 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethConvTransformer: A Deep Learning Framework for Cross-Tissue Alzheimer's Disease Detection
Jan 01, 2026Alzheimer's disease (AD) is a multifactorial neurodegenerative disorder characterized by progressive cognitive decline and widespread epigenetic dysregulation in the brain. DNA methylation, as a stable yet dynamic epigenetic modification, holds promise as a noninvasive biomarker for early AD detection. However, methylation signatures vary substantially across tissues and studies, limiting reproducibility and translational utility. To address these challenges, we develop MethConvTransformer, a transformer-based deep learning framework that integrates DNA methylation profiles from both brain and peripheral tissues to enable biomarker discovery. The model couples a CpG-wise linear projection with convolutional and self-attention layers to capture local and long-range dependencies among CpG sites, while incorporating subject-level covariates and tissue embeddings to disentangle shared and region-specific methylation effects. In experiments across six GEO datasets and an independent ADNI validation cohort, our model consistently outperforms conventional machine-learning baselines, achieving superior discrimination and generalization. Moreover, interpretability analyses using linear projection, SHAP, and Grad-CAM++ reveal biologically meaningful methylation patterns aligned with AD-associated pathways, including immune receptor signaling, glycosylation, lipid metabolism, and endomembrane (ER/Golgi) organization. Together, these results indicate that MethConvTransformer delivers robust, cross-tissue epigenetic biomarkers for AD while providing multi-resolution interpretability, thereby advancing reproducible methylation-based diagnostics and offering testable hypotheses on disease mechanisms.
Proximal Algorithm Unrolling: Flexible and Efficient Reconstruction Networks for Single-Pixel Imaging
May 29, 2025Deep-unrolling and plug-and-play (PnP) approaches have become the de-facto standard solvers for single-pixel imaging (SPI) inverse problem. PnP approaches, a class of iterative algorithms where regularization is implicitly performed by an off-the-shelf deep denoiser, are flexible for varying compression ratios (CRs) but are limited in reconstruction accuracy and speed. Conversely, unrolling approaches, a class of multi-stage neural networks where a truncated iterative optimization process is transformed into an end-to-end trainable network, typically achieve better accuracy with faster inference but require fine-tuning or even retraining when CR changes. In this paper, we address the challenge of integrating the strengths of both classes of solvers. To this end, we design an efficient deep image restorer (DIR) for the unrolling of HQS (half quadratic splitting) and ADMM (alternating direction method of multipliers). More importantly, a general proximal trajectory (PT) loss function is proposed to train HQS/ADMM-unrolling networks such that learned DIR approximates the proximal operator of an ideal explicit restoration regularizer. Extensive experiments demonstrate that, the resulting proximal unrolling networks can not only flexibly handle varying CRs with a single model like PnP algorithms, but also outperform previous CR-specific unrolling networks in both reconstruction accuracy and speed. Source codes and models are available at https://github.com/pwangcs/ProxUnroll.
VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation
May 17, 2025Automating Register Transfer Level (RTL) code generation using Large Language Models (LLMs) offers substantial promise for streamlining digital circuit design and reducing human effort. However, current LLM-based approaches face significant challenges with training data scarcity, poor specification-code alignment, lack of verification mechanisms, and balancing generalization with specialization. Inspired by DeepSeek-R1, we introduce VeriReason, a framework integrating supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning for RTL generation. Using curated training examples and a feedback-driven reward model, VeriReason combines testbench evaluations with structural heuristics while embedding self-checking capabilities for autonomous error correction. On the VerilogEval Benchmark, VeriReason delivers significant improvements: achieving 83.1% functional correctness on the VerilogEval Machine benchmark, substantially outperforming both comparable-sized models and much larger commercial systems like GPT-4 Turbo. Additionally, our approach demonstrates up to a 2.8X increase in first-attempt functional correctness compared to baseline methods and exhibits robust generalization to unseen designs. To our knowledge, VeriReason represents the first system to successfully integrate explicit reasoning capabilities with reinforcement learning for Verilog generation, establishing a new state-of-the-art for automated RTL synthesis. The models and datasets are available at: https://huggingface.co/collections/AI4EDA-CASE Code is Available at: https://github.com/NellyW8/VeriReason
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025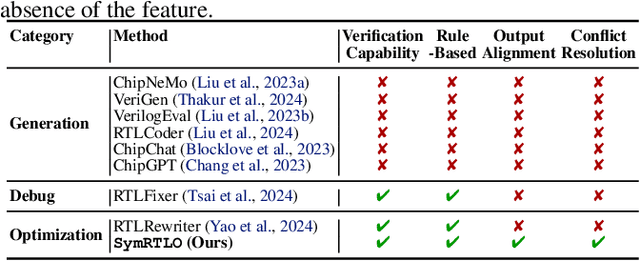
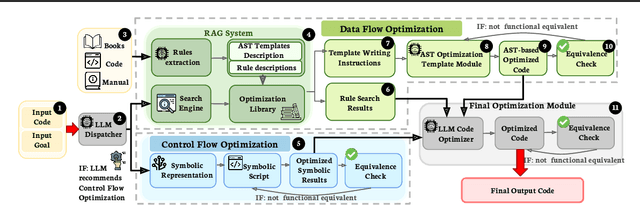

