 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAny: Merge Anything for Multimodal Continual Instruction Tuning
Apr 15, 2026Multimodal Continual Instruction Tuning (MCIT) is essential for sequential task adaptation of Multimodal Large Language Models (MLLMs) but is severely restricted by catastrophic forgetting. While existing literature focuses on the reasoning language backbone, in this work, we expose a critical yet neglected dual-forgetting phenomenon across both perception drift in Cross-modal Projection Space and reasoning collapse in Low-rank Parameter Space. To resolve this, we present \textbf{MAny} (\textbf{M}erge \textbf{Any}thing), a framework that merges task-specific knowledge through \textbf{C}ross-modal \textbf{P}rojection \textbf{M}erging (\textbf{CPM}) and \textbf{L}ow-rank \textbf{P}arameter \textbf{M}erging (\textbf{LPM}). Specifically, CPM recovers perceptual alignment by adaptively merging cross-modal visual representations via visual-prototype guidance, ensuring accurate feature recovery during inference. Simultaneously, LPM eliminates mutual interference among task-specific low-rank modules by recursively merging low-rank weight matrices. By leveraging recursive least squares, LPM provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability. Notably, MAny operates as a training-free paradigm that achieves knowledge merging via efficient CPU-based algebraic operations, eliminating additional gradient-based optimization beyond initial tuning. Our extensive evaluations confirm the superior performance and robustness of MAny across multiple MLLMs and benchmarks. Specifically, on the UCIT benchmark, MAny achieves significant leads of up to 8.57\% and 2.85\% in final average accuracy over state-of-the-art methods across two different MLLMs, respectively.
Transolver is a Linear Transformer: Revisiting Physics-Attention through the Lens of Linear Attention
Nov 11, 2025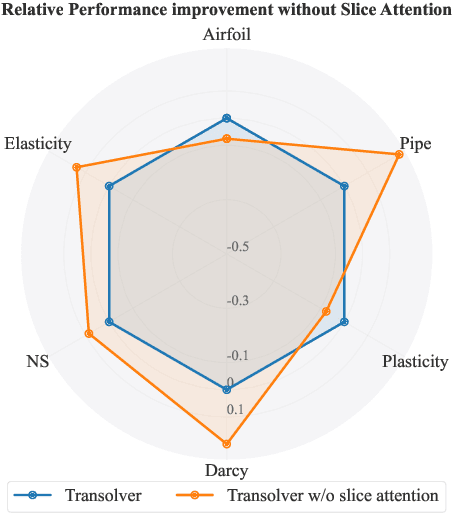
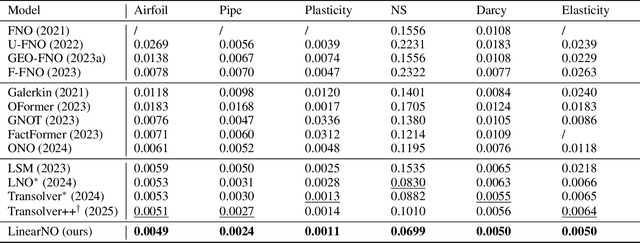
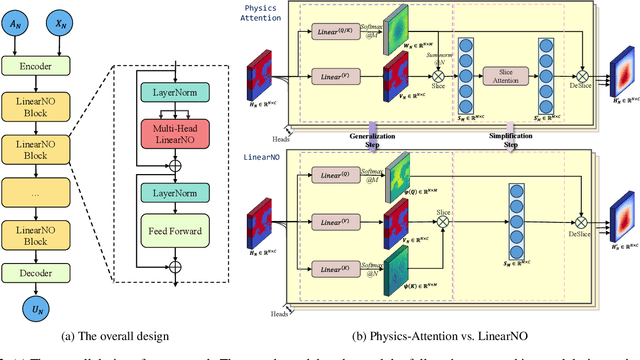
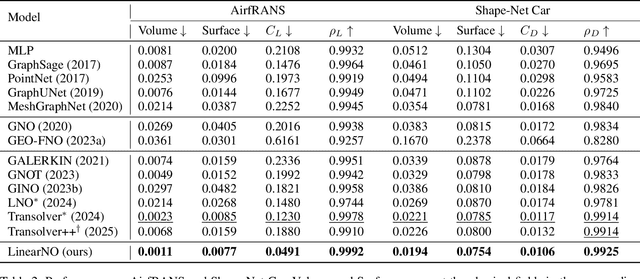
Recent advances in Transformer-based Neural Operators have enabled significant progress in data-driven solvers for Partial Differential Equations (PDEs). Most current research has focused on reducing the quadratic complexity of attention to address the resulting low training and inference efficiency. Among these works, Transolver stands out as a representative method that introduces Physics-Attention to reduce computational costs. Physics-Attention projects grid points into slices for slice attention, then maps them back through deslicing. However, we observe that Physics-Attention can be reformulated as a special case of linear attention, and that the slice attention may even hurt the model performance. Based on these observations, we argue that its effectiveness primarily arises from the slice and deslice operations rather than interactions between slices. Building on this insight, we propose a two-step transformation to redesign Physics-Attention into a canonical linear attention, which we call Linear Attention Neural Operator (LinearNO). Our method achieves state-of-the-art performance on six standard PDE benchmarks, while reducing the number of parameters by an average of 40.0% and computational cost by 36.2%. Additionally, it delivers superior performance on two challenging, industrial-level datasets: AirfRANS and Shape-Net Car.
