 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenoBERT: A Language Model for Accurate Genotype Imputation
Mar 31, 2026Genotype imputation enables dense variant coverage for genome-wide association and risk-prediction studies, yet conventional reference-panel methods remain limited by ancestry bias and reduced rare-variant accuracy. We present Genotype Bidirectional Encoder Representations from Transformers (GenoBERT), a transformer-based, reference-free framework that tokenizes phased genotypes and uses a self-attention mechanism to capture both short- and long-range linkage disequilibrium (LD) dependencies. Benchmarking on two independent datasets including the Louisiana Osteoporosis Study (LOS) and the 1000 Genomes Project (1KGP) across ancestry groups and multiple genotype missingness levels (5-50%) shows that GenoBERT achieves the highest overall accuracy compared to four baseline methods (Beagle5.4, SCDA, BiU-Net, and STICI). At practical sparsity levels (up to 25% missing), GenoBERT attains high overall imputation accuracy ($r^2 approx 0.98$) across datasets, and maintains robust performance ($r^2 > 0.90$) even at 50% missingness. Experimental results across different ancestries confirm consistent gains across datasets, with resilience to small sample sizes and weak LD. A 128-SNP (single-nucleotide polymorphism) context window (approximately 100 Kb) is validated through LD-decay analyses as sufficient to capture local correlation structures. By eliminating reference-panel dependence while preserving high accuracy, GenoBERT provides a scalable and robust solution for genotype imputation and a foundation for downstream genomic modeling.
PF-DAformer: Proximal Femur Segmentation via Domain Adaptive Transformer for Dual-Center QCT
Oct 30, 2025Quantitative computed tomography (QCT) plays a crucial role in assessing bone strength and fracture risk by enabling volumetric analysis of bone density distribution in the proximal femur. However, deploying automated segmentation models in practice remains difficult because deep networks trained on one dataset often fail when applied to another. This failure stems from domain shift, where scanners, reconstruction settings, and patient demographics vary across institutions, leading to unstable predictions and unreliable quantitative metrics. Overcoming this barrier is essential for multi-center osteoporosis research and for ensuring that radiomics and structural finite element analysis results remain reproducible across sites. In this work, we developed a domain-adaptive transformer segmentation framework tailored for multi-institutional QCT. Our model is trained and validated on one of the largest hip fracture related research cohorts to date, comprising 1,024 QCT images scans from Tulane University and 384 scans from Rochester, Minnesota for proximal femur segmentation. To address domain shift, we integrate two complementary strategies within a 3D TransUNet backbone: adversarial alignment via Gradient Reversal Layer (GRL), which discourages the network from encoding site-specific cues, and statistical alignment via Maximum Mean Discrepancy (MMD), which explicitly reduces distributional mismatches between institutions. This dual mechanism balances invariance and fine-grained alignment, enabling scanner-agnostic feature learning while preserving anatomical detail.
ICGM-FRAX: Iterative Cross Graph Matching for Hip Fracture Risk Assessment using Dual-energy X-ray Absorptiometry Images
Apr 21, 2025Hip fractures represent a major health concern, particularly among the elderly, often leading decreased mobility and increased mortality. Early and accurate detection of at risk individuals is crucial for effective intervention. In this study, we propose Iterative Cross Graph Matching for Hip Fracture Risk Assessment (ICGM-FRAX), a novel approach for predicting hip fractures using Dual-energy X-ray Absorptiometry (DXA) images. ICGM-FRAX involves iteratively comparing a test (subject) graph with multiple template graphs representing the characteristics of hip fracture subjects to assess the similarity and accurately to predict hip fracture risk. These graphs are obtained as follows. The DXA images are separated into multiple regions of interest (RoIs), such as the femoral head, shaft, and lesser trochanter. Radiomic features are then calculated for each RoI, with the central coordinates used as nodes in a graph. The connectivity between nodes is established according to the Euclidean distance between these coordinates. This process transforms each DXA image into a graph, where each node represents a RoI, and edges derived by the centroids of RoIs capture the spatial relationships between them. If the test graph closely matches a set of template graphs representing subjects with incident hip fractures, it is classified as indicating high hip fracture risk. We evaluated our method using 547 subjects from the UK Biobank dataset, and experimental results show that ICGM-FRAX achieved a sensitivity of 0.9869, demonstrating high accuracy in predicting hip fractures.
