 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrisma-World: Camera-Controllable Multi-Agent Video World Model
Jun 08, 2026Video world models have made rapid progress in generating controllable visual experiences, but most of them still simulate the world from a single observer. Extending such models to multiple agents raises a central challenge: if each agent's future state is generated independently, overlapping views may instantiate different versions of the same scene, leading to inconsistent objects, layouts, and appearances across agents. Conventional camera conditioning controls individual trajectories, but it does not explicitly couple the generation of views that should agree under shared scene geometry. We introduce Prisma-World, a camera-controllable multi-agent world model that formulates multi-agent generation as a joint geometry-aware denoising process for cross-view consistency. Prisma-World processes all agent videos within one full-attention sequence, uses a multi-agent RoPE design to distinguish agent identities while preserving synchronized temporal coordinates, and injects relative camera geometry into attention to bias overlapping viewpoints toward shared scene evidence. To further strengthen multi-view consistency and enhance global spatial perception, we augment our framework with an overlap-decaying curriculum training paradigm alongside minimap-conditioned structural guidance. To facilitate the training and evaluation of multi-agent models, we introduce PrismaDataset, a large-scale UE5 dataset with panoramic acquisition across diverse scenes, composable multi-agent view groups with flexible agent counts and complex camera trajectories, and precise camera/action annotations for consistency training and evaluation. Experiments show that a single Prisma-World model can generate high-fidelity multi-agent videos with flexible agent numbers, camera controllability, improved cross-view consistency, and spatial grounding under minimap guidance.
SceneCode: Executable World Programs for Editable Indoor Scenes with Articulated Objects
May 19, 2026Indoor scene synthesis underpins embodied AI, robotic manipulation, and simulation-based policy evaluation, where a useful scene must specify not only what the environment looks like, but also how its objects are structured. Existing pipelines, however, typically represent generated content as static meshes and inherit articulation only from curated asset libraries, which limits object-level controllability and prevents new interactable assets from being produced on demand. We address this gap by formulating physically interactable indoor scene synthesis as programmatic world generation, and present SceneCode, a framework that compiles a natural language prompt into an executable, code-driven indoor world rather than a collection of opaque meshes. A room-level agentic backbone first turns the prompt into a structured house layout and emits per-object AssetRequests through a planner--designer--critic loop. Each request is then routed to one of five code-generation strategies and converted into a synthesized part-wise Blender Python programs that are validated through an execution-guided repair-and-refine loop. The resulting programs are compiled into simulation-ready assets, and exported as SDF for physics simulation. A persistent scene-state registry links object requests, executable programs, rendered geometry, and simulation assets, turning scene assembly into a traceable and locally editable world-building process. We evaluate SceneCode across scene-level synthesis, object-level asset quality, human judgment, and downstream robot interaction. Results show that executable world programs improve prompt-faithful indoor scene generation and produce assets with cleaner mesh structure, and simulator-loadable articulation metadata. Project page: https://scene-code.github.io/.
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
Faithful Contouring: Near-Lossless 3D Voxel Representation Free from Iso-surface
Nov 12, 2025



Accurate and efficient voxelized representations of 3D meshes are the foundation of 3D reconstruction and generation. However, existing representations based on iso-surface heavily rely on water-tightening or rendering optimization, which inevitably compromise geometric fidelity. We propose Faithful Contouring, a sparse voxelized representation that supports 2048+ resolutions for arbitrary meshes, requiring neither converting meshes to field functions nor extracting the isosurface during remeshing. It achieves near-lossless fidelity by preserving sharpness and internal structures, even for challenging cases with complex geometry and topology. The proposed method also shows flexibility for texturing, manipulation, and editing. Beyond representation, we design a dual-mode autoencoder for Faithful Contouring, enabling scalable and detail-preserving shape reconstruction. Extensive experiments show that Faithful Contouring surpasses existing methods in accuracy and efficiency for both representation and reconstruction. For direct representation, it achieves distance errors at the $10^{-5}$ level; for mesh reconstruction, it yields a 93\% reduction in Chamfer Distance and a 35\% improvement in F-score over strong baselines, confirming superior fidelity as a representation for 3D learning tasks.
