 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Collaborative Perception from the Spatial-Temporal Importance of Semantic Information
Jul 31, 2023



Collaboration by the sharing of semantic information is crucial to enable the enhancement of perception capabilities. However, existing collaborative perception methods tend to focus solely on the spatial features of semantic information, while neglecting the importance of the temporal dimension in collaborator selection and semantic information fusion, which instigates performance degradation. In this article, we propose a novel collaborative perception framework, IoSI-CP, which takes into account the importance of semantic information (IoSI) from both temporal and spatial dimensions. Specifically, we develop an IoSI-based collaborator selection method that effectively identifies advantageous collaborators but excludes those that bring negative benefits. Moreover, we present a semantic information fusion algorithm called HPHA (historical prior hybrid attention), which integrates a multi-scale transformer module and a short-term attention module to capture IoSI from spatial and temporal dimensions, and assigns varying weights for efficient aggregation. Extensive experiments on two open datasets demonstrate that our proposed IoSI-CP significantly improves the perception performance compared to state-of-the-art approaches. The code associated with this research is publicly available at https://github.com/huangqzj/IoSI-CP/.
DynaMarks: Defending Against Deep Learning Model Extraction Using Dynamic Watermarking
Jul 27, 2022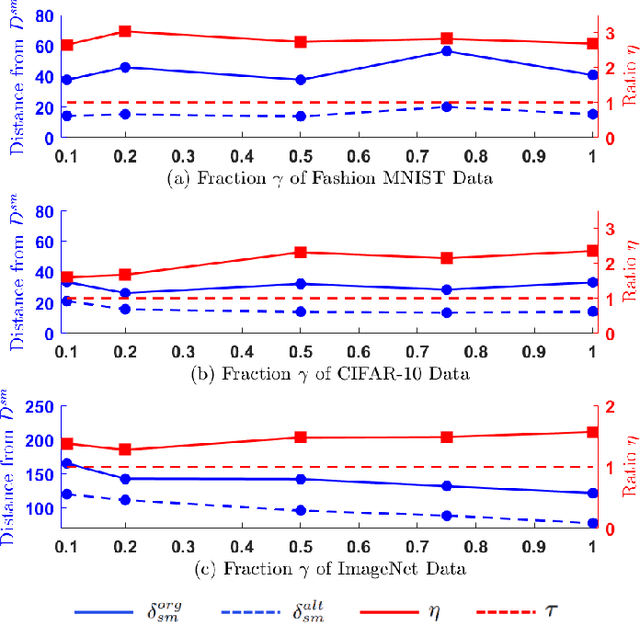
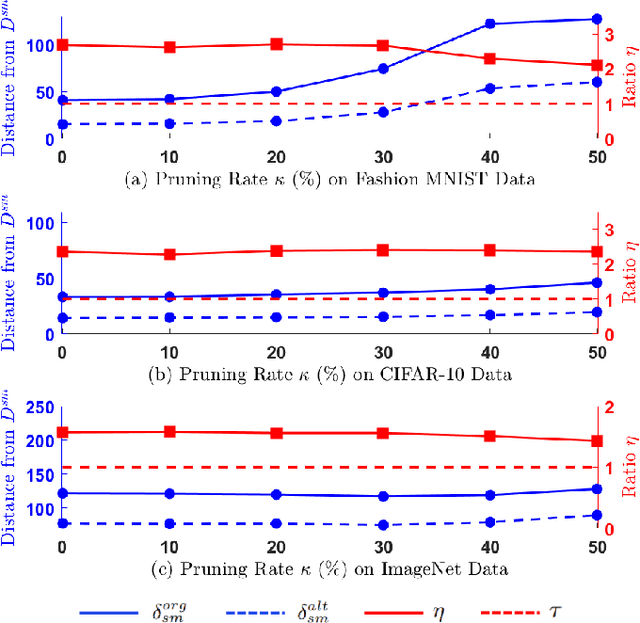

The functionality of a deep learning (DL) model can be stolen via model extraction where an attacker obtains a surrogate model by utilizing the responses from a prediction API of the original model. In this work, we propose a novel watermarking technique called DynaMarks to protect the intellectual property (IP) of DL models against such model extraction attacks in a black-box setting. Unlike existing approaches, DynaMarks does not alter the training process of the original model but rather embeds watermark into a surrogate model by dynamically changing the output responses from the original model prediction API based on certain secret parameters at inference runtime. The experimental outcomes on Fashion MNIST, CIFAR-10, and ImageNet datasets demonstrate the efficacy of DynaMarks scheme to watermark surrogate models while preserving the accuracies of the original models deployed in edge devices. In addition, we also perform experiments to evaluate the robustness of DynaMarks against various watermark removal strategies, thus allowing a DL model owner to reliably prove model ownership.
