 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMamba: Unified Spatial-Channel Representation Learning with Group-Efficient Mamba for LiDAR-based 3D Object Detection
Mar 15, 2025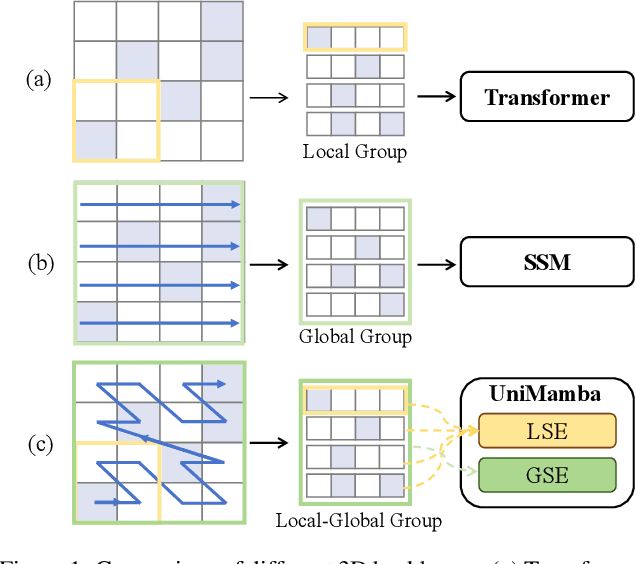
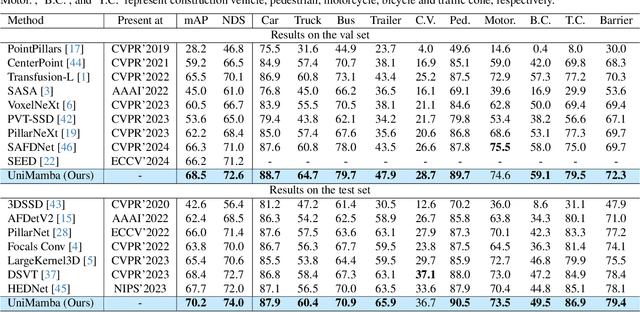
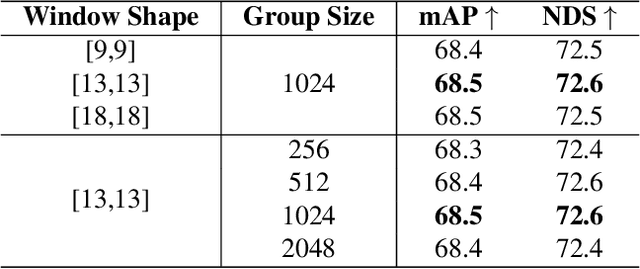
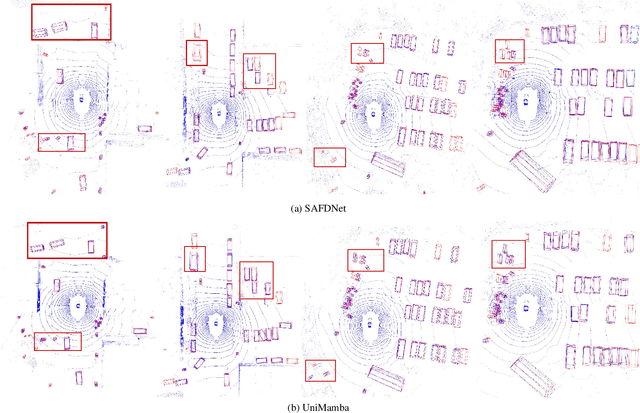
Recent advances in LiDAR 3D detection have demonstrated the effectiveness of Transformer-based frameworks in capturing the global dependencies from point cloud spaces, which serialize the 3D voxels into the flattened 1D sequence for iterative self-attention. However, the spatial structure of 3D voxels will be inevitably destroyed during the serialization process. Besides, due to the considerable number of 3D voxels and quadratic complexity of Transformers, multiple sequences are grouped before feeding to Transformers, leading to a limited receptive field. Inspired by the impressive performance of State Space Models (SSM) achieved in the field of 2D vision tasks, in this paper, we propose a novel Unified Mamba (UniMamba), which seamlessly integrates the merits of 3D convolution and SSM in a concise multi-head manner, aiming to perform "local and global" spatial context aggregation efficiently and simultaneously. Specifically, a UniMamba block is designed which mainly consists of spatial locality modeling, complementary Z-order serialization and local-global sequential aggregator. The spatial locality modeling module integrates 3D submanifold convolution to capture the dynamic spatial position embedding before serialization. Then the efficient Z-order curve is adopted for serialization both horizontally and vertically. Furthermore, the local-global sequential aggregator adopts the channel grouping strategy to efficiently encode both "local and global" spatial inter-dependencies using multi-head SSM. Additionally, an encoder-decoder architecture with stacked UniMamba blocks is formed to facilitate multi-scale spatial learning hierarchically. Extensive experiments are conducted on three popular datasets: nuScenes, Waymo and Argoverse 2. Particularly, our UniMamba achieves 70.2 mAP on the nuScenes dataset.
HyperGCT: A Dynamic Hyper-GNN-Learned Geometric Constraint for 3D Registration
Mar 04, 2025



Geometric constraints between feature matches are critical in 3D point cloud registration problems. Existing approaches typically model unordered matches as a consistency graph and sample consistent matches to generate hypotheses. However, explicit graph construction introduces noise, posing great challenges for handcrafted geometric constraints to render consistency among matches. To overcome this, we propose HyperGCT, a flexible dynamic Hyper-GNN-learned geometric constraint that leverages high-order consistency among 3D correspondences. To our knowledge, HyperGCT is the first method that mines robust geometric constraints from dynamic hypergraphs for 3D registration. By dynamically optimizing the hypergraph through vertex and edge feature aggregation, HyperGCT effectively captures the correlations among correspondences, leading to accurate hypothesis generation. Extensive experiments on 3DMatch, 3DLoMatch, KITTI-LC, and ETH show that HyperGCT achieves state-of-the-art performance. Furthermore, our method is robust to graph noise, demonstrating a significant advantage in terms of generalization. The code will be released.