 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Explicit Continuous Motion Representation for Dynamic Gaussian Splatting from Monocular Videos
Mar 26, 2026We present an approach for high-quality dynamic Gaussian Splatting from monocular videos. To this end, we in this work go one step further beyond previous methods to explicitly model continuous position and orientation deformation of dynamic Gaussians, using an SE(3) B-spline motion bases with a compact set of control points. To improve computational efficiency while enhancing the ability to model complex motions, an adaptive control mechanism is devised to dynamically adjust the number of motion bases and control points. Besides, we develop a soft segment reconstruction strategy to mitigate long-interval motion interference, and employ a multi-view diffusion model to provide multi-view cues for avoiding overfitting to training views. Extensive experiments demonstrate that our method outperforms state-of-the-art methods in novel view synthesis. Our code is available at https://github.com/hhhddddddd/se3bsplinegs.
DiffuVolume: Diffusion Model for Volume based Stereo Matching
Aug 30, 2023



Stereo matching is a significant part in many computer vision tasks and driving-based applications. Recently cost volume-based methods have achieved great success benefiting from the rich geometry information in paired images. However, the redundancy of cost volume also interferes with the model training and limits the performance. To construct a more precise cost volume, we pioneeringly apply the diffusion model to stereo matching. Our method, termed DiffuVolume, considers the diffusion model as a cost volume filter, which will recurrently remove the redundant information from the cost volume. Two main designs make our method not trivial. Firstly, to make the diffusion model more adaptive to stereo matching, we eschew the traditional manner of directly adding noise into the image but embed the diffusion model into a task-specific module. In this way, we outperform the traditional diffusion stereo matching method by 22% EPE improvement and 240 times inference acceleration. Secondly, DiffuVolume can be easily embedded into any volume-based stereo matching network with boost performance but slight parameters rise (only 2%). By adding the DiffuVolume into well-performed methods, we outperform all the published methods on Scene Flow, KITTI2012, KITTI2015 benchmarks and zero-shot generalization setting. It is worth mentioning that the proposed model ranks 1st on KITTI 2012 leader board, 2nd on KITTI 2015 leader board since 15, July 2023.
Class Attention to Regions of Lesion for Imbalanced Medical Image Recognition
Jul 20, 2023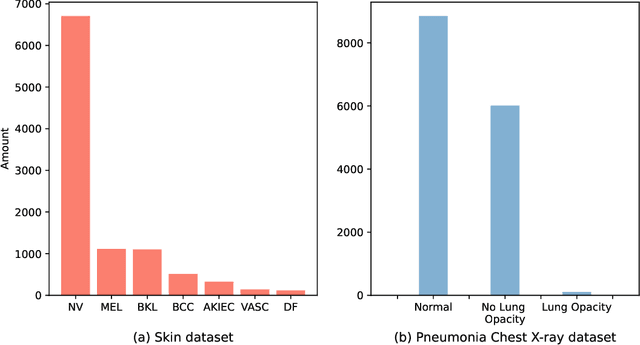

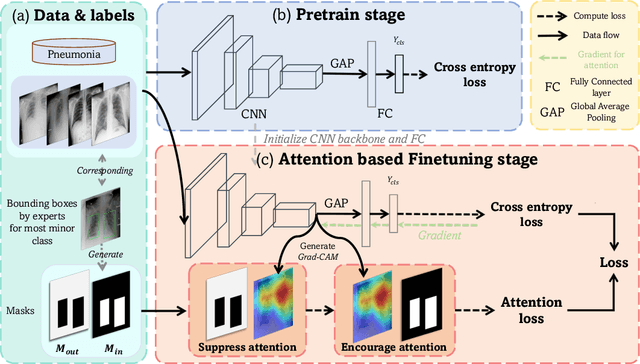
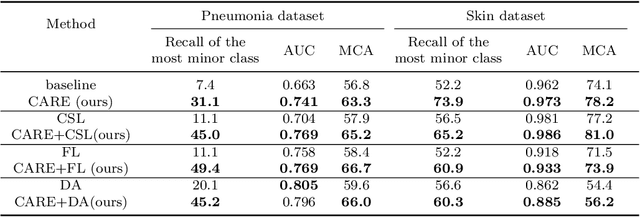
Automated medical image classification is the key component in intelligent diagnosis systems. However, most medical image datasets contain plenty of samples of common diseases and just a handful of rare ones, leading to major class imbalances. Currently, it is an open problem in intelligent diagnosis to effectively learn from imbalanced training data. In this paper, we propose a simple yet effective framework, named \textbf{C}lass \textbf{A}ttention to \textbf{RE}gions of the lesion (CARE), to handle data imbalance issues by embedding attention into the training process of \textbf{C}onvolutional \textbf{N}eural \textbf{N}etworks (CNNs). The proposed attention module helps CNNs attend to lesion regions of rare diseases, therefore helping CNNs to learn their characteristics more effectively. In addition, this attention module works only during the training phase and does not change the architecture of the original network, so it can be directly combined with any existing CNN architecture. The CARE framework needs bounding boxes to represent the lesion regions of rare diseases. To alleviate the need for manual annotation, we further developed variants of CARE by leveraging the traditional saliency methods or a pretrained segmentation model for bounding box generation. Results show that the CARE variants with automated bounding box generation are comparable to the original CARE framework with \textit{manual} bounding box annotations. A series of experiments on an imbalanced skin image dataset and a pneumonia dataset indicates that our method can effectively help the network focus on the lesion regions of rare diseases and remarkably improves the classification performance of rare diseases.
