 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Security of Diffusion-based Generative Steganography
Feb 10, 2026Generative image steganography is a technique that conceals secret messages within generated images, without relying on pre-existing cover images. Recently, a number of diffusion model-based generative image steganography (DM-GIS) methods have been introduced, which effectively combat traditional steganalysis techniques. In this paper, we identify the key factors that influence DM-GIS security and revisit the security of existing methods. Specifically, we first provide an overview of the general pipelines of current DM-GIS methods, finding that the noise space of diffusion models serves as the primary embedding domain. Further, we analyze the relationship between DM-GIS security and noise distribution of diffusion models, theoretically demonstrating that any steganographic operation that disrupts the noise distribution compromise DM-GIS security. Building on this insight, we propose a Noise Space-based Diffusion Steganalyzer (NS-DSer)-a simple yet effective steganalysis framework allowing for detecting DM-GIS generated images in the diffusion model noise space. We reevaluate the security of existing DM-GIS methods using NS-DSer across increasingly challenging detection scenarios. Experimental results validate our theoretical analysis of DM-GIS security and show the effectiveness of NS-DSer across diverse detection scenarios.
OpenHOI: Open-World Hand-Object Interaction Synthesis with Multimodal Large Language Model
May 25, 2025Understanding and synthesizing realistic 3D hand-object interactions (HOI) is critical for applications ranging from immersive AR/VR to dexterous robotics. Existing methods struggle with generalization, performing well on closed-set objects and predefined tasks but failing to handle unseen objects or open-vocabulary instructions. We introduce OpenHOI, the first framework for open-world HOI synthesis, capable of generating long-horizon manipulation sequences for novel objects guided by free-form language commands. Our approach integrates a 3D Multimodal Large Language Model (MLLM) fine-tuned for joint affordance grounding and semantic task decomposition, enabling precise localization of interaction regions (e.g., handles, buttons) and breakdown of complex instructions (e.g., "Find a water bottle and take a sip") into executable sub-tasks. To synthesize physically plausible interactions, we propose an affordance-driven diffusion model paired with a training-free physics refinement stage that minimizes penetration and optimizes affordance alignment. Evaluations across diverse scenarios demonstrate OpenHOI's superiority over state-of-the-art methods in generalizing to novel object categories, multi-stage tasks, and complex language instructions. Our project page at \href{https://openhoi.github.io}
InfantCryNet: A Data-driven Framework for Intelligent Analysis of Infant Cries
Sep 29, 2024



Understanding the meaning of infant cries is a significant challenge for young parents in caring for their newborns. The presence of background noise and the lack of labeled data present practical challenges in developing systems that can detect crying and analyze its underlying reasons. In this paper, we present a novel data-driven framework, "InfantCryNet," for accomplishing these tasks. To address the issue of data scarcity, we employ pre-trained audio models to incorporate prior knowledge into our model. We propose the use of statistical pooling and multi-head attention pooling techniques to extract features more effectively. Additionally, knowledge distillation and model quantization are applied to enhance model efficiency and reduce the model size, better supporting industrial deployment in mobile devices. Experiments on real-life datasets demonstrate the superior performance of the proposed framework, outperforming state-of-the-art baselines by 4.4% in classification accuracy. The model compression effectively reduces the model size by 7% without compromising performance and by up to 28% with only an 8% decrease in accuracy, offering practical insights for model selection and system design.
