 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying When Pruning Works via Representation Hierarchies
Mar 25, 2026Network pruning, which removes less important parameters or architectures, is often expected to improve efficiency while preserving performance. However, this expectation does not consistently hold across language tasks: pruned models can perform well on non-generative tasks but frequently fail in generative settings. To understand this discrepancy, we analyze network pruning from a representation-hierarchy perspective, decomposing the internal computation of language models into three sequential spaces: embedding (hidden representations), logit (pre-softmax outputs), and probability (post-softmax distributions). We find that representations in the embedding and logit spaces are largely robust to pruning-induced perturbations. However, the nonlinear transformation from logits to probabilities amplifies these deviations, which accumulate across time steps and lead to substantial degradation during generation. In contrast, the stability of the categorical-token probability subspace, together with the robustness of the embedding space, supports the effectiveness of pruning for non-generative tasks such as retrieval and multiple-choice selection. Our analysis disentangles the effects of pruning across tasks and provides practical guidance for its application. Code is available at https://github.com/CASE-Lab-UMD/Pruning-on-Representations
FedMOA: Federated GRPO for Personalized Reasoning LLMs under Heterogeneous Rewards
Jan 31, 2026Group Relative Policy Optimization (GRPO) has recently emerged as an effective approach for improving the reasoning capabilities of large language models through online multi-objective reinforcement learning. While personalization on private data is increasingly vital, traditional Reinforcement Learning (RL) alignment is often memory-prohibitive for on-device federated learning due to the overhead of maintaining a separate critic network. GRPO's critic-free architecture enables feasible on-device training, yet transitioning to a federated setting introduces systemic challenges: heterogeneous reward definitions, imbalanced multi-objective optimization, and high training costs. We propose FedMOA, a federated GRPO framework for multi-objective alignment under heterogeneous rewards. FedMOA stabilizes local training through an online adaptive weighting mechanism via hypergradient descent, which prioritizes primary reasoning as auxiliary objectives saturate. On the server side, it utilizes a task- and accuracy-aware aggregation strategy to prioritize high-quality updates. Experiments on mathematical reasoning and code generation benchmarks demonstrate that FedMOA consistently outperforms federated averaging, achieving accuracy gains of up to 2.2% while improving global performance, personalization, and multi-objective balance.
Towards Building Non-Fine-Tunable Foundation Models
Jan 31, 2026Open-sourcing foundation models (FMs) enables broad reuse but also exposes model trainers to economic and safety risks from unrestricted downstream fine-tuning. We address this problem by building non-fine-tunable foundation models: models that remain broadly usable in their released form while yielding limited adaptation gains under task-agnostic unauthorized fine-tuning. We propose Private Mask Pre-Training (PMP), a pre-training framework that concentrates representation learning into a sparse subnetwork identified early in training. The binary mask defining this subnetwork is kept private, and only the final dense weights are released. This forces unauthorized fine-tuning without access to the mask to update parameters misaligned with pretraining subspace, inducing an intrinsic mismatch between the fine-tuning objective and the pre-training geometry. We provide theoretical analysis showing that this mismatch destabilizes gradient-based adaptation and bounds fine-tuning gains. Empirical results on large language models demonstrating that PMP preserves base model performance while consistently degrading unauthorized fine-tuning across a wide range of downstream tasks, with the strength of non-fine-tunability controlled by the mask ratio.
EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices
Jul 02, 2025Large Language Models (LLMs) have gained significant attention due to their versatility across a wide array of applications. Fine-tuning LLMs with parameter-efficient adapters, such as Low-Rank Adaptation (LoRA), enables these models to efficiently adapt to downstream tasks without extensive retraining. Deploying fine-tuned LLMs on multi-tenant edge devices offers substantial benefits, such as reduced latency, enhanced privacy, and personalized responses. However, serving LLMs efficiently on resource-constrained edge devices presents critical challenges, including the complexity of adapter selection for different tasks and memory overhead from frequent adapter swapping. Moreover, given the multiple requests in multi-tenant settings, processing requests sequentially results in underutilization of computational resources and increased latency. This paper introduces EdgeLoRA, an efficient system for serving LLMs on edge devices in multi-tenant environments. EdgeLoRA incorporates three key innovations: (1) an adaptive adapter selection mechanism to streamline the adapter configuration process; (2) heterogeneous memory management, leveraging intelligent adapter caching and pooling to mitigate memory operation overhead; and (3) batch LoRA inference, enabling efficient batch processing to significantly reduce computational latency. Comprehensive evaluations using the Llama3.1-8B model demonstrate that EdgeLoRA significantly outperforms the status quo (i.e., llama.cpp) in terms of both latency and throughput. The results demonstrate that EdgeLoRA can achieve up to a 4 times boost in throughput. Even more impressively, it can serve several orders of magnitude more adapters simultaneously. These results highlight EdgeLoRA's potential to transform edge deployment of LLMs in multi-tenant scenarios, offering a scalable and efficient solution for resource-constrained environments.
