 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025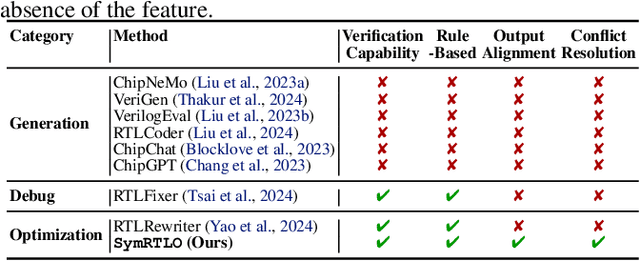
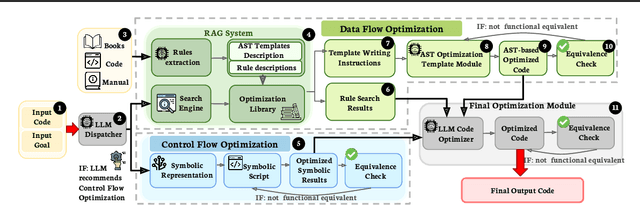

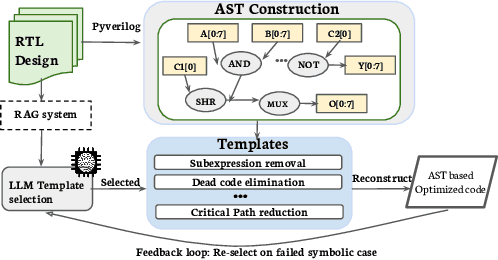
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
DynaMarks: Defending Against Deep Learning Model Extraction Using Dynamic Watermarking
Jul 27, 2022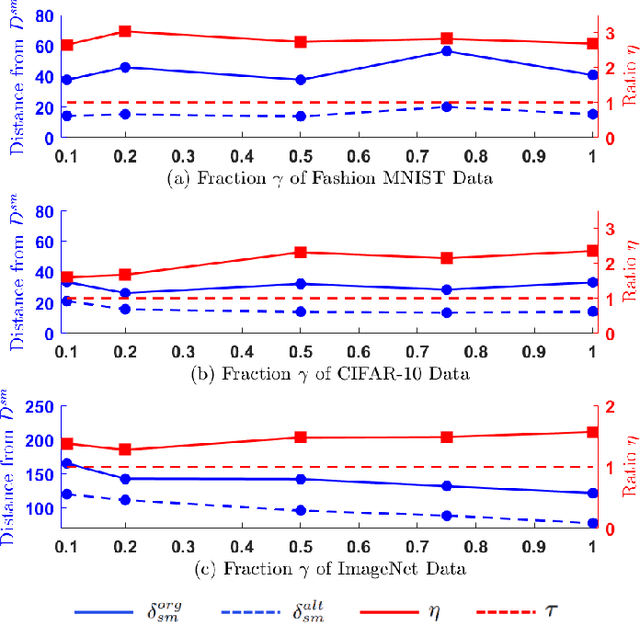
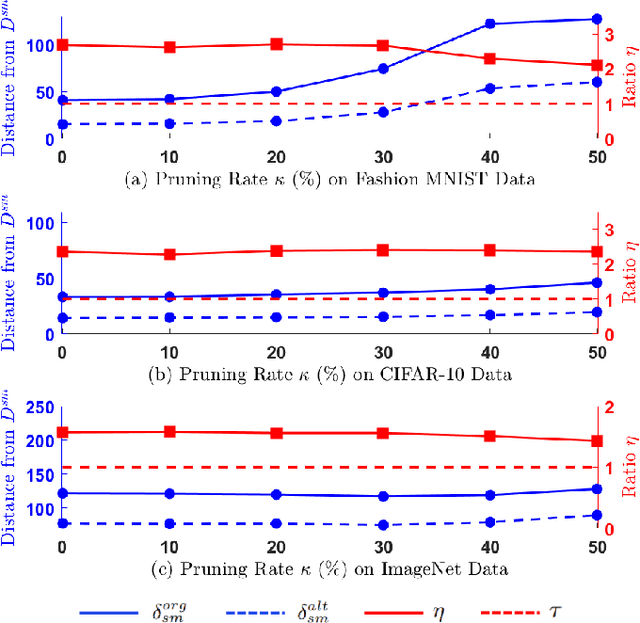