CoCPF: Coordinate-based Continuous Projection Field for Ill-Posed Inverse Problem in Imaging
Jun 21, 2024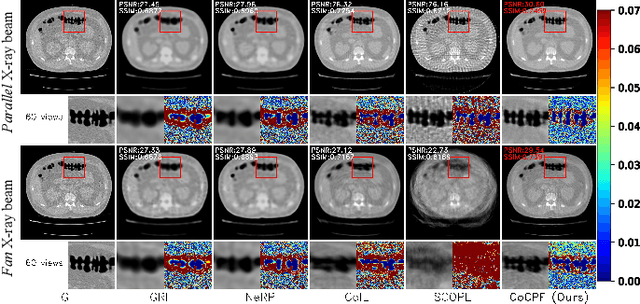
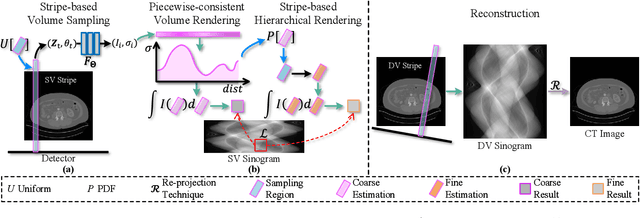
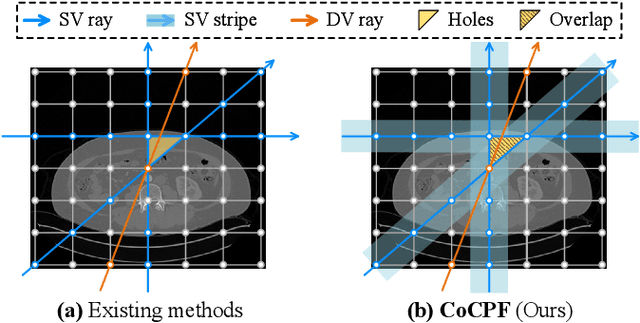
Sparse-view computed tomography (SVCT) reconstruction aims to acquire CT images based on sparsely-sampled measurements. It allows the subjects exposed to less ionizing radiation, reducing the lifetime risk of developing cancers. Recent researches employ implicit neural representation (INR) techniques to reconstruct CT images from a single SV sinogram. However, due to ill-posedness, these INR-based methods may leave considerable ``holes'' (i.e., unmodeled spaces) in their fields, leading to sub-optimal results. In this paper, we propose the Coordinate-based Continuous Projection Field (CoCPF), which aims to build hole-free representation fields for SVCT reconstruction, achieving better reconstruction quality. Specifically, to fill the holes, CoCPF first employs the stripe-based volume sampling module to broaden the sampling regions of Radon transformation from rays (1D space) to stripes (2D space), which can well cover the internal regions between SV projections. Then, by feeding the sampling regions into the proposed differentiable rendering modules, the holes can be jointly optimized during training, reducing the ill-posed levels. As a result, CoCPF can accurately estimate the internal measurements between SV projections (i.e., DV sinograms), producing high-quality CT images after re-projection. Extensive experiments on simulated and real projection datasets demonstrate that CoCPF outperforms state-of-the-art methods for 2D and 3D SVCT reconstructions under various projection numbers and geometries, yielding fine-grained details and fewer artifacts. Our code will be publicly available.
VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Jun 21, 2024

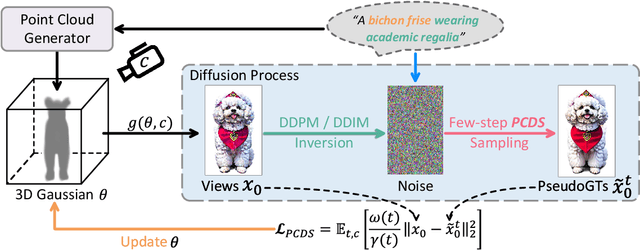
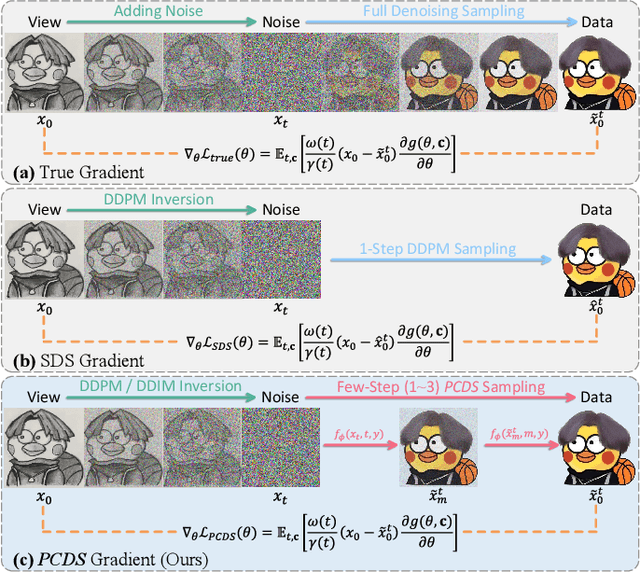
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the "true" gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
Gaze-guided Hand-Object Interaction Synthesis: Benchmark and Method
Mar 28, 2024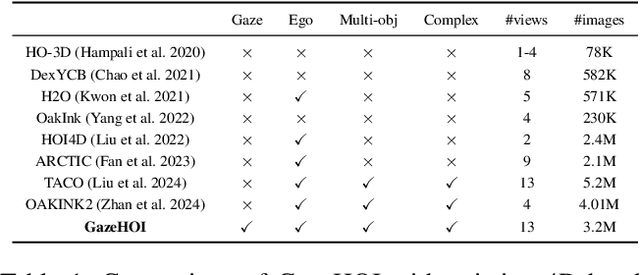
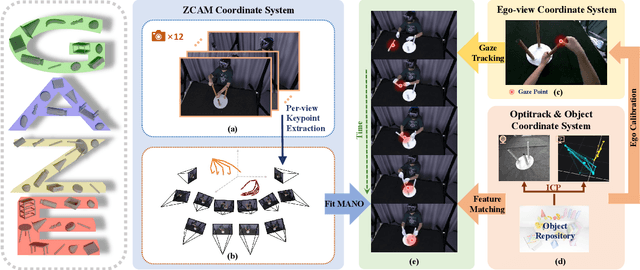

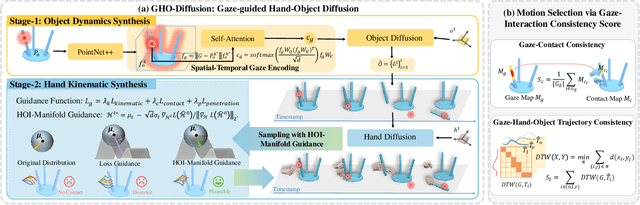
Gaze plays a crucial role in revealing human attention and intention, shedding light on the cognitive processes behind human actions. The integration of gaze guidance with the dynamics of hand-object interactions boosts the accuracy of human motion prediction. However, the lack of datasets that capture the intricate relationship and consistency among gaze, hand, and object movements remains a substantial hurdle. In this paper, we introduce the first Gaze-guided Hand-Object Interaction dataset, GazeHOI, and present a novel