AcroFOD: An Adaptive Method for Cross-domain Few-shot Object Detection
Sep 22, 2022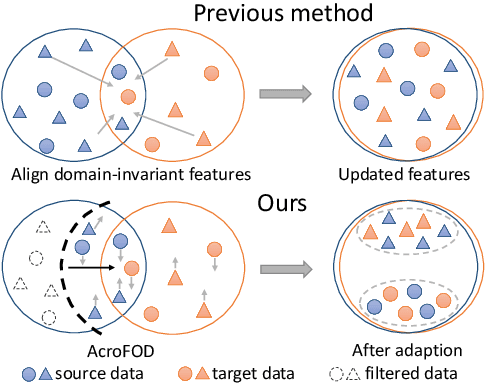
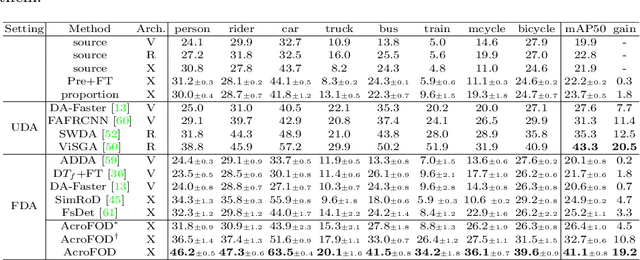
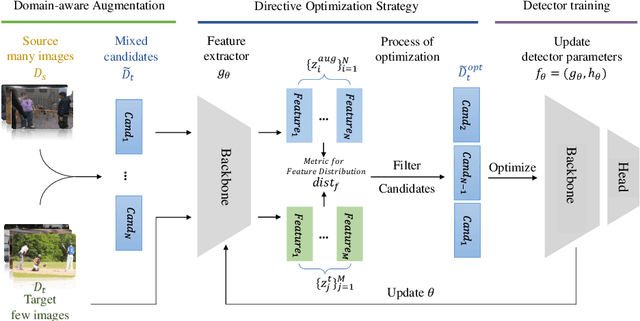
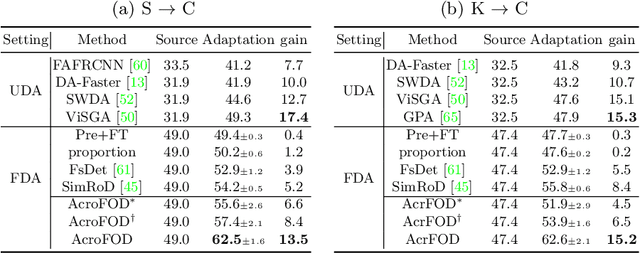
Under the domain shift, cross-domain few-shot object detection aims to adapt object detectors in the target domain with a few annotated target data. There exists two significant challenges: (1) Highly insufficient target domain data; (2) Potential over-adaptation and misleading caused by inappropriately amplified target samples without any restriction. To address these challenges, we propose an adaptive method consisting of two parts. First, we propose an adaptive optimization strategy to select augmented data similar to target samples rather than blindly increasing the amount. Specifically, we filter the augmented candidates which significantly deviate from the target feature distribution in the very beginning. Second, to further relieve the data limitation, we propose the multi-level domain-aware data augmentation to increase the diversity and rationality of augmented data, which exploits the cross-image foreground-background mixture. Experiments show that the proposed method achieves state-of-the-art performance on multiple benchmarks.