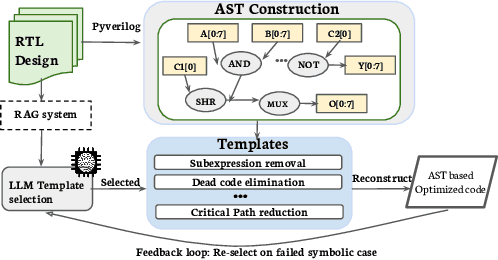
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
A Deep Spatio-Temporal Architecture for Dynamic Effective Connectivity Network Analysis Based on Dynamic Causal Discovery
Jan 31, 2025



Dynamic effective connectivity networks (dECNs) reveal the changing directed brain activity and the dynamic causal influences among brain regions, which facilitate the identification of individual differences and enhance the understanding of human brain. Although the existing causal discovery methods have shown promising results in effective connectivity network analysis, they often overlook the dynamics of causality, in addition to the incorporation of spatio-temporal information in brain activity data. To address these issues, we propose a deep spatio-temporal fusion architecture, which employs a dynamic causal deep encoder to incorporate spatio-temporal information into dynamic causality modeling, and a dynamic causal deep decoder to verify the discovered causality. The effectiveness of the proposed method is first illustrated with simulated data. Then, experimental results from Philadelphia Neurodevelopmental Cohort (PNC) demonstrate the superiority of the proposed method in inferring dECNs, which reveal the dynamic evolution of directed flow between brain regions. The analysis shows the difference of dECNs between young adults and children. Specifically, the directed brain functional networks transit from fluctuating undifferentiated systems to more stable specialized networks as one grows. This observation provides further evidence on the modularization and adaptation of brain networks during development, leading to higher cognitive abilities observed in young adults.
Integrated Brain Connectivity Analysis with fMRI, DTI, and sMRI Powered by Interpretable Graph Neural Networks
Aug 26, 2024Multimodal neuroimaging modeling has becomes a widely used approach but confronts considerable challenges due to heterogeneity, which encompasses variability in data types, scales, and formats across modalities. This variability necessitates the deployment of advanced computational methods to integrate and interpret these diverse datasets within a cohesive analytical framework. In our research, we amalgamate functional magnetic resonance imaging, diffusion tensor imaging, and structural MRI into a cohesive framework. This integration capitalizes on the unique strengths of each modality and their inherent interconnections, aiming for a comprehensive understanding of the brain's connectivity and anatomical characteristics. Utilizing the Glasser atlas for parcellation, we integrate imaging derived features from various modalities: functional connectivity from fMRI, structural connectivity from DTI, and anatomical features from sMRI within consistent regions. Our approach incorporates a masking strategy to differentially weight neural connections, thereby facilitating a holistic amalgamation of multimodal imaging data. This technique enhances interpretability at connectivity level, transcending traditional analyses centered on singular regional attributes. The model is applied to the Human Connectome Project's Development study to elucidate the associations between multimodal imaging and cognitive functions throughout youth. The analysis demonstrates improved predictive accuracy and uncovers crucial anatomical features and essential neural connections, deepening our understanding of brain structure and function.
A Demographic-Conditioned Variational Autoencoder for fMRI Distribution Sampling and Removal of Confounds
May 13, 2024