SGUQ: Staged Graph Convolution Neural Network for Alzheimer's Disease Diagnosis using Multi-Omics Data
Oct 14, 2024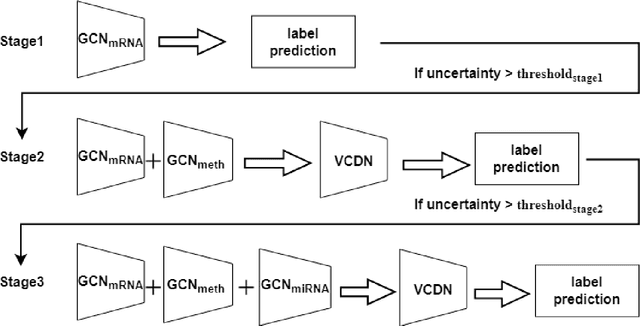

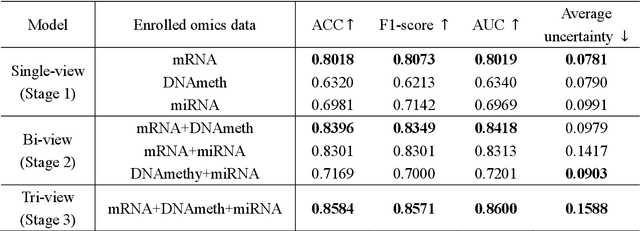
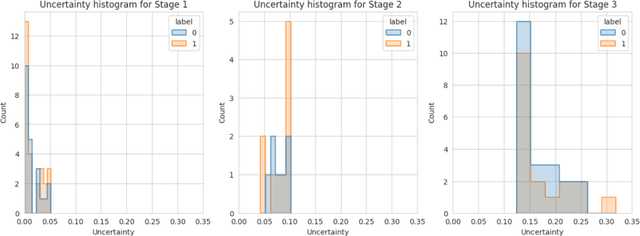
Alzheimer's disease (AD) is a chronic neurodegenerative disorder and the leading cause of dementia, significantly impacting cost, mortality, and burden worldwide. The advent of high-throughput omics technologies, such as genomics, transcriptomics, proteomics, and epigenomics, has revolutionized the molecular understanding of AD. Conventional AI approaches typically require the completion of all omics data at the outset to achieve optimal AD diagnosis, which are inefficient and may be unnecessary. To reduce the clinical cost and improve the accuracy of AD diagnosis using multi-omics data, we propose a novel staged graph convolutional network with uncertainty quantification (SGUQ). SGUQ begins with mRNA and progressively incorporates DNA methylation and miRNA data only when necessary, reducing overall costs and exposure to harmful tests. Experimental results indicate that 46.23% of the samples can be reliably predicted using only single-modal omics data (mRNA), while an additional 16.04% of the samples can achieve reliable predictions when combining two omics data types (mRNA + DNA methylation). In addition, the proposed staged SGUQ achieved an accuracy of 0.858 on ROSMAP dataset, which outperformed existing methods significantly. The proposed SGUQ can not only be applied to AD diagnosis using multi-omics data but also has the potential for clinical decision-making using multi-viewed data. Our implementation is publicly available at https://github.com/chenzhao2023/multiomicsuncertainty.
