 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynProto: Dynamic Prototype Evolution for Out-of-Distribution Detection
Apr 26, 2026Recent studies show that using potential out-of-distribution (OOD) labels from large corpora as auxiliary information can improve OOD detection in vision-language models (VLMs). However, these methods often fail when real-world OOD samples fall outside the predefined OOD label set. To address this limitation, we propose DynProto, a novel approach that learns OOD prototypes dynamically during testing using only in-distribution (ID) information. DynProto is inspired by a key observation: OOD samples predicted as the same ID class tend to cluster in the feature space. With this insight, we leverage easy-to-detect OOD samples as ``anchors'' to find their harder-to-detect, similar counterparts. To this end, DynProto introduces two modules: \textbf{Coarse OOD Pattern Capturing Module} caches OOD patterns that are easily confused with each ID class during testing, and \textbf{Fine-grained OOD Pattern Refinement Module} subsequently clusters these patterns within each cache and aggregates them into representative OOD prototypes. By measuring similarity to ID and dynamic OOD prototypes, DynProto enables accurate OOD detection. DynProto significantly outperforms prior methods across multiple benchmarks. On ImageNet OOD benchmark, DynProto reduces FPR95 by 11.60\% and improves AUROC by 4.70\%. Moreover, the framework is architecture-agnostic and can be integrated into various backbones.
DCAC: Dynamic Class-Aware Cache Creates Stronger Out-of-Distribution Detectors
Jan 18, 2026Out-of-distribution (OOD) detection remains a fundamental challenge for deep neural networks, particularly due to overconfident predictions on unseen OOD samples during testing. We reveal a key insight: OOD samples predicted as the same class, or given high probabilities for it, are visually more similar to each other than to the true in-distribution (ID) samples. Motivated by this class-specific observation, we propose DCAC (Dynamic Class-Aware Cache), a training-free, test-time calibration module that maintains separate caches for each ID class to collect high-entropy samples and calibrate the raw predictions of input samples. DCAC leverages cached visual features and predicted probabilities through a lightweight two-layer module to mitigate overconfident predictions on OOD samples. This module can be seamlessly integrated with various existing OOD detection methods across both unimodal and vision-language models while introducing minimal computational overhead. Extensive experiments on multiple OOD benchmarks demonstrate that DCAC significantly enhances existing methods, achieving substantial improvements, i.e., reducing FPR95 by 6.55% when integrated with ASH-S on ImageNet OOD benchmark.
Class Attention to Regions of Lesion for Imbalanced Medical Image Recognition
Jul 20, 2023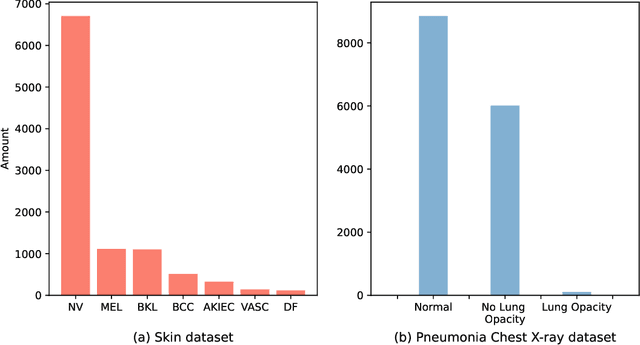

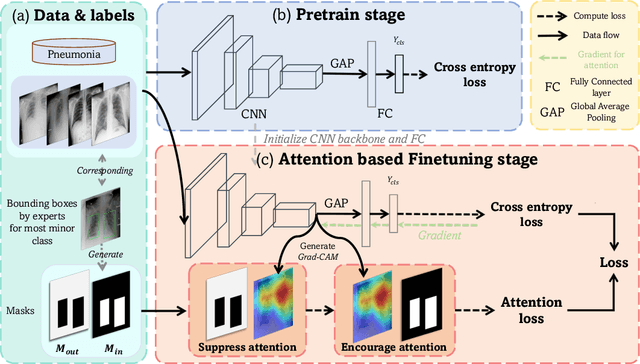
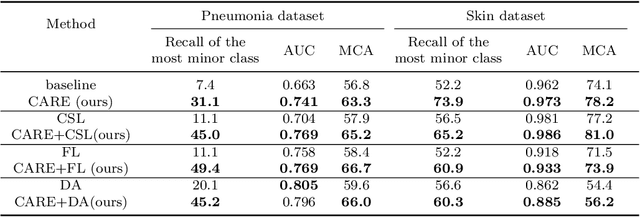
Automated medical image classification is the key component in intelligent diagnosis systems. However, most medical image datasets contain plenty of samples of common diseases and just a handful of rare ones, leading to major class imbalances. Currently, it is an open problem in intelligent diagnosis to effectively learn from imbalanced training data. In this paper, we propose a simple yet effective framework, named \textbf{C}lass \textbf{A}ttention to \textbf{RE}gions of the lesion (CARE), to handle data imbalance issues by embedding attention into the training process of \textbf{C}onvolutional \textbf{N}eural \textbf{N}etworks (CNNs). The proposed attention module helps CNNs attend to lesion regions of rare diseases, therefore helping CNNs to learn their characteristics more effectively. In addition, this attention module works only during the training phase and does not change the architecture of the original network, so it can be directly combined with any existing CNN architecture. The CARE framework needs bounding boxes to represent the lesion regions of rare diseases. To alleviate the need for manual annotation, we further developed variants of CARE by leveraging the traditional saliency methods or a pretrained segmentation model for bounding box generation. Results show that the CARE variants with automated bounding box generation are comparable to the original CARE framework with \textit{manual} bounding box annotations. A series of experiments on an imbalanced skin image dataset and a pneumonia dataset indicates that our method can effectively help the network focus on the lesion regions of rare diseases and remarkably improves the classification performance of rare diseases.