task for synthesizing gaze-guided hand-object interactions. Our dataset, GazeHOI, features simultaneous 3D modeling of gaze, hand, and object interactions, comprising 479 sequences with an average duration of 19.1 seconds, 812 sub-sequences, and 33 objects of various sizes. We propose a hierarchical framework centered on a gaze-guided hand-object interaction diffusion model, named GHO-Diffusion. In the pre-diffusion phase, we separate gaze conditions into spatial-temporal features and goal pose conditions at different levels of information granularity. During the diffusion phase, two gaze-conditioned diffusion models are stacked to simplify the complex synthesis of hand-object motions. Here, the object motion diffusion model generates sequences of object motions based on gaze conditions, while the hand motion diffusion model produces hand motions based on the generated object motion. To improve fine-grained goal pose alignment, we introduce a Spherical Gaussian constraint to guide the denoising step. In the subsequent post-diffusion phase, we optimize the generated hand motions using contact consistency. Our extensive experiments highlight the uniqueness of our dataset and the effectiveness of our approach.
Guidance with Spherical Gaussian Constraint for Conditional Diffusion
Feb 05, 2024



Recent advances in diffusion models attempt to handle conditional generative tasks by utilizing a differentiable loss function for guidance without the need for additional training. While these methods achieved certain success, they often compromise on sample quality and require small guidance step sizes, leading to longer sampling processes. This paper reveals that the fundamental issue lies in the manifold deviation during the sampling process when loss guidance is employed. We theoretically show the existence of manifold deviation by establishing a certain lower bound for the estimation error of the loss guidance. To mitigate this problem, we propose Diffusion with Spherical Gaussian constraint (DSG), drawing inspiration from the concentration phenomenon in high-dimensional Gaussian distributions. DSG effectively constrains the guidance step within the intermediate data manifold through optimization and enables the use of larger guidance steps. Furthermore, we present a closed-form solution for DSG denoising with the Spherical Gaussian constraint. Notably, DSG can seamlessly integrate as a plugin module within existing training-free conditional diffusion methods. Implementing DSG merely involves a few lines of additional code with almost no extra computational overhead, yet it leads to significant performance improvements. Comprehensive experimental results in various conditional generation tasks validate the superiority and adaptability of DSG in terms of both sample quality and time efficiency.