A Staged Approach using Machine Learning and Uncertainty Quantification to Predict the Risk of Hip Fracture
May 30, 2024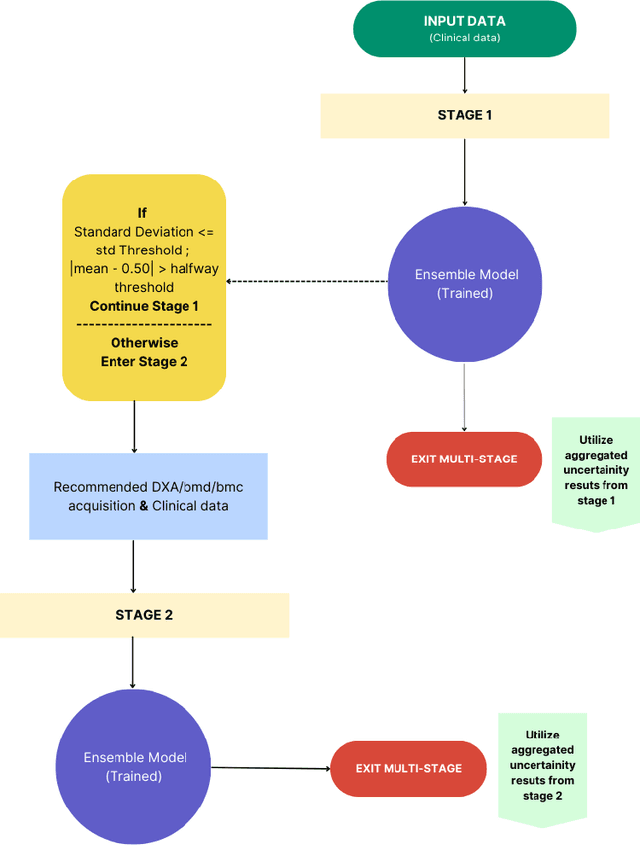
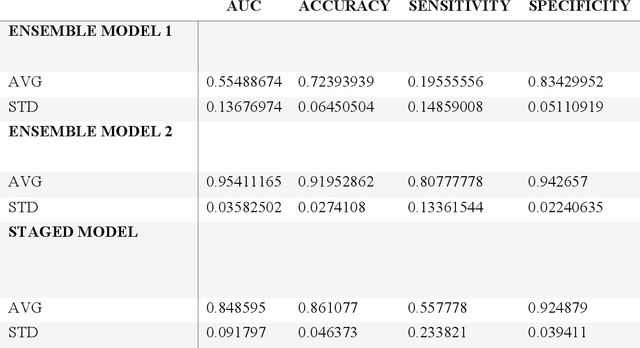
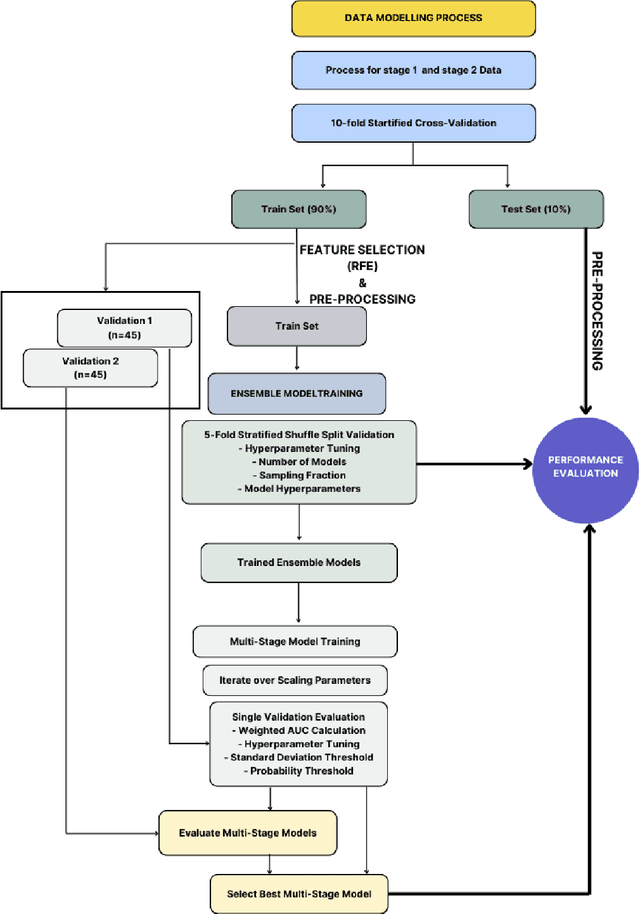
Despite advancements in medical care, hip fractures impose a significant burden on individuals and healthcare systems. This paper focuses on the prediction of hip fracture risk in older and middle-aged adults, where falls and compromised bone quality are predominant factors. We propose a novel staged model that combines advanced imaging and clinical data to improve predictive performance. By using CNNs to extract features from hip DXA images, along with clinical variables, shape measurements, and texture features, our method provides a comprehensive framework for assessing fracture risk. A staged machine learning-based model was developed using two ensemble models: Ensemble 1 (clinical variables only) and Ensemble 2 (clinical variables and DXA imaging features). This staged approach used uncertainty quantification from Ensemble 1 to decide if DXA features are necessary for further prediction. Ensemble 2 exhibited the highest performance, achieving an AUC of 0.9541, an accuracy of 0.9195, a sensitivity of 0.8078, and a specificity of 0.9427. The staged model also performed well, with an AUC of 0.8486, an accuracy of 0.8611, a sensitivity of 0.5578, and a specificity of 0.9249, outperforming Ensemble 1, which had an AUC of 0.5549, an accuracy of 0.7239, a sensitivity of 0.1956, and a specificity of 0.8343. Furthermore, the staged model suggested that 54.49% of patients did not require DXA scanning. It effectively balanced accuracy and specificity, offering a robust solution when DXA data acquisition is not always feasible. Statistical tests confirmed significant differences between the models, highlighting the advantages of the advanced modeling strategies. Our staged approach could identify individuals at risk with a high accuracy but reduce the unnecessary DXA scanning. It has great promise to guide interventions to prevent hip fractures with reduced cost and radiation.