Invisible Tokens, Visible Bills: The Urgent Need to Audit Hidden Operations in Opaque LLM Services
May 24, 2025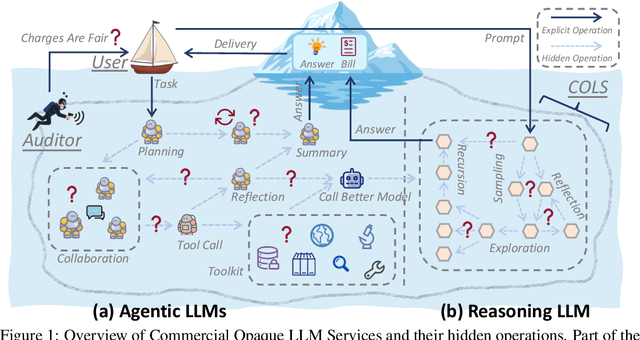
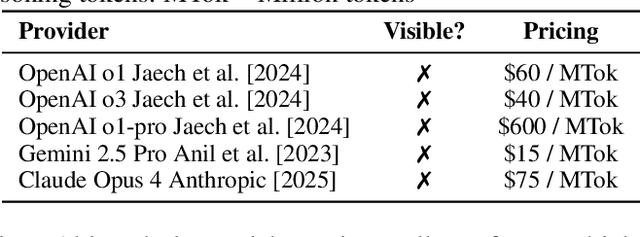
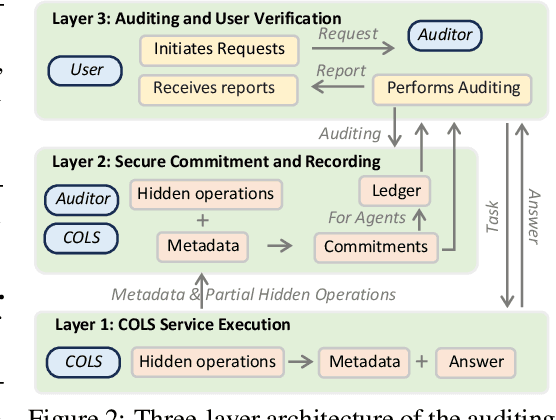

Modern large language model (LLM) services increasingly rely on complex, often abstract operations, such as multi-step reasoning and multi-agent collaboration, to generate high-quality outputs. While users are billed based on token consumption and API usage, these internal steps are typically not visible. We refer to such systems as Commercial Opaque LLM Services (COLS). This position paper highlights emerging accountability challenges in COLS: users are billed for operations they cannot observe, verify, or contest. We formalize two key risks: \textit{quantity inflation}, where token and call counts may be artificially inflated, and \textit{quality downgrade}, where providers might quietly substitute lower-cost models or tools. Addressing these risks requires a diverse set of auditing strategies, including commitment-based, predictive, behavioral, and signature-based methods. We further explore the potential of complementary mechanisms such as watermarking and trusted execution environments to enhance verifiability without compromising provider confidentiality. We also propose a modular three-layer auditing framework for COLS and users that enables trustworthy verification across execution, secure logging, and user-facing auditability without exposing proprietary internals. Our aim is to encourage further research and policy development toward transparency, auditability, and accountability in commercial LLM services.
CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
May 19, 2025As post-training techniques evolve, large language models (LLMs) are increasingly augmented with structured multi-step reasoning abilities, often optimized through reinforcement learning. These reasoning-enhanced models outperform standard LLMs on complex tasks and now underpin many commercial LLM APIs. However, to protect proprietary behavior and reduce verbosity, providers typically conceal the reasoning traces while returning only the final answer. This opacity introduces a critical transparency gap: users are billed for invisible reasoning tokens, which often account for the majority of the cost, yet have no means to verify their authenticity. This opens the door to token count inflation, where providers may overreport token usage or inject synthetic, low-effort tokens to inflate charges. To address this issue, we propose CoIn, a verification framework that audits both the quantity and semantic validity of hidden tokens. CoIn constructs a verifiable hash tree from token embedding fingerprints to check token counts, and uses embedding-based relevance matching to detect fabricated reasoning content. Experiments demonstrate that CoIn, when deployed as a trusted third-party auditor, can effectively detect token count inflation with a success rate reaching up to 94.7%, showing the strong ability to restore billing transparency in opaque LLM services. The dataset and code are available at https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn.
VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation
May 17, 2025Automating Register Transfer Level (RTL) code generation using Large Language Models (LLMs) offers substantial promise for streamlining digital circuit design and reducing human effort. However, current LLM-based approaches face significant challenges with training data scarcity, poor specification-code alignment, lack of verification mechanisms, and balancing generalization with specialization. Inspired by DeepSeek-R1, we introduce VeriReason, a framework integrating supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning for RTL generation. Using curated training examples and a feedback-driven reward model, VeriReason combines testbench evaluations with structural heuristics while embedding self-checking capabilities for autonomous error correction. On the VerilogEval Benchmark, VeriReason delivers significant improvements: achieving 83.1% functional correctness on the VerilogEval Machine benchmark, substantially outperforming both comparable-sized models and much larger commercial systems like GPT-4 Turbo. Additionally, our approach demonstrates up to a 2.8X increase in first-attempt functional correctness compared to baseline methods and exhibits robust generalization to unseen designs. To our knowledge, VeriReason represents the first system to successfully integrate explicit reasoning capabilities with reinforcement learning for Verilog generation, establishing a new state-of-the-art for automated RTL synthesis. The models and datasets are available at: https://huggingface.co/collections/AI4EDA-CASE Code is Available at: https://github.com/NellyW8/VeriReason
NetSight: Graph Attention Based Traffic Forecasting in Computer Networks
May 11, 2025The traffic in today's networks is increasingly influenced by the interactions among network nodes as well as by the temporal fluctuations in the demands of the nodes. Traditional statistical prediction methods are becoming obsolete due to their inability to address the non-linear and dynamic spatio-temporal dependencies present in today's network traffic. The most promising direction of research today is graph neural networks (GNNs) based prediction approaches that are naturally suited to handle graph-structured data. Unfortunately, the state-of-the-art GNN approaches separate the modeling of spatial and temporal information, resulting in the loss of important information about joint dependencies. These GNN based approaches further do not model information at both local and global scales simultaneously, leaving significant room for improvement. To address these challenges, we propose NetSight. NetSight learns joint spatio-temporal dependencies simultaneously at both global and local scales from the time-series of measurements of any given network metric collected at various nodes in a network. Using the learned information, NetSight can then accurately predict the future values of the given network metric at those nodes in the network. We propose several new concepts and techniques in the design of NetSight, such as spatio-temporal adjacency matrix and node normalization. Through extensive evaluations and comparison with prior approaches using data from two large real-world networks, we show that NetSight significantly outperforms all prior state-of-the-art approaches. We will release the source code and data used in the evaluation of NetSight on the acceptance of this paper.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025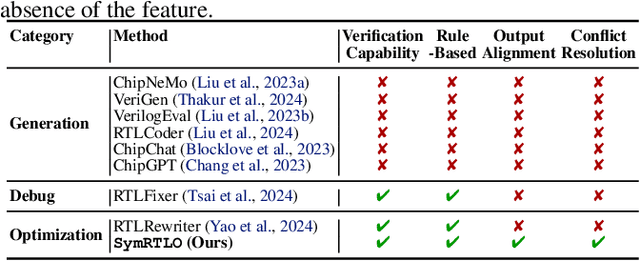
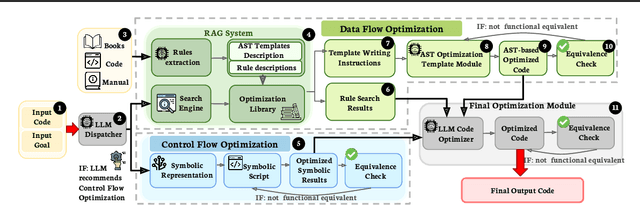

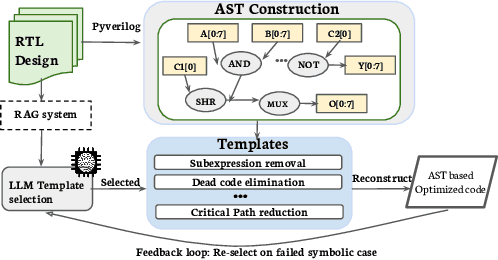
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
Prada: Black-Box LLM Adaptation with Private Data on Resource-Constrained Devices
Mar 19, 2025In recent years, Large Language Models (LLMs) have demonstrated remarkable abilities in various natural language processing tasks. However, adapting these models to specialized domains using private datasets stored on resource-constrained edge devices, such as smartphones and personal computers, remains challenging due to significant privacy concerns and limited computational resources. Existing model adaptation methods either compromise data privacy by requiring data transmission or jeopardize model privacy by exposing proprietary LLM parameters. To address these challenges, we propose Prada, a novel privacy-preserving and efficient black-box LLM adaptation system using private on-device datasets. Prada employs a lightweight proxy model fine-tuned with Low-Rank Adaptation (LoRA) locally on user devices. During inference, Prada leverages the logits offset, i.e., difference in outputs between the base and adapted proxy models, to iteratively refine outputs from a remote black-box LLM. This offset-based adaptation approach preserves both data privacy and model privacy, as there is no need to share sensitive data or proprietary model parameters. Furthermore, we incorporate speculative decoding to further speed up the inference process of Prada, making the system practically deployable on bandwidth-constrained edge devices, enabling a more practical deployment of Prada. Extensive experiments on various downstream tasks demonstrate that Prada achieves performance comparable to centralized fine-tuning methods while significantly reducing computational overhead by up to 60% and communication costs by up to 80%.