The functionality of a deep learning (DL) model can be stolen via model extraction where an attacker obtains a surrogate model by utilizing the responses from a prediction API of the original model. In this work, we propose a novel watermarking technique called DynaMarks to protect the intellectual property (IP) of DL models against such model extraction attacks in a black-box setting. Unlike existing approaches, DynaMarks does not alter the training process of the original model but rather embeds watermark into a surrogate model by dynamically changing the output responses from the original model prediction API based on certain secret parameters at inference runtime. The experimental outcomes on Fashion MNIST, CIFAR-10, and ImageNet datasets demonstrate the efficacy of DynaMarks scheme to watermark surrogate models while preserving the accuracies of the original models deployed in edge devices. In addition, we also perform experiments to evaluate the robustness of DynaMarks against various watermark removal strategies, thus allowing a DL model owner to reliably prove model ownership.
In-situ Stochastic Training of MTJ Crossbar based Neural Networks
Jun 24, 2018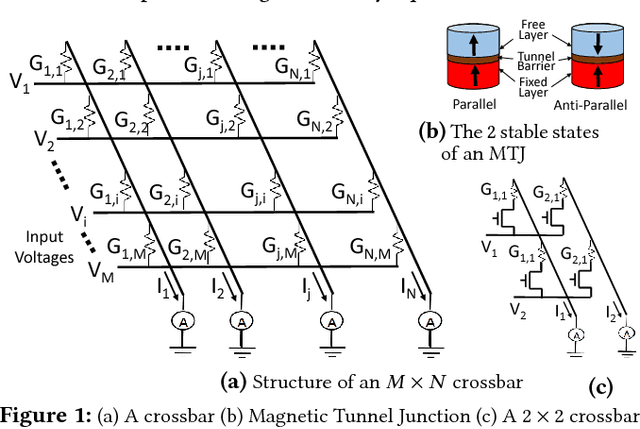
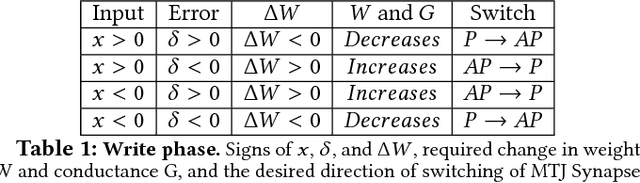
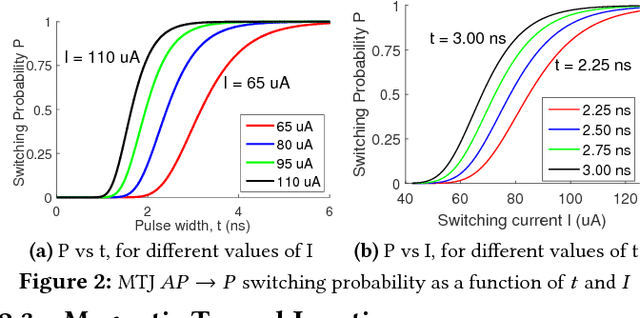
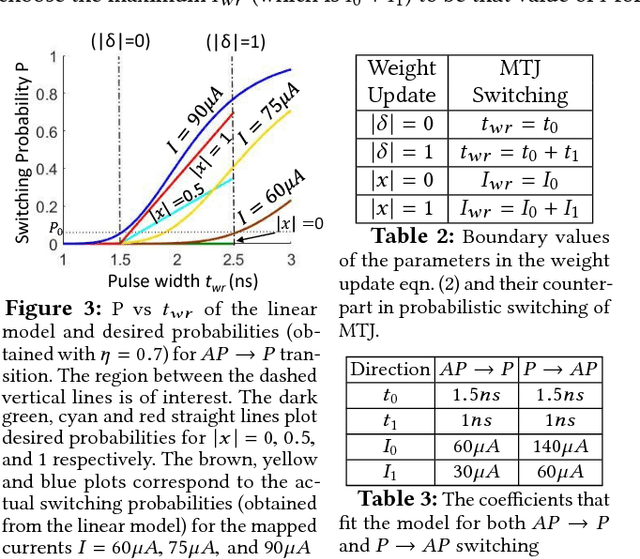
Owing to high device density, scalability and non-volatility, Magnetic Tunnel Junction-based crossbars have garnered significant interest for implementing the weights of an artificial neural network. The existence of only two stable states in MTJs implies a high overhead of obtaining optimal binary weights in software. We illustrate that the inherent parallelism in the crossbar structure makes it highly appropriate for in-situ training, wherein the network is taught directly on the hardware. It leads to significantly smaller training overhead as the training time is independent of the size of the network, while also circumventing the effects of alternate current paths in the crossbar and accounting for manufacturing variations in the device. We show how the stochastic switching characteristics of MTJs can be leveraged to perform probabilistic weight updates using the gradient descent algorithm. We describe how the update operations can be performed on crossbars both with and without access transistors and perform simulations on them to demonstrate the effectiveness of our techniques. The results reveal that stochastically trained MTJ-crossbar NNs achieve a classification accuracy nearly same as that of real-valued-weight networks trained in software and exhibit immunity to device variations.
Power Optimizations in MTJ-based Neural Networks through Stochastic Computing
Aug 17, 2017



Artificial Neural Networks (ANNs) have found widespread applications in tasks such as pattern recognition and image classification. However, hardware implementations of ANNs using conventional binary arithmetic units are computationally expensive, energy-intensive and have large area overheads. Stochastic Computing (SC) is an emerging paradigm which replaces these conventional units with simple logic circuits and is particularly suitable for fault-tolerant applications. Spintronic devices, such as Magnetic Tunnel Junctions (MTJs), are capable of replacing CMOS in memory and logic circuits. In this work, we propose an energy-efficient use of MTJs, which exhibit probabilistic switching behavior, as Stochastic Number Generators (SNGs), which forms the basis of our NN implementation in the SC domain. Further, error resilient target applications of NNs allow us to introduce Approximate Computing, a framework wherein accuracy of computations is traded-off for substantial reductions in power consumption. We propose approximating the synaptic weights in our MTJ-based NN implementation, in ways brought about by properties of our MTJ-SNG, to achieve energy-efficiency. We design an algorithm that can perform such approximations within a given error tolerance in a single-layer NN in an optimal way owing to the convexity of the problem formulation. We then use this algorithm and develop a heuristic approach for approximating multi-layer NNs. To give a perspective of the effectiveness of our approach, a 43% reduction in power consumption was obtained with less than 1% accuracy loss on a standard classification problem, with 26% being brought about by the proposed algorithm.