 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAL2M: Retrieval Augmented Learning-To-Match Against Hallucination in Compliance-Guaranteed Service Systems
Jan 06, 2026Hallucination is a major concern in LLM-driven service systems, necessitating explicit knowledge grounding for compliance-guaranteed responses. In this paper, we introduce Retrieval-Augmented Learning-to-Match (RAL2M), a novel framework that eliminates generation hallucination by repositioning LLMs as query-response matching judges within a retrieval-based system, providing a robust alternative to purely generative approaches. To further mitigate judgment hallucination, we propose a query-adaptive latent ensemble strategy that explicitly models heterogeneous model competence and interdependencies among LLMs, deriving a calibrated consensus decision. Extensive experiments on large-scale benchmarks demonstrate that the proposed method effectively leverages the "wisdom of the crowd" and significantly outperforms strong baselines. Finally, we discuss best practices and promising directions for further exploiting latent representations in future work.
Multimodal Peer Review Simulation with Actionable To-Do Recommendations for Community-Aware Manuscript Revisions
Nov 14, 2025



While large language models (LLMs) offer promising capabilities for automating academic workflows, existing systems for academic peer review remain constrained by text-only inputs, limited contextual grounding, and a lack of actionable feedback. In this work, we present an interactive web-based system for multimodal, community-aware peer review simulation to enable effective manuscript revisions before paper submission. Our framework integrates textual and visual information through multimodal LLMs, enhances review quality via retrieval-augmented generation (RAG) grounded in web-scale OpenReview data, and converts generated reviews into actionable to-do lists using the proposed Action:Objective[\#] format, providing structured and traceable guidance. The system integrates seamlessly into existing academic writing platforms, providing interactive interfaces for real-time feedback and revision tracking. Experimental results highlight the effectiveness of the proposed system in generating more comprehensive and useful reviews aligned with expert standards, surpassing ablated baselines and advancing transparent, human-centered scholarly assistance.
Dial-In LLM: Human-Aligned Dialogue Intent Clustering with LLM-in-the-loop
Dec 12, 2024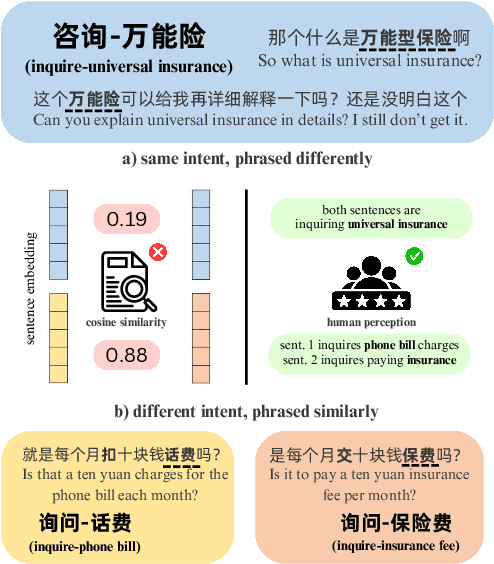
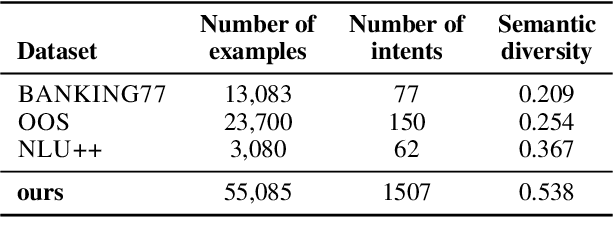
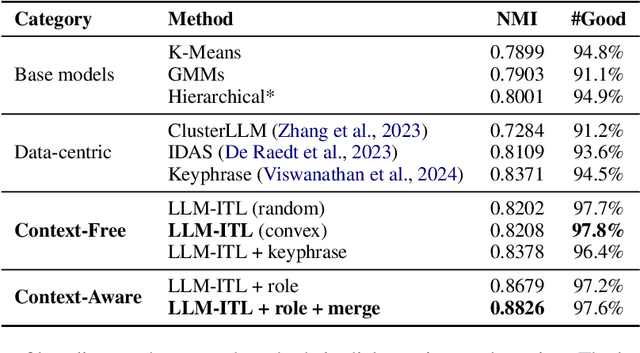
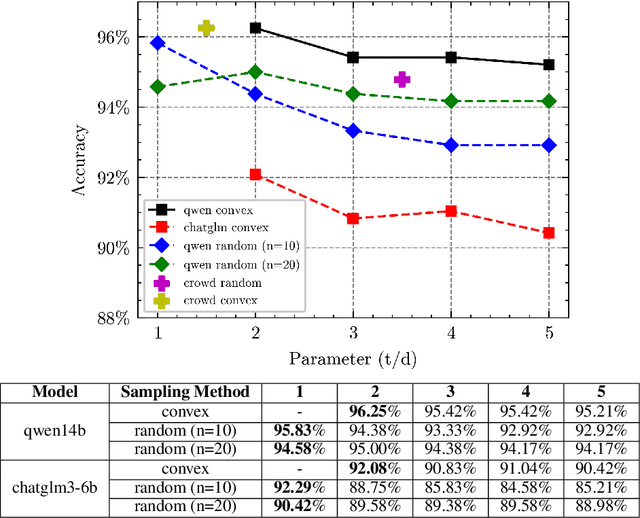
The discovery of customer intention from dialogue plays an important role in automated support system. However, traditional text clustering methods are poorly aligned with human perceptions due to the shift from embedding distance to semantic distance, and existing quantitative metrics for text clustering may not accurately reflect the true quality of intent clusters. In this paper, we leverage the superior language understanding capabilities of Large Language Models (LLMs) for designing better-calibrated intent clustering algorithms. We first establish the foundation by verifying the robustness of fine-tuned LLM utility in semantic coherence