 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProEdit: Inversion-based Editing From Prompts Done Right
Dec 26, 2025


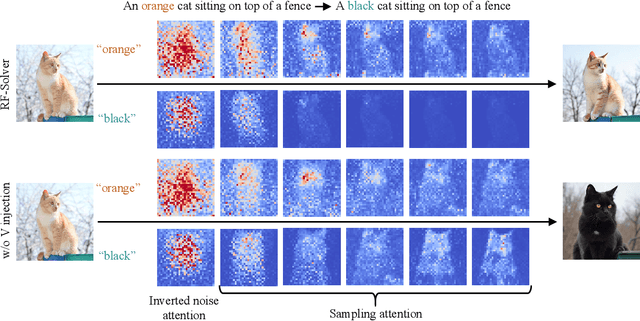
Inversion-based visual editing provides an effective and training-free way to edit an image or a video based on user instructions. Existing methods typically inject source image information during the sampling process to maintain editing consistency. However, this sampling strategy overly relies on source information, which negatively affects the edits in the target image (e.g., failing to change the subject's atributes like pose, number, or color as instructed). In this work, we propose ProEdit to address this issue both in the attention and the latent aspects. In the attention aspect, we introduce KV-mix, which mixes KV features of the source and the target in the edited region, mitigating the influence of the source image on the editing region while maintaining background consistency. In the latent aspect, we propose Latents-Shift, which perturbs the edited region of the source latent, eliminating the influence of the inverted latent on the sampling. Extensive experiments on several image and video editing benchmarks demonstrate that our method achieves SOTA performance. In addition, our design is plug-and-play, which can be seamlessly integrated into existing inversion and editing methods, such as RF-Solver, FireFlow and UniEdit.
OpenSubject: Leveraging Video-Derived Identity and Diversity Priors for Subject-driven Image Generation and Manipulation
Dec 10, 2025Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.
ShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Jun 26, 2025Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60\% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
Decoupled Distillation to Erase: A General Unlearning Method for Any Class-centric Tasks
Mar 31, 2025In this work, we present DEcoupLEd Distillation To Erase (DELETE), a general and strong unlearning method for any class-centric tasks. To derive this, we first propose a theoretical framework to analyze the general form of unlearning loss and decompose it into forgetting and retention terms. Through the theoretical framework, we point out that a class of previous methods could be mainly formulated as a loss that implicitly optimizes the forgetting term while lacking supervision for the retention term, disturbing the distribution of pre-trained model and struggling to adequately preserve knowledge of the remaining classes. To address it, we refine the retention term using "dark knowledge" and propose a mask distillation unlearning method. By applying a mask to separate forgetting logits from retention logits, our approach optimizes both the forgetting and refined retention components simultaneously, retaining knowledge of the remaining classes while ensuring thorough forgetting of the target class. Without access to the remaining data or intervention (i.e., used in some works), we achieve state-of-the-art performance across various benchmarks. What's more, DELETE is a general solution that can be applied to various downstream tasks, including face recognition, backdoor defense, and semantic segmentation with great performance.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.
SpatialDreamer: Self-supervised Stereo Video Synthesis from Monocular Input
Nov 18, 2024Stereo video synthesis from a monocular input is a demanding task in the fields of spatial computing and virtual reality. The main challenges of this task lie on the insufficiency of high-quality paired stereo videos for training and the difficulty of maintaining the spatio-temporal consistency between frames. Existing methods primarily address these issues by directly applying novel view synthesis (NVS) techniques to video, while facing limitations such as the inability to effectively represent dynamic scenes and the requirement for large amounts of training data. In this paper, we introduce a novel self-supervised stereo video synthesis paradigm via a video diffusion model, termed SpatialDreamer, which meets the challenges head-on. Firstly, to address the stereo video data insufficiency, we propose a Depth based Video Generation module DVG, which employs a forward-backward rendering mechanism to generate paired videos with geometric and temporal priors. Leveraging data generated by DVG, we propose RefinerNet along with a self-supervised synthetic framework designed to facilitate efficient and dedicated training. More importantly, we devise a consistency control module, which consists of a metric of stereo deviation strength and a Temporal Interaction Learning module TIL for geometric and temporal consistency ensurance respectively. We evaluated the proposed method against various benchmark methods, with the results showcasing its superior performance.
An Economic Framework for 6-DoF Grasp Detection
Jul 11, 2024