Visual Confusion Label Tree For Image Classification
Jun 05, 2019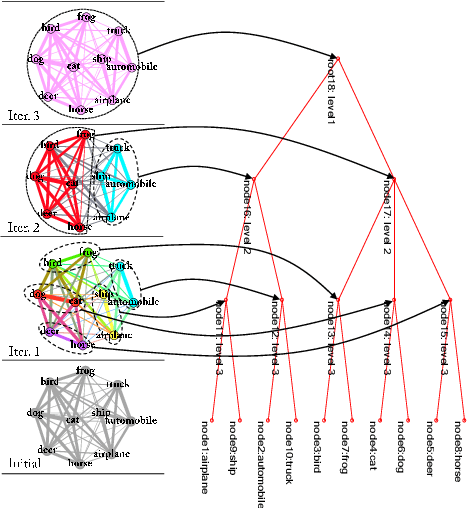
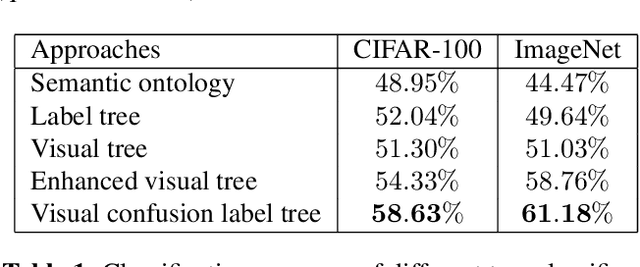
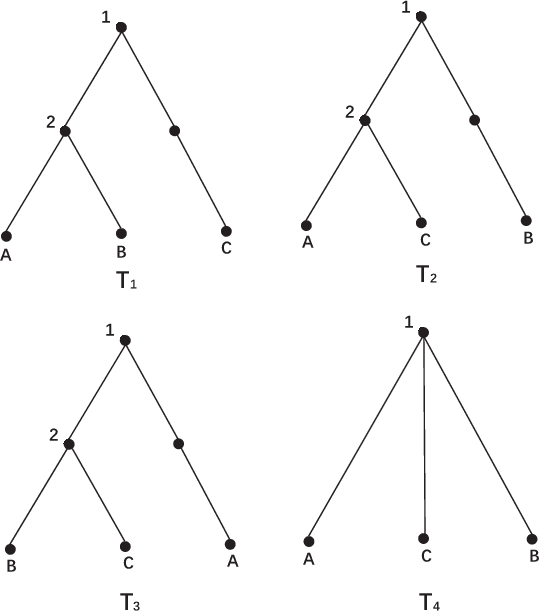

Convolution neural network models are widely used in image classification tasks. However, the running time of such models is so long that it is not the conforming to the strict real-time requirement of mobile devices. In order to optimize models and meet the requirement mentioned above, we propose a method that replaces the fully-connected layers of convolution neural network models with a tree classifier. Specifically, we construct a Visual Confusion Label Tree based on the output of the convolution neural network models, and use a multi-kernel SVM plus classifier with hierarchical constraints to train the tree classifier. Focusing on those confusion subsets instead of the entire set of categories makes the tree classifier more discriminative and the replacement of the fully-connected layers reduces the original running time. Experiments show that our tree classifier obtains a significant improvement over the state-of-the-art tree classifier by 4.3% and 2.4% in terms of top-1 accuracy on CIFAR-100 and ImageNet datasets respectively. Additionally, our method achieves 124x and 115x speedup ratio compared with fully-connected layers on AlexNet and VGG16 without accuracy decline.
