 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025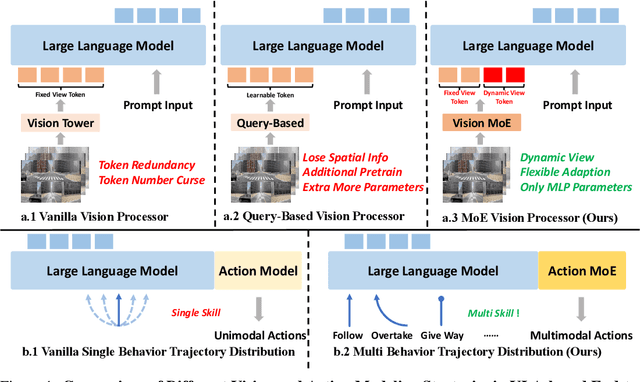
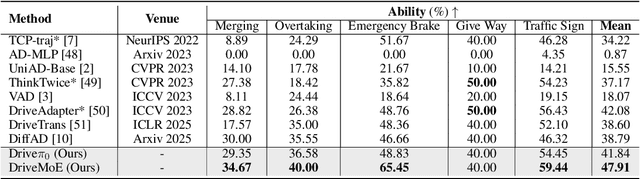
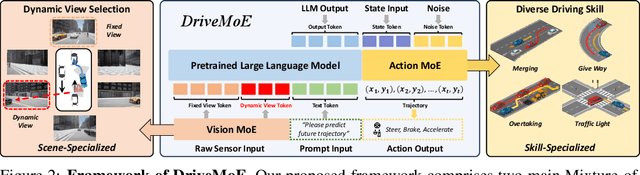
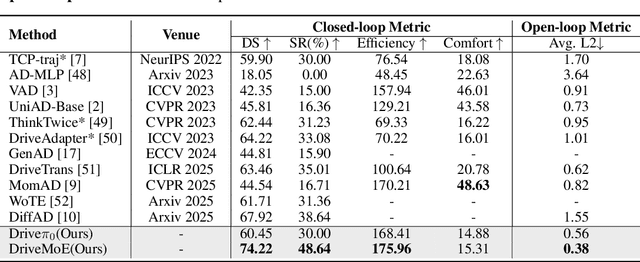
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
UniMamba: Unified Spatial-Channel Representation Learning with Group-Efficient Mamba for LiDAR-based 3D Object Detection
Mar 15, 2025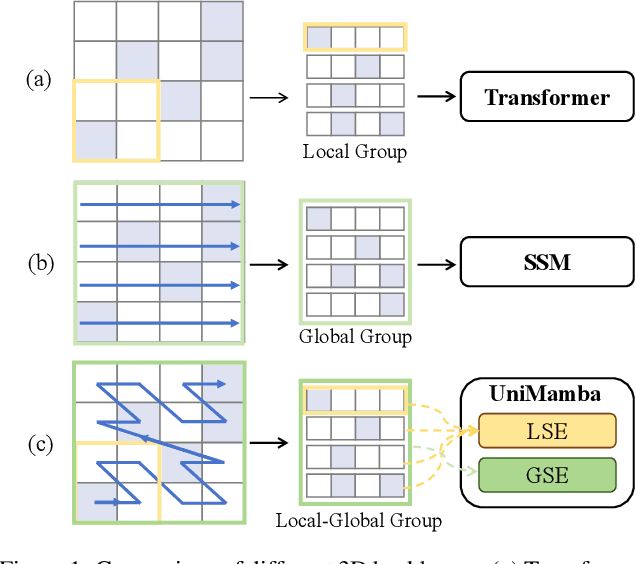
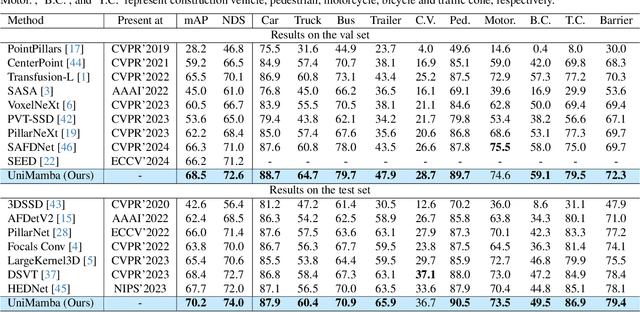
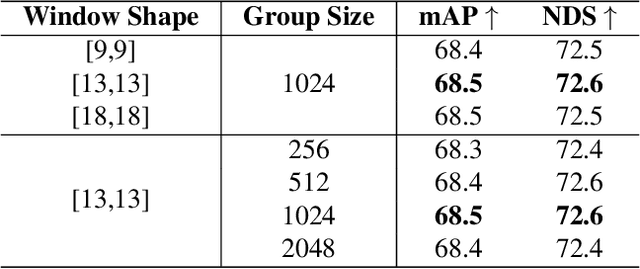
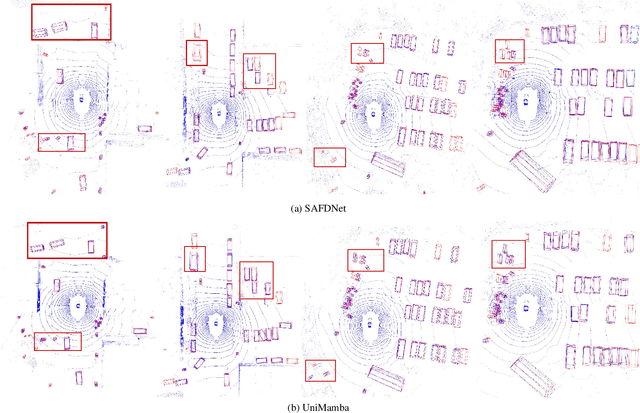
Recent advances in LiDAR 3D detection have demonstrated the effectiveness of Transformer-based frameworks in capturing the global dependencies from point cloud spaces, which serialize the 3D voxels into the flattened 1D sequence for iterative self-attention. However, the spatial structure of 3D voxels will be inevitably destroyed during the serialization process. Besides, due to the considerable number of 3D voxels and quadratic complexity of Transformers, multiple sequences are grouped before feeding to Transformers, leading to a limited receptive field. Inspired by the impressive performance of State Space Models (SSM) achieved in the field of 2D vision tasks, in this paper, we propose a novel Unified Mamba (UniMamba), which seamlessly integrates the merits of 3D convolution and SSM in a concise multi-head manner, aiming to perform "local and global" spatial context aggregation efficiently and simultaneously. Specifically, a UniMamba block is designed which mainly consists of spatial locality modeling, complementary Z-order serialization and local-global sequential aggregator. The spatial locality modeling module integrates 3D submanifold convolution to capture the dynamic spatial position embedding before serialization. Then the efficient Z-order curve is adopted for serialization both horizontally and vertically. Furthermore, the local-global sequential aggregator adopts the channel grouping strategy to efficiently encode both "local and global" spatial inter-dependencies using multi-head SSM. Additionally, an encoder-decoder architecture with stacked UniMamba blocks is formed to facilitate multi-scale spatial learning hierarchically. Extensive experiments are conducted on three popular datasets: nuScenes, Waymo and Argoverse 2. Particularly, our UniMamba achieves 70.2 mAP on the nuScenes dataset.