Attention-based Interactive Disentangling Network for Instance-level Emotional Voice Conversion
Dec 29, 2023
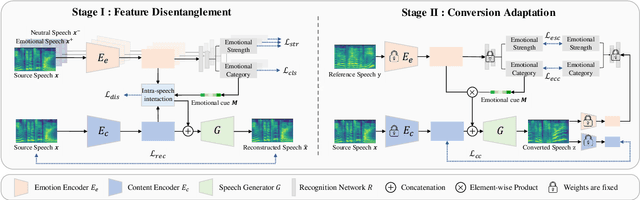
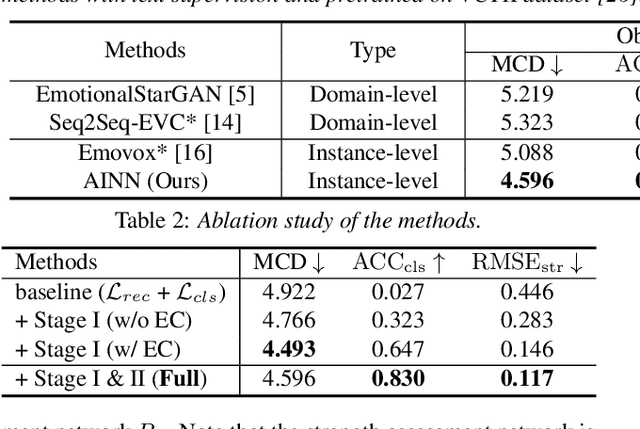
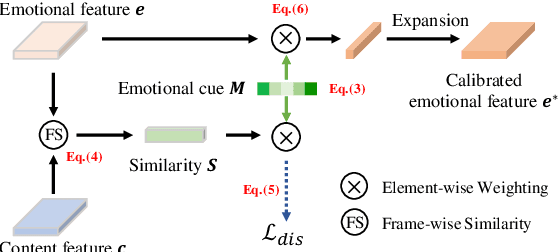
Emotional Voice Conversion aims to manipulate a speech according to a given emotion while preserving non-emotion components. Existing approaches cannot well express fine-grained emotional attributes. In this paper, we propose an Attention-based Interactive diseNtangling Network (AINN) that leverages instance-wise emotional knowledge for voice conversion. We introduce a two-stage pipeline to effectively train our network: Stage I utilizes inter-speech contrastive learning to model fine-grained emotion and intra-speech disentanglement learning to better separate emotion and content. In Stage II, we propose to regularize the conversion with a multi-view consistency mechanism. This technique helps us transfer fine-grained emotion and maintain speech content. Extensive experiments show that our AINN outperforms state-of-the-arts in both objective and subjective metrics.
APRF: Anti-Aliasing Projection Representation Field for Inverse Problem in Imaging
Jul 11, 2023



Sparse-view Computed Tomography (SVCT) reconstruction is an ill-posed inverse problem in imaging that aims to acquire high-quality CT images based on sparsely-sampled measurements. Recent works use Implicit Neural Representations (INRs) to build the coordinate-based mapping between sinograms and CT images. However, these methods have not considered the correlation between adjacent projection views, resulting in aliasing artifacts on SV sinograms. To address this issue, we propose a self-supervised SVCT reconstruction method -- Anti-Aliasing Projection Representation Field (APRF), which can build the continuous representation between adjacent projection views via the spatial constraints. Specifically, APRF only needs SV sinograms for training, which first employs a line-segment sampling module to estimate the distribution of projection views in a local region, and then synthesizes the corresponding sinogram values using center-based line integral module. After training APRF on a single SV sinogram itself, it can synthesize the corresponding dense-view (DV) sinogram with consistent continuity. High-quality CT images can be obtained by applying re-projection techniques on the predicted DV sinograms. Extensive experiments on CT images demonstrate that APRF outperforms state-of-the-art methods, yielding more accurate details and fewer artifacts. Our code will be publicly available soon.
CuNeRF: Cube-Based Neural Radiance Field for Zero-Shot Medical Image Arbitrary-Scale Super Resolution
Apr 09, 2023



Medical image arbitrary-scale super-resolution (MIASSR) has recently gained widespread attention, aiming to super sample medical volumes at arbitrary scales via a single model. However, existing MIASSR methods face two major limitations: (i) reliance on high-resolution (HR) volumes and (ii) limited generalization ability, which restricts their application in various scenarios. To overcome these limitations, we propose Cube-based Neural Radiance Field (CuNeRF), a zero-shot MIASSR framework that can yield medical images at arbitrary scales and viewpoints in a continuous domain. Unlike existing MIASSR methods that fit the mapping between low-resolution (LR) and HR volumes, CuNeRF focuses on building a coordinate-intensity continuous representation from LR volumes without the need for HR references. This is achieved by the proposed differentiable modules: including cube-based sampling, isotropic volume rendering, and cube-based hierarchical rendering. Through extensive experiments on magnetic resource imaging (MRI) and computed tomography (CT) modalities, we demonstrate that CuNeRF outperforms state-of-the-art MIASSR methods. CuNeRF yields better visual verisimilitude and reduces aliasing artifacts at various upsampling factors. Moreover, our CuNeRF does not need any LR-HR training pairs, which is more flexible and easier to be used than others. Our code will be publicly available soon.