Mono3R: Exploiting Monocular Cues for Geometric 3D Reconstruction
Apr 18, 2025Recent advances in data-driven geometric multi-view 3D reconstruction foundation models (e.g., DUSt3R) have shown remarkable performance across various 3D vision tasks, facilitated by the release of large-scale, high-quality 3D datasets. However, as we observed, constrained by their matching-based principles, the reconstruction quality of existing models suffers significant degradation in challenging regions with limited matching cues, particularly in weakly textured areas and low-light conditions. To mitigate these limitations, we propose to harness the inherent robustness of monocular geometry estimation to compensate for the inherent shortcomings of matching-based methods. Specifically, we introduce a monocular-guided refinement module that integrates monocular geometric priors into multi-view reconstruction frameworks. This integration substantially enhances the robustness of multi-view reconstruction systems, leading to high-quality feed-forward reconstructions. Comprehensive experiments across multiple benchmarks demonstrate that our method achieves substantial improvements in both mutli-view camera pose estimation and point cloud accuracy.
Regist3R: Incremental Registration with Stereo Foundation Model
Apr 16, 2025Multi-view 3D reconstruction has remained an essential yet challenging problem in the field of computer vision. While DUSt3R and its successors have achieved breakthroughs in 3D reconstruction from unposed images, these methods exhibit significant limitations when scaling to multi-view scenarios, including high computational cost and cumulative error induced by global alignment. To address these challenges, we propose Regist3R, a novel stereo foundation model tailored for efficient and scalable incremental reconstruction. Regist3R leverages an incremental reconstruction paradigm, enabling large-scale 3D reconstructions from unordered and many-view image collections. We evaluate Regist3R on public datasets for camera pose estimation and 3D reconstruction. Our experiments demonstrate that Regist3R achieves comparable performance with optimization-based methods while significantly improving computational efficiency, and outperforms existing multi-view reconstruction models. Furthermore, to assess its performance in real-world applications, we introduce a challenging oblique aerial dataset which has long spatial spans and hundreds of views. The results highlight the effectiveness of Regist3R. We also demonstrate the first attempt to reconstruct large-scale scenes encompassing over thousands of views through pointmap-based foundation models, showcasing its potential for practical applications in large-scale 3D reconstruction tasks, including urban modeling, aerial mapping, and beyond.