PCCT: Progressive Class-Center Triplet Loss for Imbalanced Medical Image Classification
Jul 11, 2022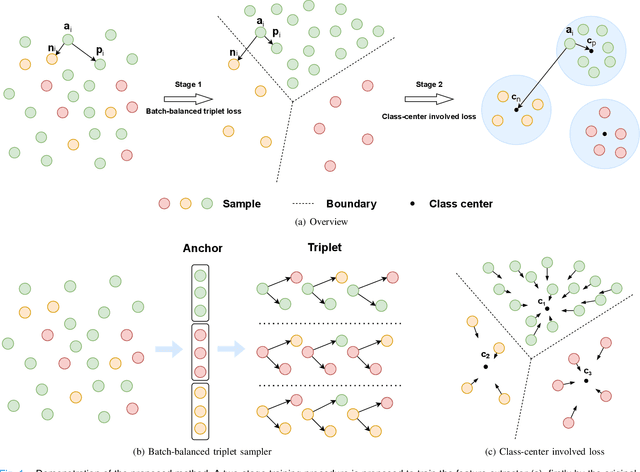
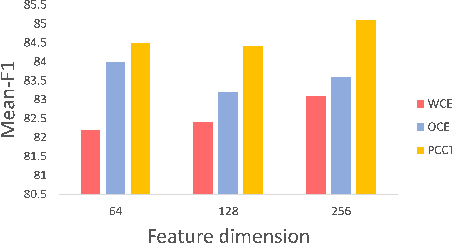

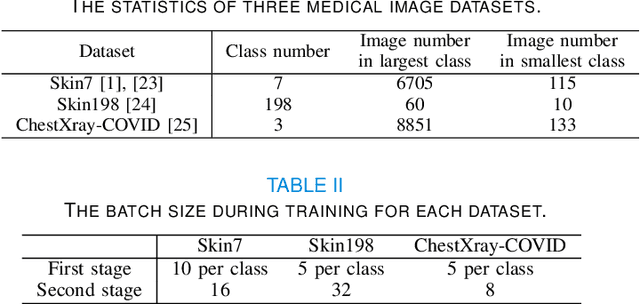
Imbalanced training data is a significant challenge for medical image classification. In this study, we propose a novel Progressive Class-Center Triplet (PCCT) framework to alleviate the class imbalance issue particularly for diagnosis of rare diseases, mainly by carefully designing the triplet sampling strategy and the triplet loss formation. Specifically, the PCCT framework includes two successive stages. In the first stage, PCCT trains the diagnosis system via a class-balanced triplet loss to coarsely separate distributions of different classes. In the second stage, the PCCT framework further improves the diagnosis system via a class-center involved triplet loss to cause a more compact distribution for each class. For the class-balanced triplet loss, triplets are sampled equally for each class at each training iteration, thus alleviating the imbalanced data issue. For the class-center involved triplet loss, the positive and negative samples in each triplet are replaced by their corresponding class centers, which enforces data representations of the same class closer to the class center. Furthermore, the class-center involved triplet loss is extended to the pair-wise ranking loss and the quadruplet loss, which demonstrates the generalization of the proposed framework. Extensive experiments support that the PCCT framework works effectively for medical image classification with imbalanced training images. On two skin image datasets and one chest X-ray dataset, the proposed approach respectively obtains the mean F1 score 86.2, 65.2, and 90.66 over all classes and 81.4, 63.87, and 81.92 for rare classes, achieving state-of-the-art performance and outperforming the widely used methods for the class imbalance issue.