Advancing Volumetric Medical Image Segmentation via Global-Local Masked Autoencoder
Jun 15, 2023Masked autoencoder (MAE) has emerged as a promising self-supervised pretraining technique to enhance the representation learning of a neural network without human intervention. To adapt MAE onto volumetric medical images, existing methods exhibit two challenges: first, the global information crucial for understanding the clinical context of the holistic data is lacked; second, there was no guarantee of stabilizing the representations learned from the randomly masked inputs. To tackle these limitations, we proposed Global-Local Masked AutoEncoder (GL-MAE), a simple yet effective self-supervised pre-training strategy. GL-MAE reconstructs both the masked global and masked local volumes, which enables learning the essential local details as well as the global context. We further introduced global-to-global consistency and local-to-global correspondence via global-guided consistency learning to enhance and stabilize the representation learning of the masked volumes. Finetuning results on multiple datasets illustrate the superiority of our method over other state-of-the-art self-supervised algorithms, demonstrating its effectiveness on versatile volumetric medical image segmentation tasks, even when annotations are scarce. Codes and models will be released upon acceptance.
OpenMedIA: Open-Source Medical Image Analysis Toolbox and Benchmark under Heterogeneous AI Computing Platforms
Aug 11, 2022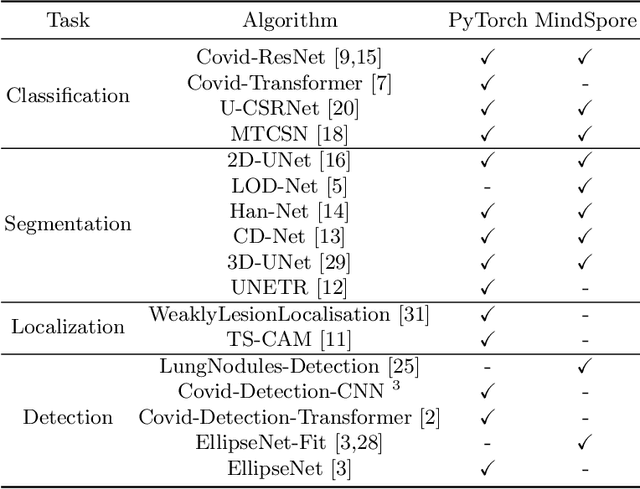
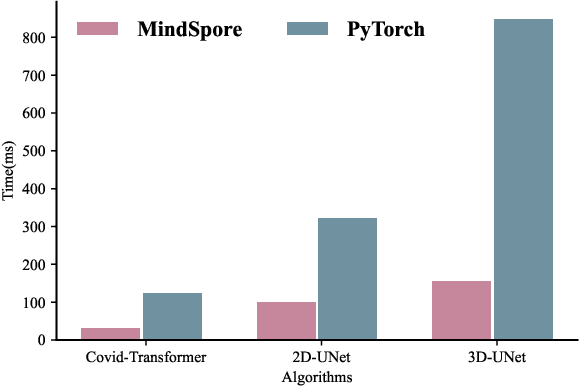
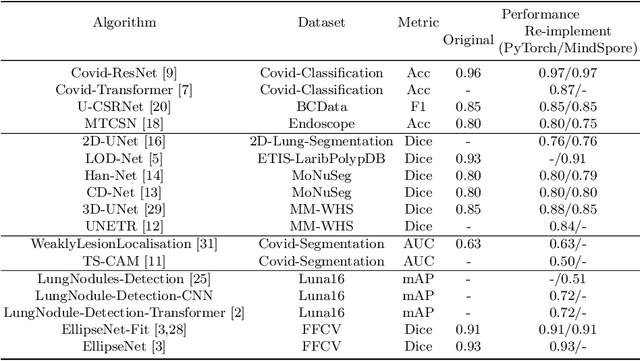
In this paper, we present OpenMedIA, an open-source toolbox library containing a rich set of deep learning methods for medical image analysis under heterogeneous Artificial Intelligence (AI) computing platforms. Various medical image analysis methods, including 2D$/$3D medical image classification, segmentation, localisation, and detection, have been included in the toolbox with PyTorch and$/$or MindSpore implementations under heterogeneous NVIDIA and Huawei Ascend computing systems. To our best knowledge, OpenMedIA is the first open-source algorithm library providing compared PyTorch and MindSp
Understanding of Kernels in CNN Models by Suppressing Irrelevant Visual Features in Images
Aug 25, 2021
