 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP: Robust Multi-View Practice for Driving Action Localization
Jul 05, 2022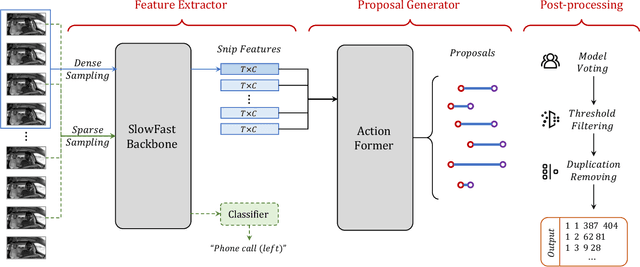

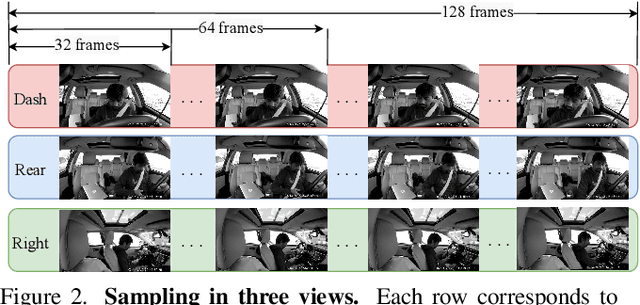

Distracted driving causes thousands of deaths per year, and how to apply deep-learning methods to prevent these tragedies has become a crucial problem. In Track3 of the 6th AI City Challenge, researchers provide a high-quality video dataset with densely action annotations. Due to the small data scale and unclear action boundary, the dataset presents a unique challenge to precisely localize all the different actions and classify their categories. In this paper, we make good use of the multi-view synchronization among videos, and conduct robust Multi-View Practice (MVP) for driving action localization. To avoid overfitting, we fine-tune SlowFast with Kinetics-700 pre-training as the feature extractor. Then the features of different views are passed to ActionFormer to generate candidate action proposals. For precisely localizing all the actions, we design elaborate post-processing, including model voting, threshold filtering and duplication removal. The results show that our MVP is robust for driving action localization, which achieves 28.49% F1-score in the Track3 test set.