Robotic grasping in clutters is a fundamental task in robotic manipulation. In this work, we propose an economic framework for 6-DoF grasp detection, aiming to economize the resource cost in training and meanwhile maintain effective grasp performance. To begin with, we discover that the dense supervision is the bottleneck of current SOTA methods that severely encumbers the entire training overload, meanwhile making the training difficult to converge. To solve the above problem, we first propose an economic supervision paradigm for efficient and effective grasping. This paradigm includes a well-designed supervision selection strategy, selecting key labels basically without ambiguity, and an economic pipeline to enable the training after selection. Furthermore, benefit from the economic supervision, we can focus on a specific grasp, and thus we devise a focal representation module, which comprises an interactive grasp head and a composite score estimation to generate the specific grasp more accurately. Combining all together, the EconomicGrasp framework is proposed. Our extensive experiments show that EconomicGrasp surpasses the SOTA grasp method by about 3AP on average, and with extremely low resource cost, for about 1/4 training time cost, 1/8 memory cost and 1/30 storage cost. Our code is available at https://github.com/iSEE-Laboratory/EconomicGrasp.
Dexterous Grasp Transformer
Apr 28, 2024In this work, we propose a novel discriminative framework for dexterous grasp generation, named Dexterous Grasp TRansformer (DGTR), capable of predicting a diverse set of feasible grasp poses by processing the object point cloud with only one forward pass. We formulate dexterous grasp generation as a set prediction task and design a transformer-based grasping model for it. However, we identify that this set prediction paradigm encounters several optimization challenges in the field of dexterous grasping and results in restricted performance. To address these issues, we propose progressive strategies for both the training and testing phases. First, the dynamic-static matching training (DSMT) strategy is presented to enhance the optimization stability during the training phase. Second, we introduce the adversarial-balanced test-time adaptation (AB-TTA) with a pair of adversarial losses to improve grasping quality during the testing phase. Experimental results on the DexGraspNet dataset demonstrate the capability of DGTR to predict dexterous grasp poses with both high quality and diversity. Notably, while keeping high quality, the diversity of grasp poses predicted by DGTR significantly outperforms previous works in multiple metrics without any data pre-processing. Codes are available at https://github.com/iSEE-Laboratory/DGTR .
Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
Mar 17, 2024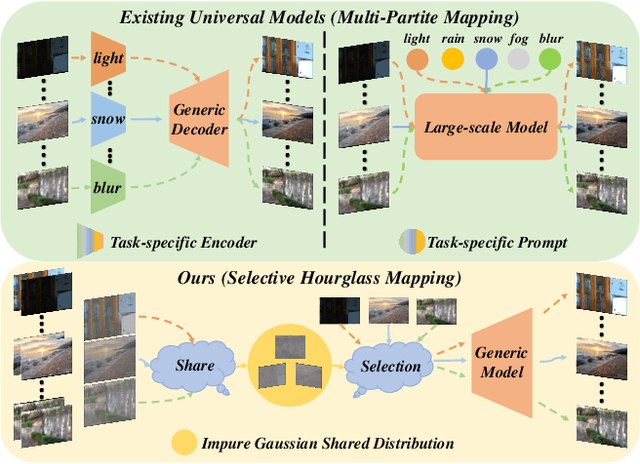



Universal image restoration is a practical and potential computer vision task for real-world applications. The main challenge of this task is handling the different degradation distributions at once. Existing methods mainly utilize task-specific conditions (e.g., prompt) to guide the model to learn different distributions separately, named multi-partite mapping. However, it is not suitable for universal model learning as it ignores the shared information between different tasks. In this work, we propose an advanced selective hourglass mapping strategy based on diffusion model, termed DiffUIR. Two novel considerations make our DiffUIR non-trivial. Firstly, we equip the model with strong condition guidance to obtain accurate generation direction of diffusion model (selective). More importantly, DiffUIR integrates a flexible shared distribution term (SDT) into the diffusion algorithm elegantly and naturally, which gradually maps different distributions into a shared one. In the reverse process, combined with SDT and strong condition guidance, DiffUIR iteratively guides the shared distribution to the task-specific distribution with high image quality (hourglass). Without bells and whistles, by only modifying the mapping strategy, we achieve state-of-the-art performance on five image restoration tasks, 22 benchmarks in the universal setting and zero-shot generalization setting. Surprisingly, by only using a lightweight model (only 0.89M), we could achieve outstanding performance. The source code and pre-trained models are available at https://github.com/iSEE-Laboratory/DiffUIR
DiffuVolume: Diffusion Model for Volume based Stereo Matching
Aug 30, 2023



Stereo matching is a significant part in many computer vision tasks and driving-based applications. Recently cost volume-based methods have achieved great success benefiting from the rich geometry information in paired images. However, the redundancy of cost volume also interferes with the model training and limits the performance. To construct a more precise cost volume, we pioneeringly apply the diffusion model to stereo matching. Our method, termed DiffuVolume, considers the diffusion model as a cost volume filter, which will recurrently remove the redundant information from the cost volume. Two main designs make our method not trivial. Firstly, to make the diffusion model more adaptive to stereo matching, we eschew the traditional manner of directly adding noise into the image but embed the diffusion model into a task-specific module. In this way, we outperform the traditional diffusion stereo matching method by 22% EPE improvement and 240 times inference acceleration. Secondly, DiffuVolume can be easily embedded into any volume-based stereo matching network with boost performance but slight parameters rise (only 2%). By adding the DiffuVolume into well-performed methods, we outperform all the published methods on Scene Flow, KITTI2012, KITTI2015 benchmarks and zero-shot generalization setting. It is worth mentioning that the proposed model ranks 1st on KITTI 2012 leader board, 2nd on KITTI 2015 leader board since 15, July 2023.