 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Heterogeneous Language Model Optimization for Hybrid Automatic Speech Recognition
Mar 05, 2026Training automatic speech recognition (ASR) models increasingly relies on decentralized federated learning to ensure data privacy and accessibility, producing multiple local models that require effective merging. In hybrid ASR systems, while acoustic models can be merged using established methods, the language model (LM) for rescoring the N-best speech recognition list faces challenges due to the heterogeneity of non-neural n-gram models and neural network models. This paper proposes a heterogeneous LM optimization task and introduces a match-and-merge paradigm with two algorithms: the Genetic Match-and-Merge Algorithm (GMMA), using genetic operations to evolve and pair LMs, and the Reinforced Match-and-Merge Algorithm (RMMA), leveraging reinforcement learning for efficient convergence. Experiments on seven OpenSLR datasets show RMMA achieves the lowest average Character Error Rate and better generalization than baselines, converging up to seven times faster than GMMA, highlighting the paradigm's potential for scalable, privacy-preserving ASR systems.
CiteLLM: An Agentic Platform for Trustworthy Scientific Reference Discovery
Feb 26, 2026Large language models (LLMs) have created new opportunities to enhance the efficiency of scholarly activities; however, challenges persist in the ethical deployment of AI assistance, including (1) the trustworthiness of AI-generated content, (2) preservation of academic integrity and intellectual property, and (3) protection of information privacy. In this work, we present CiteLLM, a specialized agentic platform designed to enable trustworthy reference discovery for grounding author-drafted claims and statements. The system introduces a novel interaction paradigm by embedding LLM utilities directly within the LaTeX editor environment, ensuring a seamless user experience and no data transmission outside the local system. To guarantee hallucination-free references, we employ dynamic discipline-aware routing to retrieve candidates exclusively from trusted web-based academic repositories, while leveraging LLMs solely for generating context-aware search queries, ranking candidates by relevance, and validating and explaining support through paragraph-level semantic matching and an integrated chatbot. Evaluation results demonstrate the superior performance of the proposed system in returning valid and highly usable references.
Orchestration-Free Customer Service Automation: A Privacy-Preserving and Flowchart-Guided Framework
Feb 17, 2026Customer service automation has seen growing demand within digital transformation. Existing approaches either rely on modular system designs with extensive agent orchestration or employ over-simplified instruction schemas, providing limited guidance and poor generalizability. This paper introduces an orchestration-free framework using Task-Oriented Flowcharts (TOFs) to enable end-to-end automation without manual intervention. We first define the components and evaluation metrics for TOFs, then formalize a cost-efficient flowchart construction algorithm to abstract procedural knowledge from service dialogues. We emphasize local deployment of small language models and propose decentralized distillation with flowcharts to mitigate data scarcity and privacy issues in model training. Extensive experiments validate the effectiveness in various service tasks, with superior quantitative and application performance compared to strong baselines and market products. By releasing a web-based system demonstration with case studies, we aim to promote streamlined creation of future service automation.
RAL2M: Retrieval Augmented Learning-To-Match Against Hallucination in Compliance-Guaranteed Service Systems
Jan 06, 2026Hallucination is a major concern in LLM-driven service systems, necessitating explicit knowledge grounding for compliance-guaranteed responses. In this paper, we introduce Retrieval-Augmented Learning-to-Match (RAL2M), a novel framework that eliminates generation hallucination by repositioning LLMs as query-response matching judges within a retrieval-based system, providing a robust alternative to purely generative approaches. To further mitigate judgment hallucination, we propose a query-adaptive latent ensemble strategy that explicitly models heterogeneous model competence and interdependencies among LLMs, deriving a calibrated consensus decision. Extensive experiments on large-scale benchmarks demonstrate that the proposed method effectively leverages the "wisdom of the crowd" and significantly outperforms strong baselines. Finally, we discuss best practices and promising directions for further exploiting latent representations in future work.
Multimodal Peer Review Simulation with Actionable To-Do Recommendations for Community-Aware Manuscript Revisions
Nov 14, 2025



While large language models (LLMs) offer promising capabilities for automating academic workflows, existing systems for academic peer review remain constrained by text-only inputs, limited contextual grounding, and a lack of actionable feedback. In this work, we present an interactive web-based system for multimodal, community-aware peer review simulation to enable effective manuscript revisions before paper submission. Our framework integrates textual and visual information through multimodal LLMs, enhances review quality via retrieval-augmented generation (RAG) grounded in web-scale OpenReview data, and converts generated reviews into actionable to-do lists using the proposed Action:Objective[\#] format, providing structured and traceable guidance. The system integrates seamlessly into existing academic writing platforms, providing interactive interfaces for real-time feedback and revision tracking. Experimental results highlight the effectiveness of the proposed system in generating more comprehensive and useful reviews aligned with expert standards, surpassing ablated baselines and advancing transparent, human-centered scholarly assistance.