* 9 pages, 5 figures, conference
Visual Tree Convolutional Neural Network in Image Classification
Jun 04, 2019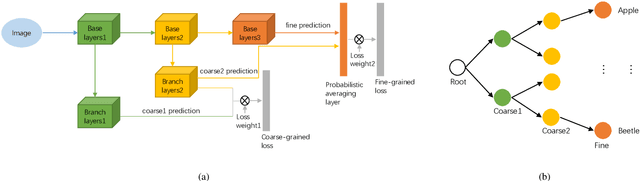
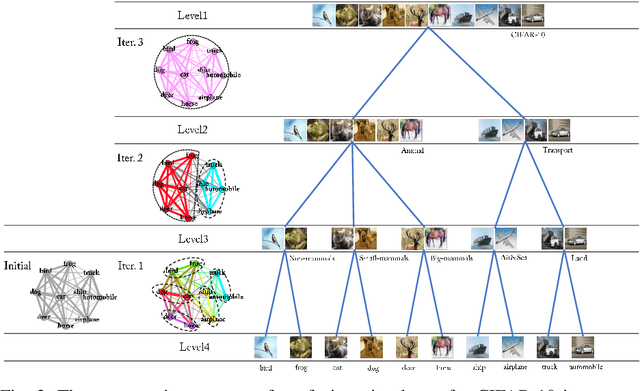
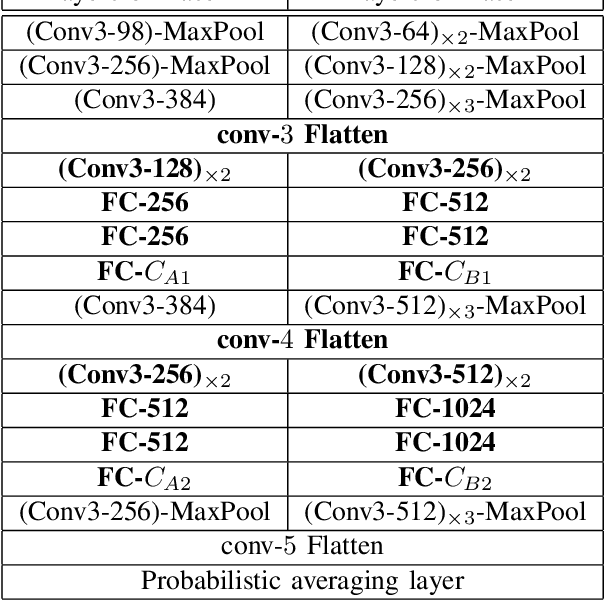
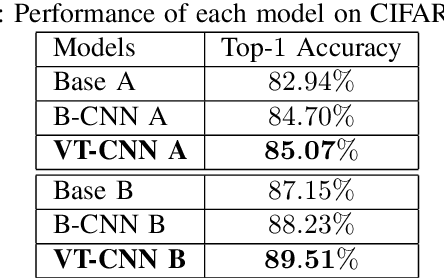
In image classification, Convolutional Neural Network(CNN) models have achieved high performance with the rapid development in deep learning. However, some categories in the image datasets are more difficult to distinguished than others. Improving the classification accuracy on these confused categories is benefit to the overall performance. In this paper, we build a Confusion Visual Tree(CVT) based on the confused semantic level information to identify the confused categories. With the information provided by the CVT, we can lead the CNN training procedure to pay more attention on these confused categories. Therefore, we propose Visual Tree Convolutional Neural Networks(VT-CNN) based on the original deep CNN embedded with our CVT. We evaluate our VT-CNN model on the benchmark datasets CIFAR-10 and CIFAR-100. In our experiments, we build up 3 different VT-CNN models and they obtain improvement over their based CNN models by 1.36%, 0.89% and 0.64%, respectively.
* 7 pages, 2 figures, conference