 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Parallelized Reinforcement Learning Training with Relaxed Assignment Dependencies
Feb 27, 2025As the demands for superior agents grow, the training complexity of Deep Reinforcement Learning (DRL) becomes higher. Thus, accelerating training of DRL has become a major research focus. Dividing the DRL training process into subtasks and using parallel computation can effectively reduce training costs. However, current DRL training systems lack sufficient parallelization due to data assignment between subtask components. This assignment issue has been ignored, but addressing it can further boost training efficiency. Therefore, we propose a high-throughput distributed RL training system called TianJi. It relaxes assignment dependencies between subtask components and enables event-driven asynchronous communication. Meanwhile, TianJi maintains clear boundaries between subtask components. To address convergence uncertainty from relaxed assignment dependencies, TianJi proposes a distributed strategy based on the balance of sample production and consumption. The strategy controls the staleness of samples to correct their quality, ensuring convergence. We conducted extensive experiments. TianJi achieves a convergence time acceleration ratio of up to 4.37 compared to related comparison systems. When scaled to eight computational nodes, TianJi shows a convergence time speedup of 1.6 and a throughput speedup of 7.13 relative to XingTian, demonstrating its capability to accelerate training and scalability. In data transmission efficiency experiments, TianJi significantly outperforms other systems, approaching hardware limits. TianJi also shows effectiveness in on-policy algorithms, achieving convergence time acceleration ratios of 4.36 and 2.95 compared to RLlib and XingTian. TianJi is accessible at https://github.com/HiPRL/TianJi.git.
Fixed-size Objects Encoding for Visual Relationship Detection
May 29, 2020


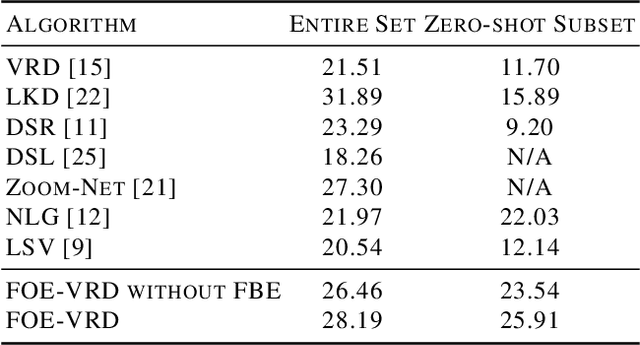
In this paper, we propose a fixed-size object encoding method (FOE-VRD) to improve performance of visual relationship detection tasks. Comparing with previous methods, FOE-VRD has an important feature, i.e., it uses one fixed-size vector to encoding all objects in each input image to assist the process of relationship detection. Firstly, we use a regular convolution neural network as a feature extractor to generate high-level features of input images. Then, for each relationship triplet in input images, i.e., $<$subject-predicate-object$>$, we apply ROI-pooling to get feature vectors of two regions on the feature maps that corresponding to bounding boxes of the subject and object. Besides the subject and object, our analysis implies that the results of predicate classification may also related to the rest objects in input images (we call them background objects). Due to the variable number of background objects in different images and computational costs, we cannot generate feature vectors for them one-by-one by using ROI pooling technique. Instead, we propose a novel method to encode all background objects in each image by using one fixed-size vector (i.e., FBE vector). By concatenating the 3 vectors we generate above, we successfully encode the objects using one fixed-size vector. The generated feature vector is then feed into a fully connected neural network to get predicate classification results. Experimental results on VRD database (entire set and zero-shot tests) show that the proposed method works well on both predicate classification and relationship detection.
Visual Confusion Label Tree For Image Classification
Jun 05, 2019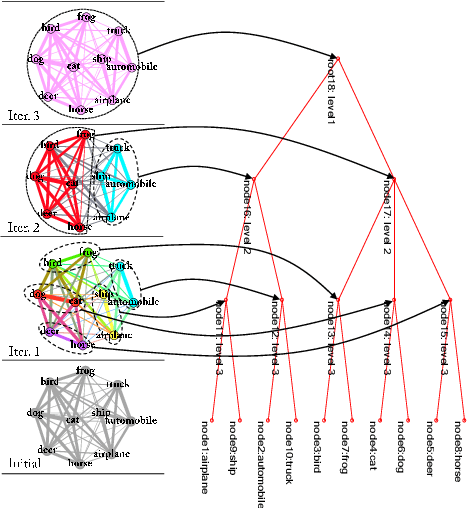
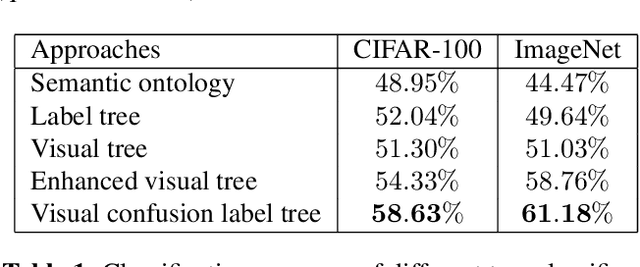

Convolution neural network models are widely used in image classification tasks. However, the running time of such models is so long that it is not the conforming to the strict real-time requirement of mobile devices. In order to optimize models and meet the requirement mentioned above, we propose a method that replaces the fully-connected layers of convolution neural network models with a tree classifier. Specifically, we construct a Visual Confusion Label Tree based on the output of the convolution neural network models, and use a multi-kernel SVM plus classifier with hierarchical constraints to train the tree classifier. Focusing on those confusion subsets instead of the entire set of categories makes the tree classifier more discriminative and the replacement of the fully-connected layers reduces the original running time. Experiments show that our tree classifier obtains a significant improvement over the state-of-the-art tree classifier by 4.3% and 2.4% in terms of top-1 accuracy on CIFAR-100 and ImageNet datasets respectively. Additionally, our method achieves 124x and 115x speedup ratio compared with fully-connected layers on AlexNet and VGG16 without accuracy decline.
* 9 pages, 5 figures, conference