Contextualized Token Discrimination for Speech Search Query Correction
Sep 04, 2025



Query spelling correction is an important function of modern search engines since it effectively helps users express their intentions clearly. With the growing popularity of speech search driven by Automated Speech Recognition (ASR) systems, this paper introduces a novel method named Contextualized Token Discrimination (CTD) to conduct effective speech query correction. In CTD, we first employ BERT to generate token-level contextualized representations and then construct a composition layer to enhance semantic information. Finally, we produce the correct query according to the aggregated token representation, correcting the incorrect tokens by comparing the original token representations and the contextualized representations. Extensive experiments demonstrate the superior performance of our proposed method across all metrics, and we further present a new benchmark dataset with erroneous ASR transcriptions to offer comprehensive evaluations for audio query correction.
Technical Report: A Practical Guide to Kaldi ASR Optimization
Jun 08, 2025This technical report introduces innovative optimizations for Kaldi-based Automatic Speech Recognition (ASR) systems, focusing on acoustic model enhancement, hyperparameter tuning, and language model efficiency. We developed a custom Conformer block integrated with a multistream TDNN-F structure, enabling superior feature extraction and temporal modeling. Our approach includes advanced data augmentation techniques and dynamic hyperparameter optimization to boost performance and reduce overfitting. Additionally, we propose robust strategies for language model management, employing Bayesian optimization and $n$-gram pruning to ensure relevance and computational efficiency. These systematic improvements significantly elevate ASR accuracy and robustness, outperforming existing methods and offering a scalable solution for diverse speech recognition scenarios. This report underscores the importance of strategic optimizations in maintaining Kaldi's adaptability and competitiveness in rapidly evolving technological landscapes.
QualBench: Benchmarking Chinese LLMs with Localized Professional Qualifications for Vertical Domain Evaluation
May 08, 2025
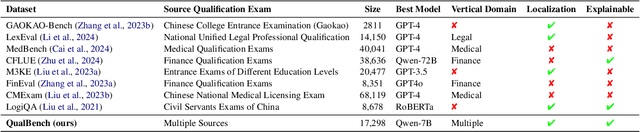

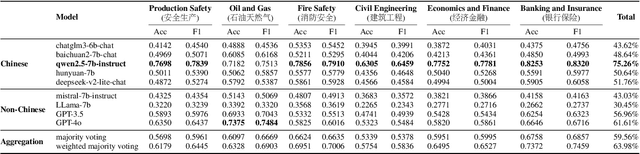
The rapid advancement of Chinese large language models (LLMs) underscores the need for domain-specific evaluations to ensure reliable applications. However, existing benchmarks often lack coverage in vertical domains and offer limited insights into the Chinese working context. Leveraging qualification exams as a unified framework for human expertise evaluation, we introduce QualBench, the first multi-domain Chinese QA benchmark dedicated to localized assessment of Chinese LLMs. The dataset includes over 17,000 questions across six vertical domains, with data selections grounded in 24 Chinese qualifications to closely align with national policies and working standards. Through comprehensive evaluation, the Qwen2.5 model outperformed the more advanced GPT-4o, with Chinese LLMs consistently surpassing non-Chinese models, highlighting the importance of localized domain knowledge in meeting qualification requirements. The best performance of 75.26% reveals the current gaps in domain coverage within model capabilities. Furthermore, we present the failure of LLM collaboration with crowdsourcing mechanisms and suggest the opportunities for multi-domain RAG knowledge enhancement and vertical domain LLM training with Federated Learning.