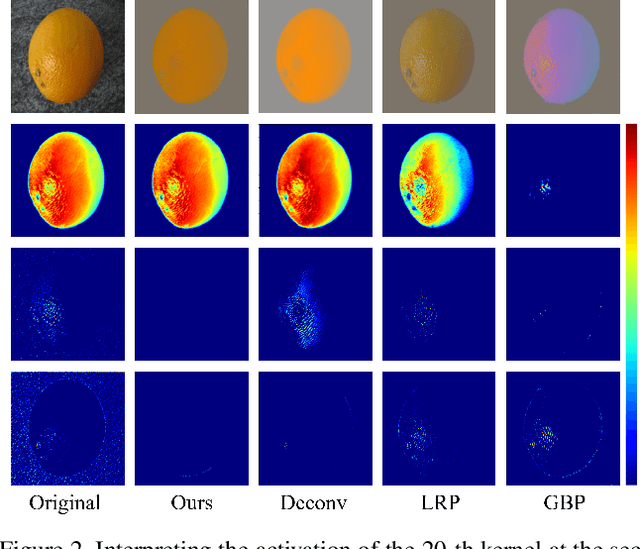

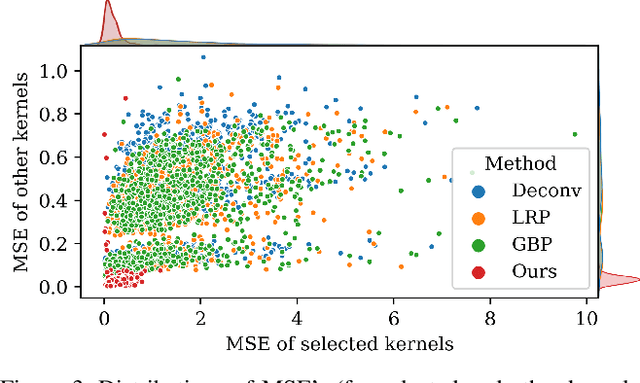
Deep learning models have shown their superior performance in various vision tasks. However, the lack of precisely interpreting kernels in convolutional neural networks (CNNs) is becoming one main obstacle to wide applications of deep learning models in real scenarios. Although existing interpretation methods may find certain visual patterns which are associated with the activation of a specific kernel, those visual patterns may not be specific or comprehensive enough for interpretation of a specific activation of kernel of interest. In this paper, a simple yet effective optimization method is proposed to interpret the activation of any kernel of interest in CNN models. The basic idea is to simultaneously preserve the activation of the specific kernel and suppress the activation of all other kernels at the same layer. In this way, only visual information relevant to the activation of the specific kernel is remained in the input. Consistent visual information from multiple modified inputs would help users understand what kind of features are specifically associated with specific kernel. Comprehensive evaluation shows that the proposed method can help better interpret activation of specific kernels than widely used methods, even when two kernels have very similar activation regions from the same input image.
Solution for Large-scale Long-tailed Recognition with Noisy Labels
Jun 20, 2021

This is a technical report for CVPR 2021 AliProducts Challenge. AliProducts Challenge is a competition proposed for studying the large-scale and fine-grained commodity image recognition problem encountered by worldleading ecommerce companies. The large-scale product recognition simultaneously meets the challenge of noisy annotations, imbalanced (long-tailed) data distribution and fine-grained classification. In our solution, we adopt stateof-the-art model architectures of both CNNs and Transformer, including ResNeSt, EfficientNetV2, and DeiT. We found that iterative data cleaning, classifier weight normalization, high-resolution finetuning, and test time augmentation are key components to improve the performance of training with the noisy and imbalanced dataset. Finally, we obtain 6.4365% mean class error rate in the leaderboard with our ensemble model.