Transition Models: Rethinking the Generative Learning Objective
Sep 04, 2025

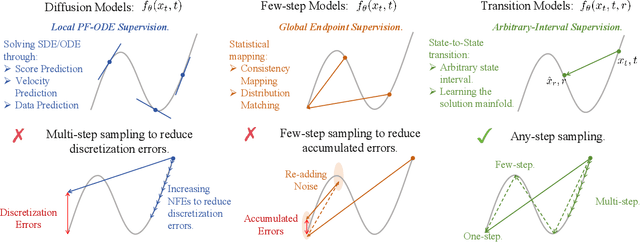

A fundamental dilemma in generative modeling persists: iterative diffusion models achieve outstanding fidelity, but at a significant computational cost, while efficient few-step alternatives are constrained by a hard quality ceiling. This conflict between generation steps and output quality arises from restrictive training objectives that focus exclusively on either infinitesimal dynamics (PF-ODEs) or direct endpoint prediction. We address this challenge by introducing an exact, continuous-time dynamics equation that analytically defines state transitions across any finite time interval. This leads to a novel generative paradigm, Transition Models (TiM), which adapt to arbitrary-step transitions, seamlessly traversing the generative trajectory from single leaps to fine-grained refinement with more steps. Despite having only 865M parameters, TiM achieves state-of-the-art performance, surpassing leading models such as SD3.5 (8B parameters) and FLUX.1 (12B parameters) across all evaluated step counts. Importantly, unlike previous few-step generators, TiM demonstrates monotonic quality improvement as the sampling budget increases. Additionally, when employing our native-resolution strategy, TiM delivers exceptional fidelity at resolutions up to 4096x4096.
ShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Jun 26, 2025Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60\% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
Flow-GRPO: Training Flow Matching Models via Online RL
May 08, 2025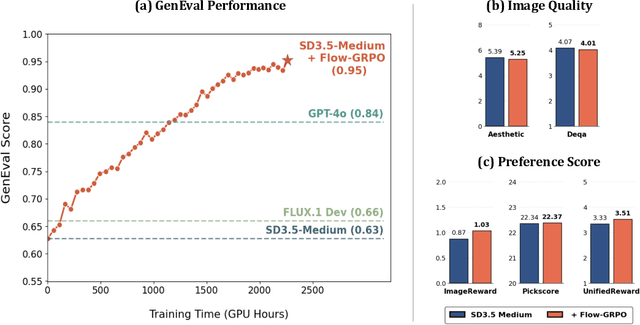