A Demographic-Conditioned Variational Autoencoder for fMRI Distribution Sampling and Removal of Confounds
May 13, 2024



Objective: fMRI and derived measures such as functional connectivity (FC) have been used to predict brain age, general fluid intelligence, psychiatric disease status, and preclinical neurodegenerative disease. However, it is not always clear that all demographic confounds, such as age, sex, and race, have been removed from fMRI data. Additionally, many fMRI datasets are restricted to authorized researchers, making dissemination of these valuable data sources challenging. Methods: We create a variational autoencoder (VAE)-based model, DemoVAE, to decorrelate fMRI features from demographics and generate high-quality synthetic fMRI data based on user-supplied demographics. We train and validate our model using two large, widely used datasets, the Philadelphia Neurodevelopmental Cohort (PNC) and Bipolar and Schizophrenia Network for Intermediate Phenotypes (BSNIP). Results: We find that DemoVAE recapitulates group differences in fMRI data while capturing the full breadth of individual variations. Significantly, we also find that most clinical and computerized battery fields that are correlated with fMRI data are not correlated with DemoVAE latents. An exception are several fields related to schizophrenia medication and symptom severity. Conclusion: Our model generates fMRI data that captures the full distribution of FC better than traditional VAE or GAN models. We also find that most prediction using fMRI data is dependent on correlation with, and prediction of, demographics. Significance: Our DemoVAE model allows for generation of high quality synthetic data conditioned on subject demographics as well as the removal of the confounding effects of demographics. We identify that FC-based prediction tasks are highly influenced by demographic confounds.