DiFSD: Ego-Centric Fully Sparse Paradigm with Uncertainty Denoising and Iterative Refinement for Efficient End-to-End Autonomous Driving
Sep 15, 2024Current end-to-end autonomous driving methods resort to unifying modular designs for various tasks (e.g. perception, prediction and planning). Although optimized in a planning-oriented spirit with a fully differentiable framework, existing end-to-end driving systems without ego-centric designs still suffer from unsatisfactory performance and inferior efficiency, owing to the rasterized scene representation learning and redundant information transmission. In this paper, we revisit the human driving behavior and propose an ego-centric fully sparse paradigm, named DiFSD, for end-to-end self-driving. Specifically, DiFSD mainly consists of sparse perception, hierarchical interaction and iterative motion planner. The sparse perception module performs detection, tracking and online mapping based on sparse representation of the driving scene. The hierarchical interaction module aims to select the Closest In-Path Vehicle / Stationary (CIPV / CIPS) from coarse to fine, benefiting from an additional geometric prior. As for the iterative motion planner, both selected interactive agents and ego-vehicle are considered for joint motion prediction, where the output multi-modal ego-trajectories are optimized in an iterative fashion. Besides, both position-level motion diffusion and trajectory-level planning denoising are introduced for uncertainty modeling, thus facilitating the training stability and convergence of the whole framework. Extensive experiments conducted on nuScenes dataset demonstrate the superior planning performance and great efficiency of DiFSD, which significantly reduces the average L2 error by \textbf{66\%} and collision rate by \textbf{77\%} than UniAD while achieves \textbf{8.2$\times$} faster running efficiency.