* 3 pages
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
Apr 19, 2021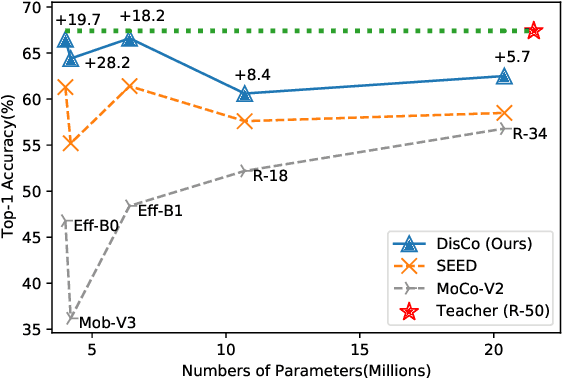
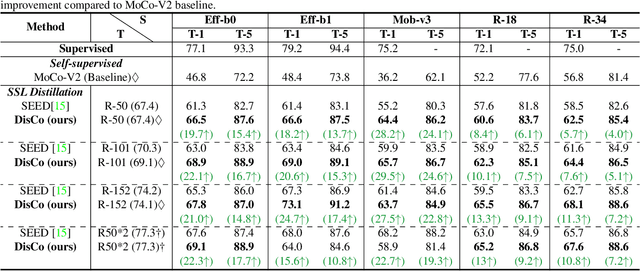
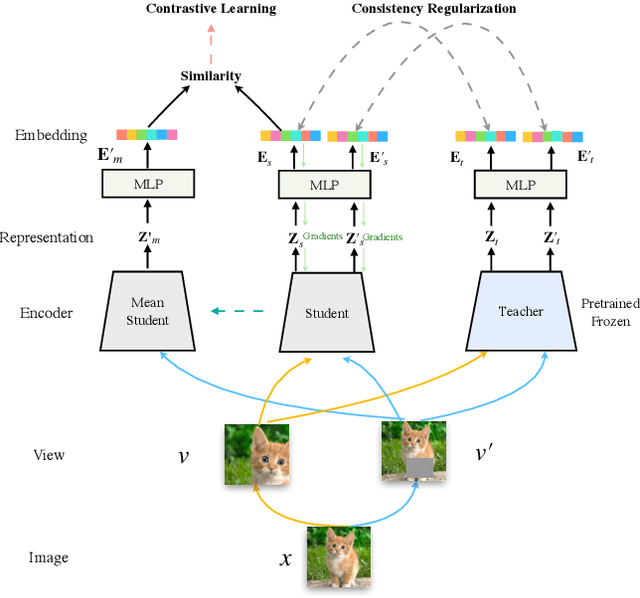
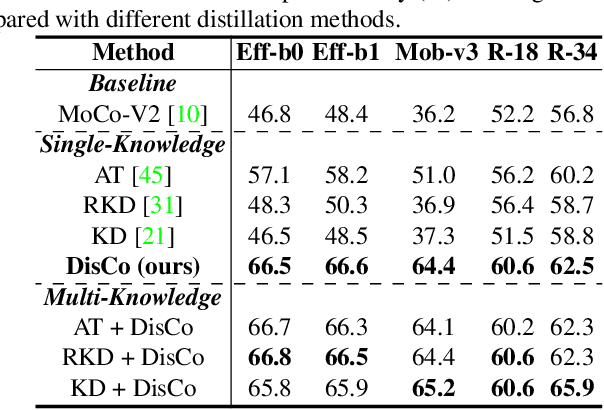
While self-supervised representation learning (SSL) has received widespread attention from the community, recent research argue that its performance will suffer a cliff fall when the model size decreases. The current method mainly relies on contrastive learning to train the network and in this work, we propose a simple yet effective Distilled Contrastive Learning (DisCo) to ease the issue by a large margin. Specifically, we find the final embedding obtained by the mainstream SSL methods contains the most fruitful information, and propose to distill the final embedding to maximally transmit a teacher's knowledge to a lightweight model by constraining the last embedding of the student to be consistent with that of the teacher. In addition, in the experiment, we find that there exists a phenomenon termed Distilling BottleNeck and present to enlarge the embedding dimension to alleviate this problem. Our method does not introduce any extra parameter to lightweight models during deployment. Experimental results demonstrate that our method achieves the state-of-the-art on all lightweight models. Particularly, when ResNet-101/ResNet-50 is used as teacher to teach EfficientNet-B0, the linear result of EfficientNet-B0 on ImageNet is very close to ResNet-101/ResNet-50, but the number of parameters of EfficientNet-B0 is only 9.4%/16.3% of ResNet-101/ResNet-50.