Highly Parallelized Reinforcement Learning Training with Relaxed Assignment Dependencies
Feb 27, 2025As the demands for superior agents grow, the training complexity of Deep Reinforcement Learning (DRL) becomes higher. Thus, accelerating training of DRL has become a major research focus. Dividing the DRL training process into subtasks and using parallel computation can effectively reduce training costs. However, current DRL training systems lack sufficient parallelization due to data assignment between subtask components. This assignment issue has been ignored, but addressing it can further boost training efficiency. Therefore, we propose a high-throughput distributed RL training system called TianJi. It relaxes assignment dependencies between subtask components and enables event-driven asynchronous communication. Meanwhile, TianJi maintains clear boundaries between subtask components. To address convergence uncertainty from relaxed assignment dependencies, TianJi proposes a distributed strategy based on the balance of sample production and consumption. The strategy controls the staleness of samples to correct their quality, ensuring convergence. We conducted extensive experiments. TianJi achieves a convergence time acceleration ratio of up to 4.37 compared to related comparison systems. When scaled to eight computational nodes, TianJi shows a convergence time speedup of 1.6 and a throughput speedup of 7.13 relative to XingTian, demonstrating its capability to accelerate training and scalability. In data transmission efficiency experiments, TianJi significantly outperforms other systems, approaching hardware limits. TianJi also shows effectiveness in on-policy algorithms, achieving convergence time acceleration ratios of 4.36 and 2.95 compared to RLlib and XingTian. TianJi is accessible at https://github.com/HiPRL/TianJi.git.
Audio-Language Models for Audio-Centric Tasks: A survey
Jan 25, 2025



Audio-Language Models (ALMs), which are trained on audio-text data, focus on the processing, understanding, and reasoning of sounds. Unlike traditional supervised learning approaches learning from predefined labels, ALMs utilize natural language as a supervision signal, which is more suitable for describing complex real-world audio recordings. ALMs demonstrate strong zero-shot capabilities and can be flexibly adapted to diverse downstream tasks. These strengths not only enhance the accuracy and generalization of audio processing tasks but also promote the development of models that more closely resemble human auditory perception and comprehension. Recent advances in ALMs have positioned them at the forefront of computer audition research, inspiring a surge of efforts to advance ALM technologies. Despite rapid progress in the field of ALMs, there is still a notable lack of systematic surveys that comprehensively organize and analyze developments. In this paper, we present a comprehensive review of ALMs with a focus on general audio tasks, aiming to fill this gap by providing a structured and holistic overview of ALMs. Specifically, we cover: (1) the background of computer audition and audio-language models; (2) the foundational aspects of ALMs, including prevalent network architectures, training objectives, and evaluation methods; (3) foundational pre-training and audio-language pre-training approaches; (4) task-specific fine-tuning, multi-task tuning and agent systems for downstream applications; (5) datasets and benchmarks; and (6) current challenges and future directions. Our review provides a clear technical roadmap for researchers to understand the development and future trends of existing technologies, offering valuable references for implementation in real-world scenarios.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Contrastive Learning-based Chaining-Cluster for Multilingual Voice-Face Association
Aug 04, 2024



The innate correlation between a person's face and voice has recently emerged as a compelling area of study, especially within the context of multilingual environments. This paper introduces our novel solution to the Face-Voice Association in Multilingual Environments (FAME) 2024 challenge, focusing on a contrastive learning-based chaining-cluster method to enhance face-voice association. This task involves the challenges of building biometric relations between auditory and visual modality cues and modelling the prosody interdependence between different languages while addressing both intrinsic and extrinsic variability present in the data. To handle these non-trivial challenges, our method employs supervised cross-contrastive (SCC) learning to establish robust associations between voices and faces in multi-language scenarios. Following this, we have specifically designed a chaining-cluster-based post-processing step to mitigate the impact of outliers often found in unconstrained in the wild data. We conducted extensive experiments to investigate the impact of language on face-voice association. The overall results were evaluated on the FAME public evaluation platform, where we achieved 2nd place. The results demonstrate the superior performance of our method, and we validate the robustness and effectiveness of our proposed approach. Code is available at https://github.com/colaudiolab/FAME24_solution.