Multi-View Variational Autoencoder for Missing Value Imputation in Untargeted Metabolomics
Oct 12, 2023


Background: Missing data is a common challenge in mass spectrometry-based metabolomics, which can lead to biased and incomplete analyses. The integration of whole-genome sequencing (WGS) data with metabolomics data has emerged as a promising approach to enhance the accuracy of data imputation in metabolomics studies. Method: In this study, we propose a novel method that leverages the information from WGS data and reference metabolites to impute unknown metabolites. Our approach utilizes a multi-view variational autoencoder to jointly model the burden score, polygenetic risk score (PGS), and linkage disequilibrium (LD) pruned single nucleotide polymorphisms (SNPs) for feature extraction and missing metabolomics data imputation. By learning the latent representations of both omics data, our method can effectively impute missing metabolomics values based on genomic information. Results: We evaluate the performance of our method on empirical metabolomics datasets with missing values and demonstrate its superiority compared to conventional imputation techniques. Using 35 template metabolites derived burden scores, PGS and LD-pruned SNPs, the proposed methods achieved r2-scores > 0.01 for 71.55% of metabolites. Conclusion: The integration of WGS data in metabolomics imputation not only improves data completeness but also enhances downstream analyses, paving the way for more comprehensive and accurate investigations of metabolic pathways and disease associations. Our findings offer valuable insights into the potential benefits of utilizing WGS data for metabolomics data imputation and underscore the importance of leveraging multi-modal data integration in precision medicine research.
CLCLSA: Cross-omics Linked embedding with Contrastive Learning and Self Attention for multi-omics integration with incomplete multi-omics data
Apr 12, 2023



Integration of heterogeneous and high-dimensional multi-omics data is becoming increasingly important in understanding genetic data. Each omics technique only provides a limited view of the underlying biological process and integrating heterogeneous omics layers simultaneously would lead to a more comprehensive and detailed understanding of diseases and phenotypes. However, one obstacle faced when performing multi-omics data integration is the existence of unpaired multi-omics data due to instrument sensitivity and cost. Studies may fail if certain aspects of the subjects are missing or incomplete. In this paper, we propose a deep learning method for multi-omics integration with incomplete data by Cross-omics Linked unified embedding with Contrastive Learning and Self Attention (CLCLSA). Utilizing complete multi-omics data as supervision, the model employs cross-omics autoencoders to learn the feature representation across different types of biological data. The multi-omics contrastive learning, which is used to maximize the mutual information between different types of omics, is employed before latent feature concatenation. In addition, the feature-level self-attention and omics-level self-attention are employed to dynamically identify the most informative features for multi-omics data integration. Extensive experiments were conducted on four public multi-omics datasets. The experimental results indicated that the proposed CLCLSA outperformed the state-of-the-art approaches for multi-omics data classification using incomplete multi-omics data.
ImageNomer: developing an fMRI and omics visualization tool to detect racial bias in functional connectivity
Feb 01, 2023It can be difficult to identify trends and perform quality control in large, high-dimensional fMRI or omics datasets. To remedy this, we develop ImageNomer, a data visualization and analysis tool that allows inspection of both subject-level and cohort-level features. The tool allows visualization of phenotype correlation with functional connectivity (FC), partial connectivity (PC), dictionary components (PCA and our own method), and genomic data (single-nucleotide polymorphisms, SNPs). In addition, it allows visualization of weights from arbitrary ML models. ImageNomer is built with a Python backend and a Vue frontend. We validate ImageNomer using the Philadelphia Neurodevelopmental Cohort (PNC) dataset, which contains multitask fMRI and SNP data of healthy adolescents. Using correlation, greedy selection, or model weights, we find that a set of 10 FC features can explain 15% of variation in age, compared to 35% for the full 34,716 feature model. The four most significant FCs are either between bilateral default mode network (DMN) regions or spatially proximal subcortical areas. Additionally, we show that whereas both FC (fMRI) and SNPs (genomic) features can account for 10-15% of intelligence variation, this predictive ability disappears when controlling for race. We find that FC features can be used to predict race with 85% accuracy, compared to 78% accuracy for sex prediction. Using ImageNomer, this work casts doubt on the possibility of finding unbiased intelligence-related features in fMRI and SNPs of healthy adolescents.