evaluation and cluster naming, resulting in an accuracy of 97.50% and 94.40%, respectively, when compared to the human-labeled ground truth. Then, we propose an iterative clustering algorithm that facilitates cluster-level refinement and the continuous discovery of high-quality intent clusters. Furthermore, we present several LLM-in-the-loop semi-supervised clustering techniques tailored for intent discovery from customer service dialogue. Experiments on a large-scale industrial dataset comprising 1,507 intent clusters demonstrate the effectiveness of the proposed techniques. The methods outperformed existing counterparts, achieving 6.25% improvement in quantitative metrics and 12% enhancement in application-level performance when constructing an intent classifier.
Contrastive Learning-based Chaining-Cluster for Multilingual Voice-Face Association
Aug 04, 2024



The innate correlation between a person's face and voice has recently emerged as a compelling area of study, especially within the context of multilingual environments. This paper introduces our novel solution to the Face-Voice Association in Multilingual Environments (FAME) 2024 challenge, focusing on a contrastive learning-based chaining-cluster method to enhance face-voice association. This task involves the challenges of building biometric relations between auditory and visual modality cues and modelling the prosody interdependence between different languages while addressing both intrinsic and extrinsic variability present in the data. To handle these non-trivial challenges, our method employs supervised cross-contrastive (SCC) learning to establish robust associations between voices and faces in multi-language scenarios. Following this, we have specifically designed a chaining-cluster-based post-processing step to mitigate the impact of outliers often found in unconstrained in the wild data. We conducted extensive experiments to investigate the impact of language on face-voice association. The overall results were evaluated on the FAME public evaluation platform, where we achieved 2nd place. The results demonstrate the superior performance of our method, and we validate the robustness and effectiveness of our proposed approach. Code is available at https://github.com/colaudiolab/FAME24_solution.
Efficient Commercial Bank Customer Credit Risk Assessment Based on LightGBM and Feature Engineering
Aug 17, 2023Effective control of credit risk is a key link in the steady operation of commercial banks. This paper is mainly based on the customer information dataset of a foreign commercial bank in Kaggle, and we use LightGBM algorithm to build a classifier to classify customers, to help the bank judge the possibility of customer credit default. This paper mainly deals with characteristic engineering, such as missing value processing, coding, imbalanced samples, etc., which greatly improves the machine learning effect. The main innovation of this paper is to construct new feature attributes on the basis of the original dataset so that the accuracy of the classifier reaches 0.734, and the AUC reaches 0.772, which is more than many classifiers based on the same dataset. The model can provide some reference for commercial banks' credit granting, and also provide some feature processing ideas for other similar studies.