RoboSense: Large-scale Dataset and Benchmark for Multi-sensor Low-speed Autonomous Driving
Aug 28, 2024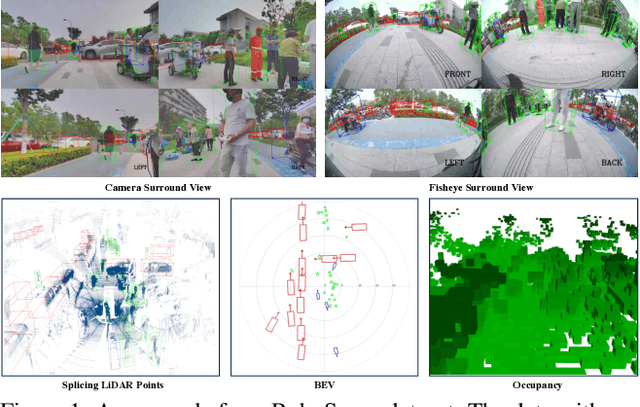
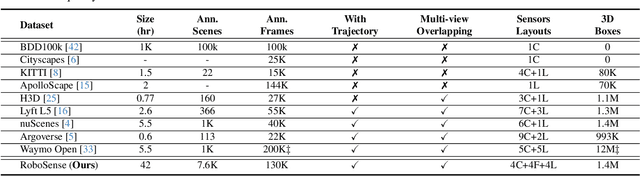
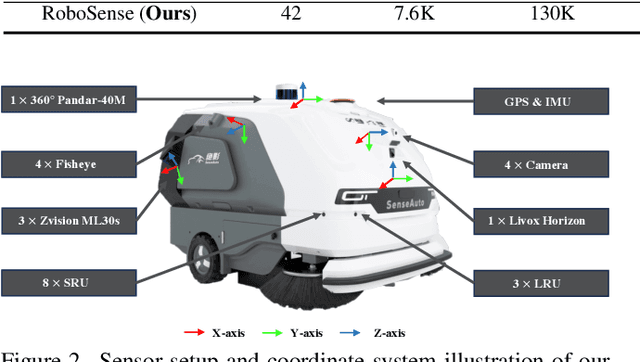
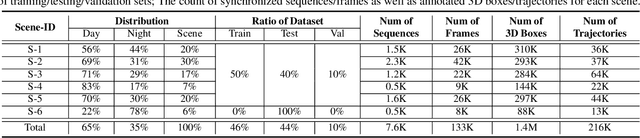
Robust object detection and tracking under arbitrary sight of view is challenging yet essential for the development of Autonomous Vehicle technology. With the growing demand of unmanned function vehicles, near-field scene understanding becomes an important research topic in the areas of low-speed autonomous driving. Due to the complexity of driving conditions and diversity of near obstacles such as blind spots and high occlusion, the perception capability of near-field environment is still inferior than its farther counterpart. To further enhance the intelligent ability of unmanned vehicles, in this paper, we construct a multimodal data collection platform based on 3 main types of sensors (Camera, LiDAR and Fisheye), which supports flexible sensor configurations to enable dynamic sight of view for ego vehicle, either global view or local view. Meanwhile, a large-scale multi-sensor dataset is built, named RoboSense, to facilitate near-field scene understanding. RoboSense contains more than 133K synchronized data with 1.4M 3D bounding box and IDs annotated in the full $360^{\circ}$ view, forming 216K trajectories across 7.6K temporal sequences. It has $270\times$ and $18\times$ as many annotations of near-field obstacles within 5$m$ as the previous single-vehicle datasets such as KITTI and nuScenes. Moreover, we define a novel matching criterion for near-field 3D perception and prediction metrics. Based on RoboSense, we formulate 6 popular tasks to facilitate the future development of related research, where the detailed data analysis as well as benchmarks are also provided accordingly.