Dial-In LLM: Human-Aligned Dialogue Intent Clustering with LLM-in-the-loop
Dec 12, 2024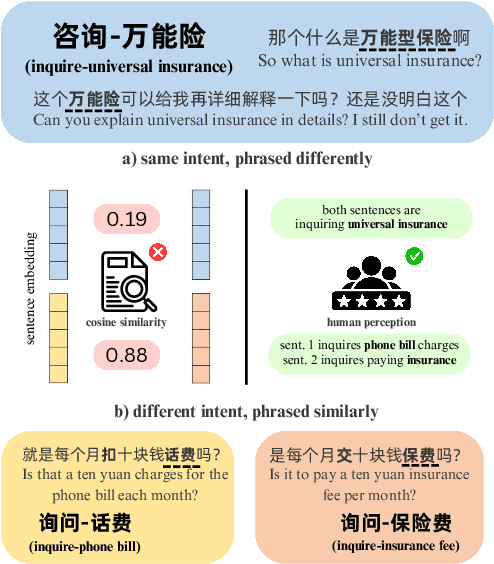
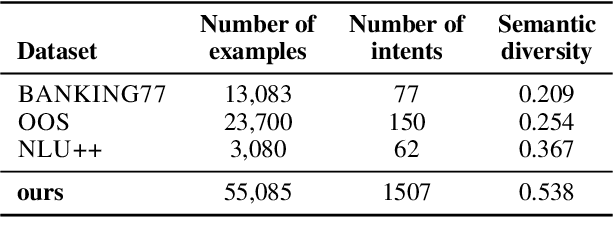
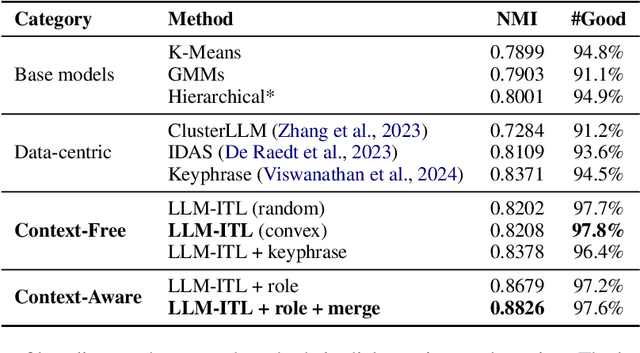
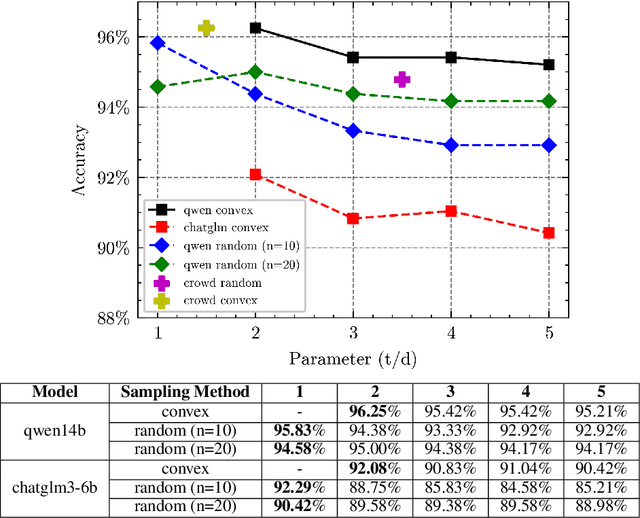
The discovery of customer intention from dialogue plays an important role in automated support system. However, traditional text clustering methods are poorly aligned with human perceptions due to the shift from embedding distance to semantic distance, and existing quantitative metrics for text clustering may not accurately reflect the true quality of intent clusters. In this paper, we leverage the superior language understanding capabilities of Large Language Models (LLMs) for designing better-calibrated intent clustering algorithms. We first establish the foundation by verifying the robustness of fine-tuned LLM utility in semantic coherence evaluation and cluster naming, resulting in an accuracy of 97.50% and 94.40%, respectively, when compared to the human-labeled ground truth. Then, we propose an iterative clustering algorithm that facilitates cluster-level refinement and the continuous discovery of high-quality intent clusters. Furthermore, we present several LLM-in-the-loop semi-supervised clustering techniques tailored for intent discovery from customer service dialogue. Experiments on a large-scale industrial dataset comprising 1,507 intent clusters demonstrate the effectiveness of the proposed techniques. The methods outperformed existing counterparts, achieving 6.25% improvement in quantitative metrics and 12% enhancement in application-level performance when constructing an intent classifier.
Dialogue Language Model with Large-Scale Persona Data Engineering
Dec 12, 2024

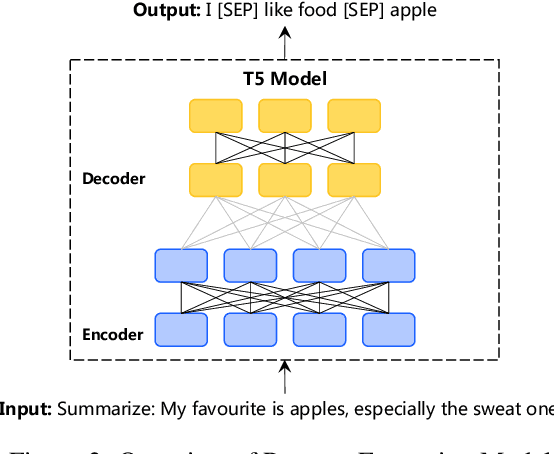
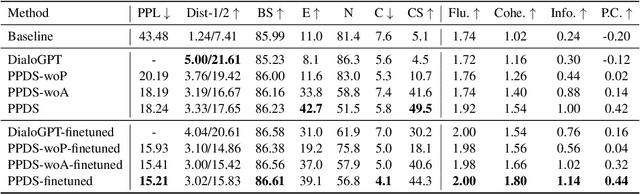
Maintaining persona consistency is paramount in the application of open-domain dialogue systems, as exemplified by models like ChatGPT. Despite significant advancements, the limited scale and diversity of current persona dialogue datasets remain challenges to achieving robust persona-consistent dialogue models. In this study, drawing inspiration from the success of large-scale pre-training, we introduce PPDS, an open-domain persona dialogue system that employs extensive generative pre-training on a persona dialogue dataset to enhance persona consistency. Specifically, we present a persona extraction model designed to autonomously and precisely generate vast persona dialogue datasets. Additionally, we unveil a pioneering persona augmentation technique to address the invalid persona bias inherent in the constructed dataset. Both quantitative and human evaluations consistently highlight the superior response quality and persona consistency of our proposed model, underscoring its effectiveness.