Task-oriented Self-supervised Learning for Anomaly Detection in Electroencephalography
Jul 04, 2022
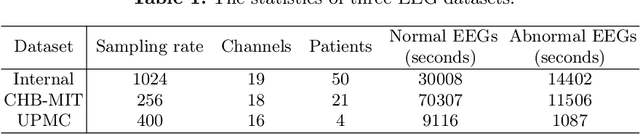

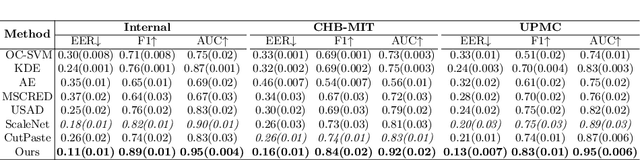
Accurate automated analysis of electroencephalography (EEG) would largely help clinicians effectively monitor and diagnose patients with various brain diseases. Compared to supervised learning with labelled disease EEG data which can train a model to analyze specific diseases but would fail to monitor previously unseen statuses, anomaly detection based on only normal EEGs can detect any potential anomaly in new EEGs. Different from existing anomaly detection strategies which do not consider any property of unavailable abnormal data during model development, a task-oriented self-supervised learning approach is proposed here which makes use of available normal EEGs and expert knowledge about abnormal EEGs to train a more effective feature extractor for the subsequent development of anomaly detector. In addition, a specific two branch convolutional neural network with larger kernels is designed as the feature extractor such that it can more easily extract both larger scale and small-scale features which often appear in unavailable abnormal EEGs. The effectively designed and trained feature extractor has shown to be able to extract better feature representations from EEGs for development of anomaly detector based on normal data and future anomaly detection for new EEGs, as demonstrated on three EEG datasets. The code is available at https://github.com/ironing/EEG-AD.
Understanding of Kernels in CNN Models by Suppressing Irrelevant Visual Features in Images
Aug 25, 2021
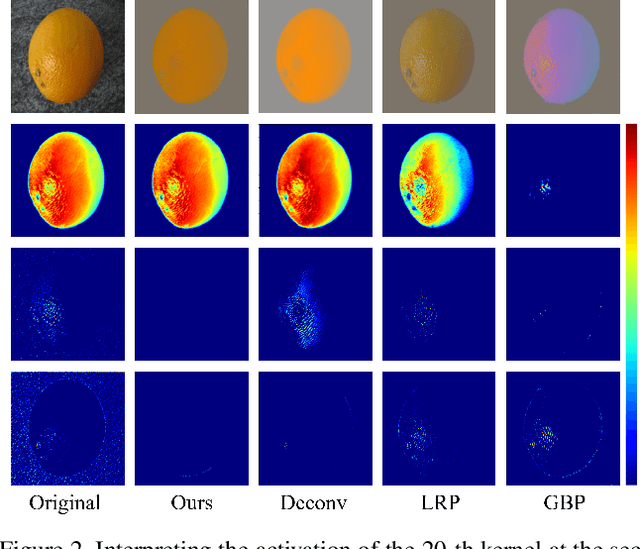

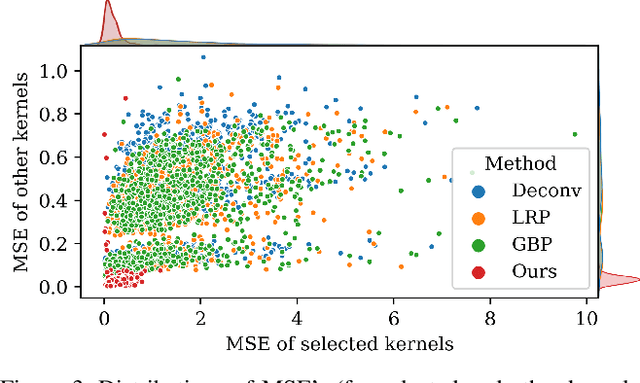
Deep learning models have shown their superior performance in various vision tasks. However, the lack of precisely interpreting kernels in convolutional neural networks (CNNs) is becoming one main obstacle to wide applications of deep learning models in real scenarios. Although existing interpretation methods may find certain visual patterns which are associated with the activation of a specific kernel, those visual patterns may not be specific or comprehensive enough for interpretation of a specific activation of kernel of interest. In this paper, a simple yet effective optimization method is proposed to interpret the activation of any kernel of interest in CNN models. The basic idea is to simultaneously preserve the activation of the specific kernel and suppress the activation of all other kernels at the same layer. In this way, only visual information relevant to the activation of the specific kernel is remained in the input. Consistent visual information from multiple modified inputs would help users understand what kind of features are specifically associated with specific kernel. Comprehensive evaluation shows that the proposed method can help better interpret activation of specific kernels than widely used methods, even when two kernels have very similar activation regions from the same input image.