VoxNeuS: Enhancing Voxel-Based Neural Surface Reconstruction via Gradient Interpolation
Jun 11, 2024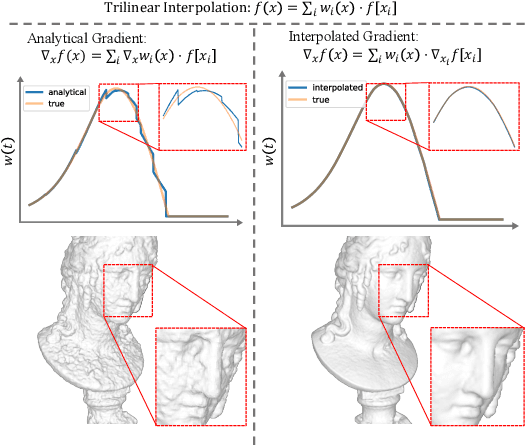
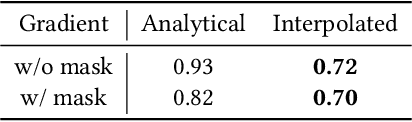
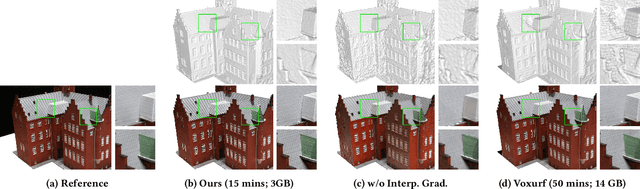
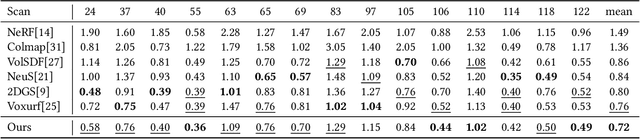
Neural Surface Reconstruction learns a Signed Distance Field~(SDF) to reconstruct the 3D model from multi-view images. Previous works adopt voxel-based explicit representation to improve efficiency. However, they ignored the gradient instability of interpolation in the voxel grid, leading to degradation on convergence and smoothness. Besides, previous works entangled the optimization of geometry and radiance, which leads to the deformation of geometry to explain radiance, causing artifacts when reconstructing textured planes. In this work, we reveal that the instability of gradient comes from its discontinuity during trilinear interpolation, and propose to use the interpolated gradient instead of the original analytical gradient to eliminate the discontinuity. Based on gradient interpolation, we propose VoxNeuS, a lightweight surface reconstruction method for computational and memory efficient neural surface reconstruction. Thanks to the explicit representation, the gradient of regularization terms, i.e. Eikonal and curvature loss, are directly solved, avoiding computation and memory-access overhead. Further, VoxNeuS adopts a geometry-radiance disentangled architecture to handle the geometry deformation from radiance optimization. The experimental results show that VoxNeuS achieves better reconstruction quality than previous works. The entire training process takes 15 minutes and less than 3 GB of memory on a single 2080ti GPU.
DistGrid: Scalable Scene Reconstruction with Distributed Multi-resolution Hash Grid
May 08, 2024



Neural Radiance Field~(NeRF) achieves extremely high quality in object-scaled and indoor scene reconstruction. However, there exist some challenges when reconstructing large-scale scenes. MLP-based NeRFs suffer from limited network capacity, while volume-based NeRFs are heavily memory-consuming when the scene resolution increases. Recent approaches propose to geographically partition the scene and learn each sub-region using an individual NeRF. Such partitioning strategies help volume-based NeRF exceed the single GPU memory limit and scale to larger scenes. However, this approach requires multiple background NeRF to handle out-of-partition rays, which leads to redundancy of learning. Inspired by the fact that the background of current partition is the foreground of adjacent partition, we propose a scalable scene reconstruction method based on joint Multi-resolution Hash Grids, named DistGrid. In this method, the scene is divided into multiple closely-paved yet non-overlapped Axis-Aligned Bounding Boxes, and a novel segmented volume rendering method is proposed to handle cross-boundary rays, thereby eliminating the need for background NeRFs. The experiments demonstrate that our method outperforms existing methods on all evaluated large-scale scenes, and provides visually plausible scene reconstruction. The scalability of our method on reconstruction quality is further evaluated qualitatively and quantitatively.