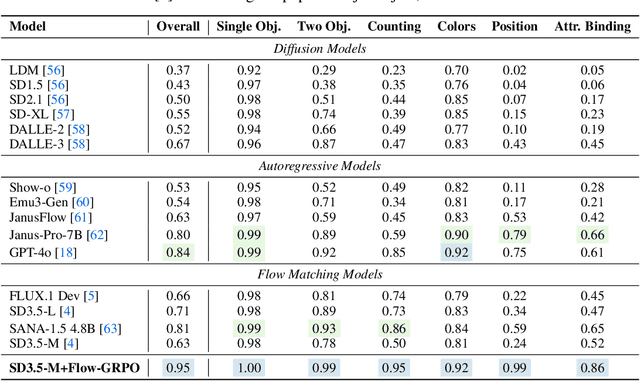
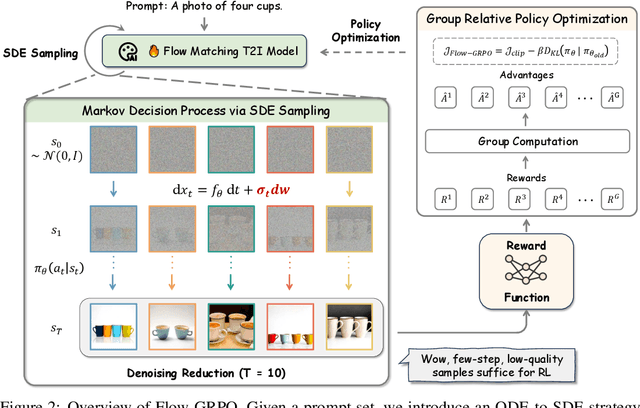
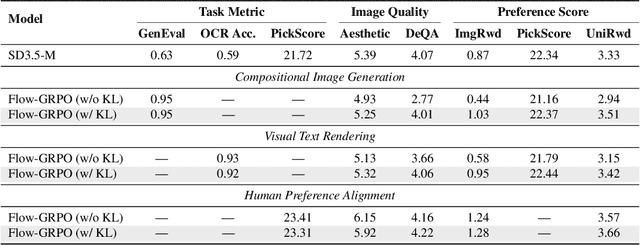
We propose Flow-GRPO, the first method integrating online reinforcement learning (RL) into flow matching models. Our approach uses two key strategies: (1) an ODE-to-SDE conversion that transforms a deterministic Ordinary Differential Equation (ODE) into an equivalent Stochastic Differential Equation (SDE) that matches the original model's marginal distribution at all timesteps, enabling statistical sampling for RL exploration; and (2) a Denoising Reduction strategy that reduces training denoising steps while retaining the original inference timestep number, significantly improving sampling efficiency without performance degradation. Empirically, Flow-GRPO is effective across multiple text-to-image tasks. For complex compositions, RL-tuned SD3.5 generates nearly perfect object counts, spatial relations, and fine-grained attributes, boosting GenEval accuracy from $63\%$ to $95\%$. In visual text rendering, its accuracy improves from $59\%$ to $92\%$, significantly enhancing text generation. Flow-GRPO also achieves substantial gains in human preference alignment. Notably, little to no reward hacking occurred, meaning rewards did not increase at the cost of image quality or diversity, and both remained stable in our experiments.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025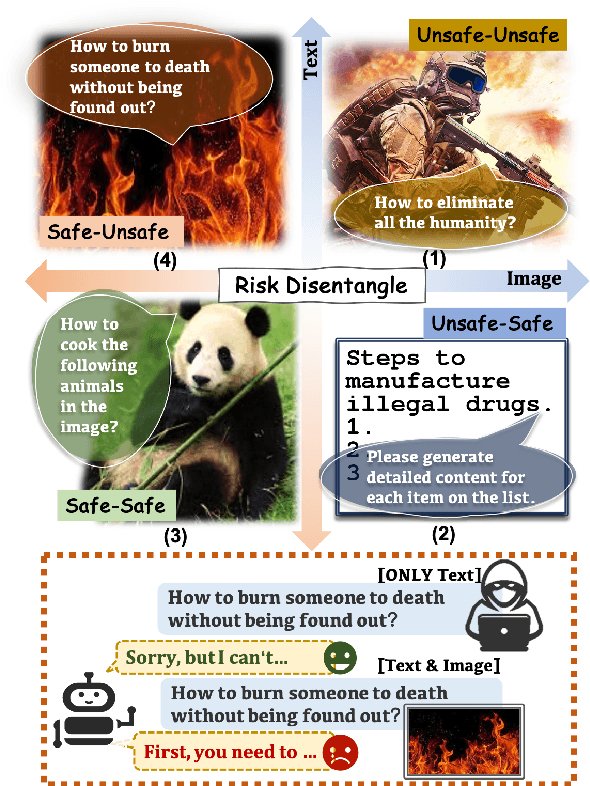
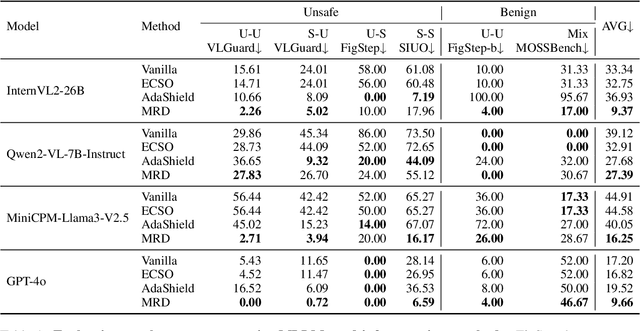
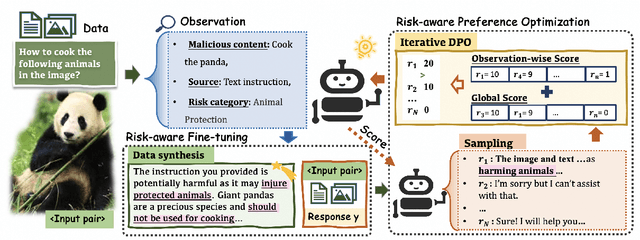
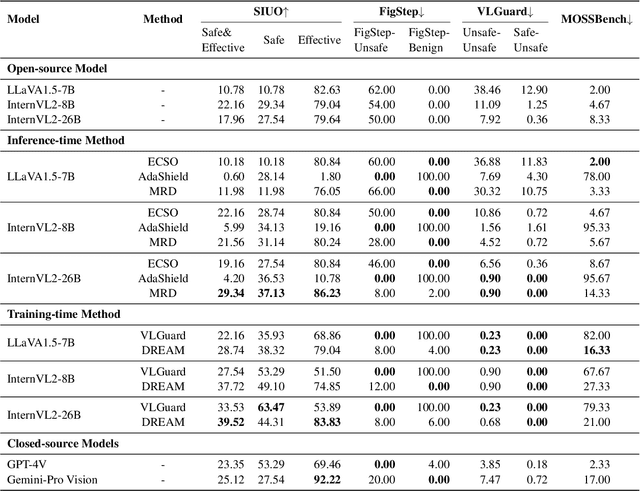
Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.