Discovering A Variety of Objects in Spatio-Temporal Human-Object Interactions
Nov 18, 2022


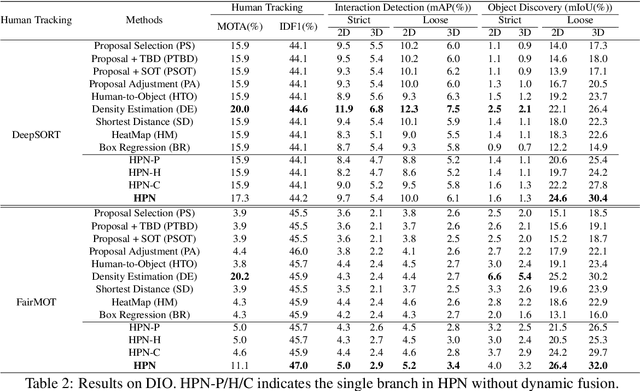
Spatio-temporal Human-Object Interaction (ST-HOI) detection aims at detecting HOIs from videos, which is crucial for activity understanding. In daily HOIs, humans often interact with a variety of objects, e.g., holding and touching dozens of household items in cleaning. However, existing whole body-object interaction video benchmarks usually provide limited object classes. Here, we introduce a new benchmark based on AVA: Discovering Interacted Objects (DIO) including 51 interactions and 1,000+ objects. Accordingly, an ST-HOI learning task is proposed expecting vision systems to track human actors, detect interactions and simultaneously discover interacted objects. Even though today's detectors/trackers excel in object detection/tracking tasks, they perform unsatisfied to localize diverse/unseen objects in DIO. This profoundly reveals the limitation of current vision systems and poses a great challenge. Thus, how to leverage spatio-temporal cues to address object discovery is explored, and a Hierarchical Probe Network (HPN) is devised to discover interacted objects utilizing hierarchical spatio-temporal human/context cues. In extensive experiments, HPN demonstrates impressive performance. Data and code are available at https://github.com/DirtyHarryLYL/HAKE-AVA.
MVP: Robust Multi-View Practice for Driving Action Localization
Jul 05, 2022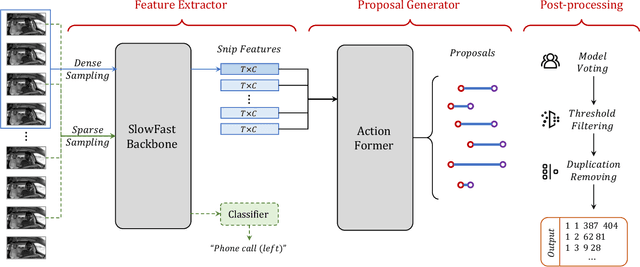

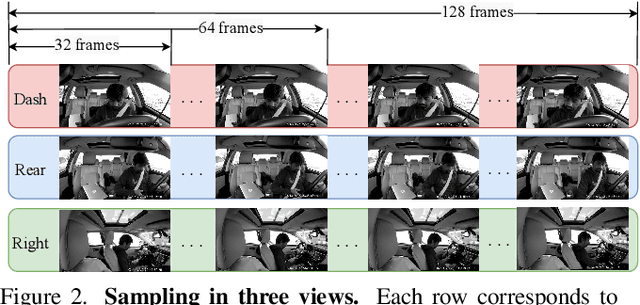

Distracted driving causes thousands of deaths per year, and how to apply deep-learning methods to prevent these tragedies has become a crucial problem. In Track3 of the 6th AI City Challenge, researchers provide a high-quality video dataset with densely action annotations. Due to the small data scale and unclear action boundary, the dataset presents a unique challenge to precisely localize all the different actions and classify their categories. In this paper, we make good use of the multi-view synchronization among videos, and conduct robust Multi-View Practice (MVP) for driving action localization. To avoid overfitting, we fine-tune SlowFast with Kinetics-700 pre-training as the feature extractor. Then the features of different views are passed to ActionFormer to generate candidate action proposals. For precisely localizing all the actions, we design elaborate post-processing, including model voting, threshold filtering and duplication removal. The results show that our MVP is robust for driving action localization, which achieves 28.49% F1-score in the Track3 test set.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021



Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.