Hip Fracture Prediction using the First Principal Component Derived from FEA-Computed Fracture Loads
Oct 03, 2022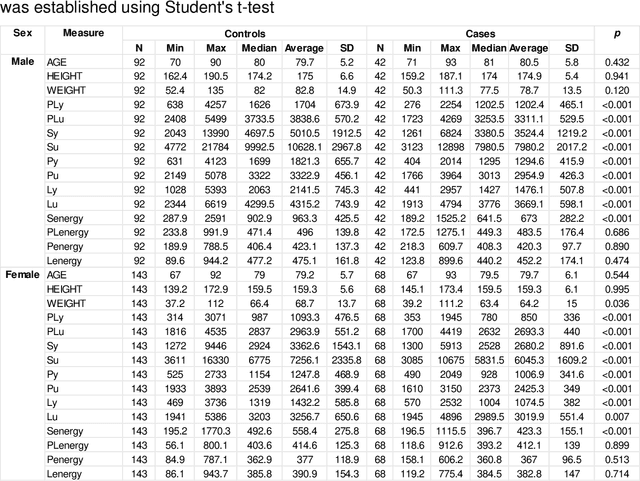
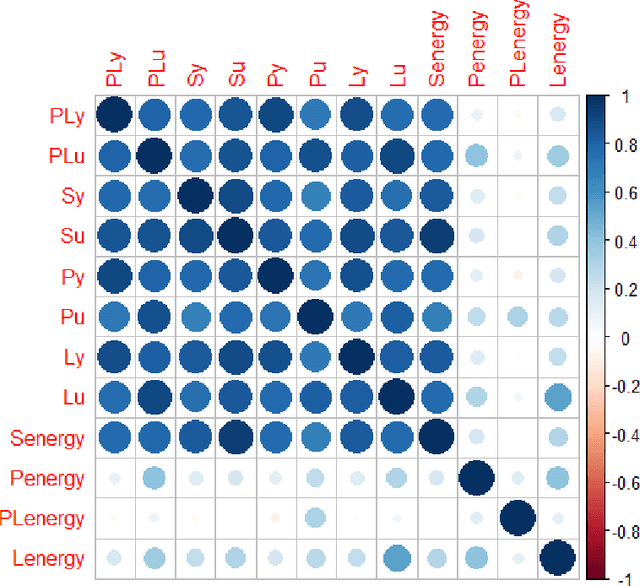
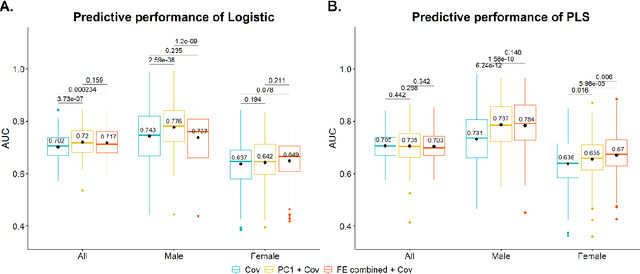
Hip fracture risk assessment is an important but challenging task. Quantitative CT-based patient specific finite element analysis (FEA) computes the force (fracture load) to break the proximal femur in a particular loading condition. It provides different structural information about the proximal femur that can influence a subject overall fracture risk. To obtain a more robust measure of fracture risk, we used principal component analysis (PCA) to develop a global FEA computed fracture risk index that incorporates the FEA-computed yield and ultimate failure loads and energies to failure in four loading conditions (single-limb stance and impact from a fall onto the posterior, posterolateral, and lateral aspects of the greater trochanter) of 110 hip fracture subjects and 235 age and sex matched control subjects from the AGES-Reykjavik study. We found that the first PC (PC1) of the FE parameters was the only significant predictor of hip fracture. Using a logistic regression model, we determined if prediction performance for hip fracture using PC1 differed from that using FE parameters combined by stratified random resampling with respect to hip fracture status. The results showed that the average of the area under the receive operating characteristic curve (AUC) using PC1 was always higher than that using all FE parameters combined in the male subjects. The AUC of PC1 and AUC of the FE parameters combined were not significantly different than that in the female subjects or in all subjects