Adaptive color transfer from images to terrain visualizations
May 30, 2022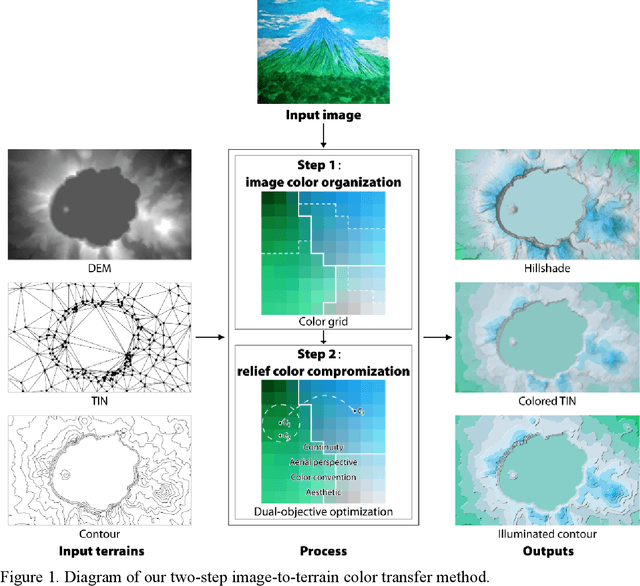
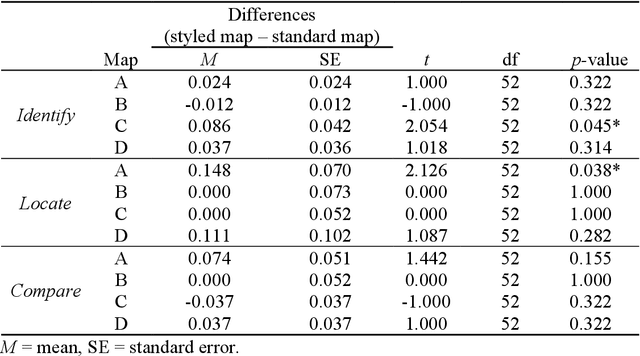

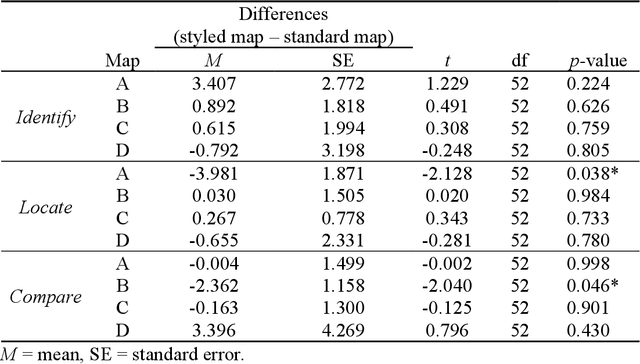
Terrain mapping is not only dedicated to communicating how high or how steep a landscape is but can also help to narrate how we feel about a place. However, crafting effective and expressive hypsometric tints is challenging for both nonexperts and experts. In this paper, we present a two-step image-to-terrain color transfer method that can transfer color from arbitrary images to diverse terrain models. First, we present a new image color organization method that organizes discrete, irregular image colors into a continuous, regular color grid that facilitates a series of color operations, such as local and global searching, categorical color selection and sequential color interpolation. Second, we quantify a series of subjective concerns about elevation color crafting, such as "the lower, the higher" principle, color conventions, and aerial perspectives. We also define color similarity between image and terrain visualization with aesthetic quality. We then mathematically formulate image-to-terrain color transfer as a dual-objective optimization problem and offer a heuristic searching method to solve the problem. Finally, we compare elevation tints from our method with a standard color scheme on four test terrains. The evaluations show that the hypsometric tints from the proposed method can work as effectively as the standard scheme and that our tints are more visually favorable. We also showcase that our method can transfer emotion from image to terrain visualization.