Objective: fMRI and derived measures such as functional connectivity (FC) have been used to predict brain age, general fluid intelligence, psychiatric disease status, and preclinical neurodegenerative disease. However, it is not always clear that all demographic confounds, such as age, sex, and race, have been removed from fMRI data. Additionally, many fMRI datasets are restricted to authorized researchers, making dissemination of these valuable data sources challenging. Methods: We create a variational autoencoder (VAE)-based model, DemoVAE, to decorrelate fMRI features from demographics and generate high-quality synthetic fMRI data based on user-supplied demographics. We train and validate our model using two large, widely used datasets, the Philadelphia Neurodevelopmental Cohort (PNC) and Bipolar and Schizophrenia Network for Intermediate Phenotypes (BSNIP). Results: We find that DemoVAE recapitulates group differences in fMRI data while capturing the full breadth of individual variations. Significantly, we also find that most clinical and computerized battery fields that are correlated with fMRI data are not correlated with DemoVAE latents. An exception are several fields related to schizophrenia medication and symptom severity. Conclusion: Our model generates fMRI data that captures the full distribution of FC better than traditional VAE or GAN models. We also find that most prediction using fMRI data is dependent on correlation with, and prediction of, demographics. Significance: Our DemoVAE model allows for generation of high quality synthetic data conditioned on subject demographics as well as the removal of the confounding effects of demographics. We identify that FC-based prediction tasks are highly influenced by demographic confounds.
Dual-Scale Transformer for Large-Scale Single-Pixel Imaging
Apr 07, 2024Single-pixel imaging (SPI) is a potential computational imaging technique which produces image by solving an illposed reconstruction problem from few measurements captured by a single-pixel detector. Deep learning has achieved impressive success on SPI reconstruction. However, previous poor reconstruction performance and impractical imaging model limit its real-world applications. In this paper, we propose a deep unfolding network with hybrid-attention Transformer on Kronecker SPI model, dubbed HATNet, to improve the imaging quality of real SPI cameras. Specifically, we unfold the computation graph of the iterative shrinkagethresholding algorithm (ISTA) into two alternative modules: efficient tensor gradient descent and hybrid-attention multiscale denoising. By virtue of Kronecker SPI, the gradient descent module can avoid high computational overheads rooted in previous gradient descent modules based on vectorized SPI. The denoising module is an encoder-decoder architecture powered by dual-scale spatial attention for high- and low-frequency aggregation and channel attention for global information recalibration. Moreover, we build a SPI prototype to verify the effectiveness of the proposed method. Extensive experiments on synthetic and real data demonstrate that our method achieves the state-of-the-art performance. The source code and pre-trained models are available at https://github.com/Gang-Qu/HATNet-SPI.
An Interpretable Cross-Attentive Multi-modal MRI Fusion Framework for Schizophrenia Diagnosis
Mar 29, 2024



Both functional and structural magnetic resonance imaging (fMRI and sMRI) are widely used for the diagnosis of mental disorder. However, combining complementary information from these two modalities is challenging due to their heterogeneity. Many existing methods fall short of capturing the interaction between these modalities, frequently defaulting to a simple combination of latent features. In this paper, we propose a novel Cross-Attentive Multi-modal Fusion framework (CAMF), which aims to capture both intra-modal and inter-modal relationships between fMRI and sMRI, enhancing multi-modal data representation. Specifically, our CAMF framework employs self-attention modules to identify interactions within each modality while cross-attention modules identify interactions between modalities. Subsequently, our approach optimizes the integration of latent features from both modalities. This approach significantly improves classification accuracy, as demonstrated by our evaluations on two extensive multi-modal brain imaging datasets, where CAMF consistently outperforms existing methods. Furthermore, the gradient-guided Score-CAM is applied to interpret critical functional networks and brain regions involved in schizophrenia. The bio-markers identified by CAMF align with established research, potentially offering new insights into the diagnosis and pathological endophenotypes of schizophrenia.
LLM4SecHW: Leveraging Domain Specific Large Language Model for Hardware Debugging
Jan 28, 2024


This paper presents LLM4SecHW, a novel framework for hardware debugging that leverages domain specific Large Language Model (LLM). Despite the success of LLMs in automating various software development tasks, their application in the hardware security domain has been limited due to the constraints of commercial LLMs and the scarcity of domain specific data. To address these challenges, we propose a unique approach to compile a dataset of open source hardware design defects and their remediation steps, utilizing version control data. This dataset provides a substantial foundation for training machine learning models for hardware. LLM4SecHW employs fine tuning of medium sized LLMs based on this dataset, enabling the identification and rectification of bugs in hardware designs. This pioneering approach offers a reference workflow for the application of fine tuning domain specific LLMs in other research areas. We evaluate the performance of our proposed system on various open source hardware designs, demonstrating its efficacy in accurately identifying and correcting defects. Our work brings a new perspective on automating the quality control process in hardware design.
* 6 pages. 1 figure