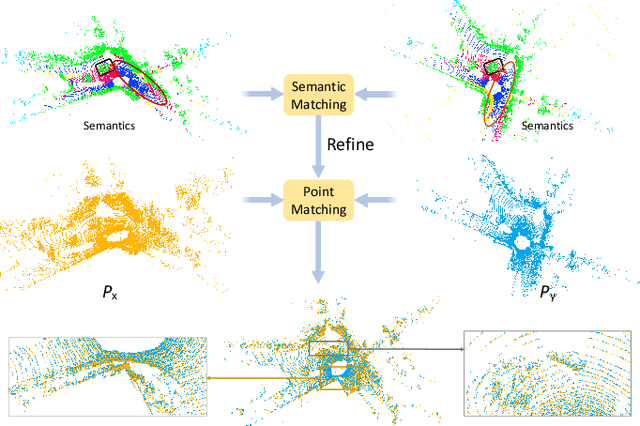
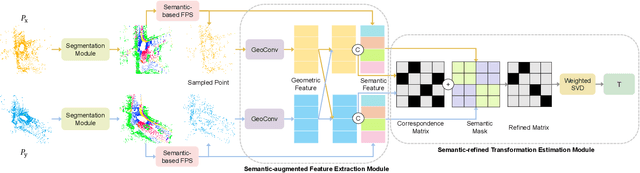
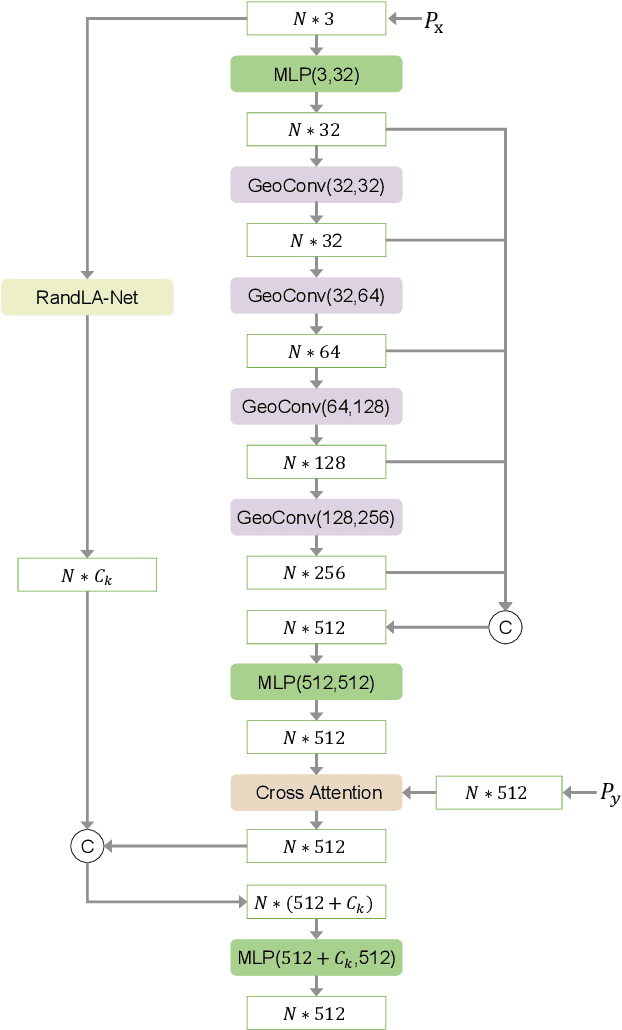
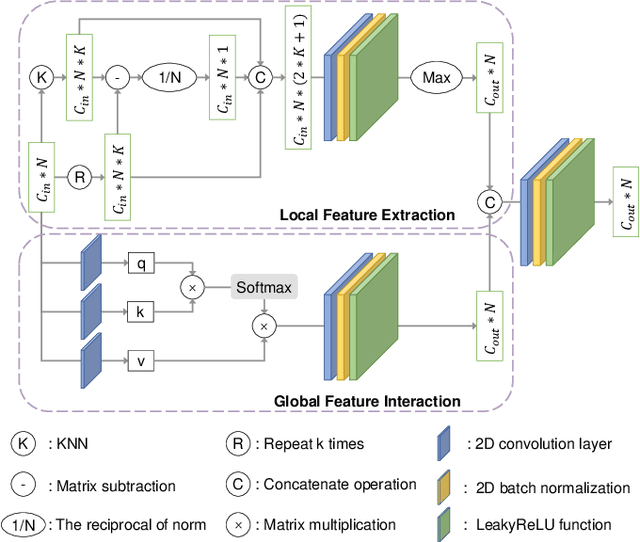
Registering urban point clouds is a quite challenging task due to the large-scale, noise and data incompleteness of LiDAR scanning data. In this paper, we propose SARNet, a novel semantic augmented registration network aimed at achieving efficient registration of urban point clouds at city scale. Different from previous methods that construct correspondences only in the point-level space, our approach fully exploits semantic features as assistance to improve registration accuracy. Specifically, we extract per-point semantic labels with advanced semantic segmentation networks and build a prior semantic part-to-part correspondence. Then we incorporate the semantic information into a learning-based registration pipeline, consisting of three core modules: a semantic-based farthest point sampling module to efficiently filter out outliers and dynamic objects; a semantic-augmented feature extraction module for learning more discriminative point descriptors; a semantic-refined transformation estimation module that utilizes prior semantic matching as a mask to refine point correspondences by reducing false matching for better convergence. We evaluate the proposed SARNet extensively by using real-world data from large regions of urban scenes and comparing it with alternative methods. The code is available at https://github.com/WinterCodeForEverything/SARNet.