Transferable Knowledge-Based Multi-Granularity Aggregation Network for Temporal Action Localization: Submission to ActivityNet Challenge 2021
Jul 27, 2021



This technical report presents an overview of our solution used in the submission to 2021 HACS Temporal Action Localization Challenge on both Supervised Learning Track and Weakly-Supervised Learning Track. Temporal Action Localization (TAL) requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. However, Weakly-Supervised TAL indicates locating the action instances using only video-level class labels. In this paper, to train a supervised temporal action localizer, we adopt Temporal Context Aggregation Network (TCANet) to generate high-quality action proposals through ``local and global" temporal context aggregation and complementary as well as progressive boundary refinement. As for the WSTAL, a novel framework is proposed to handle the poor quality of CAS generated by simple classification network, which can only focus on local discriminative parts, rather than locate the entire interval of target actions. Further inspired by the transfer learning method, we also adopt an additional module to transfer the knowledge from trimmed videos (HACS Clips dataset) to untrimmed videos (HACS Segments dataset), aiming at promoting the classification performance on untrimmed videos. Finally, we employ a boundary regression module embedded with Outer-Inner-Contrastive (OIC) loss to automatically predict the boundaries based on the enhanced CAS. Our proposed scheme achieves 39.91 and 29.78 average mAP on the challenge testing set of supervised and weakly-supervised temporal action localization track respectively.
TSI: Temporal Saliency Integration for Video Action Recognition
Jun 02, 2021



Efficient spatiotemporal modeling is an important yet challenging problem for video action recognition. Existing state-of-the-art methods exploit motion clues to assist in short-term temporal modeling through temporal difference over consecutive frames. However, background noises will be inevitably introduced due to the camera movement. Besides, movements of different actions can vary greatly. In this paper, we propose a Temporal Saliency Integration (TSI) block, which mainly contains a Salient Motion Excitation (SME) module and a Cross-scale Temporal Integration (CTI) module. Specifically, SME aims to highlight the motion-sensitive area through local-global motion modeling, where the background suppression and pyramidal feature difference are conducted successively between neighboring frames to capture motion dynamics with less background noises. CTI is designed to perform multi-scale temporal modeling through a group of separate 1D convolutions respectively. Meanwhile, temporal interactions across different scales are integrated with attention mechanism. Through these two modules, long short-term temporal relationships can be encoded efficiently by introducing limited additional parameters. Extensive experiments are conducted on several popular benchmarks (i.e., Something-Something v1 & v2, Kinetics-400, UCF-101, and HMDB-51), which demonstrate the effectiveness and superiority of our proposed method.
Temporal Context Aggregation Network for Temporal Action Proposal Refinement
Mar 24, 2021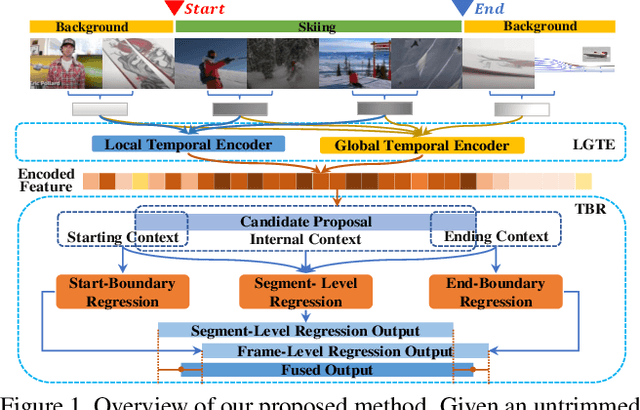



Temporal action proposal generation aims to estimate temporal intervals of actions in untrimmed videos, which is a challenging yet important task in the video understanding field. The proposals generated by current methods still suffer from inaccurate temporal boundaries and inferior confidence used for retrieval owing to the lack of efficient temporal modeling and effective boundary context utilization. In this paper, we propose Temporal Context Aggregation Network (TCANet) to generate high-quality action proposals through "local and global" temporal context aggregation and complementary as well as progressive boundary refinement. Specifically, we first design a Local-Global Temporal Encoder (LGTE), which adopts the channel grouping strategy to efficiently encode both "local and global" temporal inter-dependencies. Furthermore, both the boundary and internal context of proposals are adopted for frame-level and segment-level boundary regressions, respectively. Temporal Boundary Regressor (TBR) is designed to combine these two regression granularities in an end-to-end fashion, which achieves the precise boundaries and reliable confidence of proposals through progressive refinement. Extensive experiments are conducted on three challenging datasets: HACS, ActivityNet-v1.3, and THUMOS-14, where TCANet can generate proposals with high precision and recall. By combining with the existing action classifier, TCANet can obtain remarkable temporal action detection performance compared with other methods. Not surprisingly, the proposed TCANet won the 1$^{st}$ place in the CVPR 2020 - HACS challenge leaderboard on temporal action localization task.