 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenoBERT: A Language Model for Accurate Genotype Imputation
Mar 31, 2026Genotype imputation enables dense variant coverage for genome-wide association and risk-prediction studies, yet conventional reference-panel methods remain limited by ancestry bias and reduced rare-variant accuracy. We present Genotype Bidirectional Encoder Representations from Transformers (GenoBERT), a transformer-based, reference-free framework that tokenizes phased genotypes and uses a self-attention mechanism to capture both short- and long-range linkage disequilibrium (LD) dependencies. Benchmarking on two independent datasets including the Louisiana Osteoporosis Study (LOS) and the 1000 Genomes Project (1KGP) across ancestry groups and multiple genotype missingness levels (5-50%) shows that GenoBERT achieves the highest overall accuracy compared to four baseline methods (Beagle5.4, SCDA, BiU-Net, and STICI). At practical sparsity levels (up to 25% missing), GenoBERT attains high overall imputation accuracy ($r^2 approx 0.98$) across datasets, and maintains robust performance ($r^2 > 0.90$) even at 50% missingness. Experimental results across different ancestries confirm consistent gains across datasets, with resilience to small sample sizes and weak LD. A 128-SNP (single-nucleotide polymorphism) context window (approximately 100 Kb) is validated through LD-decay analyses as sufficient to capture local correlation structures. By eliminating reference-panel dependence while preserving high accuracy, GenoBERT provides a scalable and robust solution for genotype imputation and a foundation for downstream genomic modeling.
Learnable Instance Attention Filtering for Adaptive Detector Distillation
Mar 27, 2026As deep vision models grow increasingly complex to achieve higher performance, deployment efficiency has become a critical concern. Knowledge distillation (KD) mitigates this issue by transferring knowledge from large teacher models to compact student models. While many feature-based KD methods rely on spatial filtering to guide distillation, they typically treat all object instances uniformly, ignoring instance-level variability. Moreover, existing attention filtering mechanisms are typically heuristic or teacher-driven, rather than learned with the student. To address these limitations, we propose Learnable Instance Attention Filtering for Adaptive Detector Distillation (LIAF-KD), a novel framework that introduces learnable instance selectors to dynamically evaluate and reweight instance importance during distillation. Notably, the student contributes to this process based on its evolving learning state. Experiments on the KITTI and COCO datasets demonstrate consistent improvements, with a 2% gain on a GFL ResNet-50 student without added complexity, outperforming state-of-the-art methods.
Full-Frequency Temporal Patching and Structured Masking for Enhanced Audio Classification
Aug 28, 2025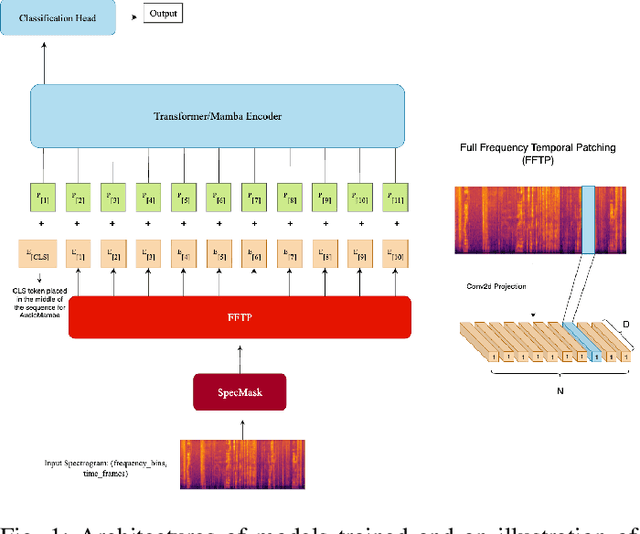
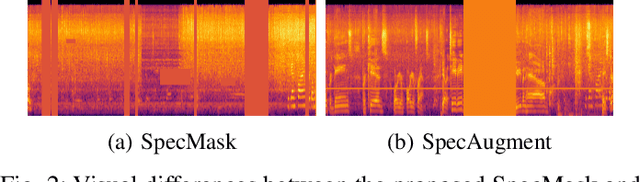
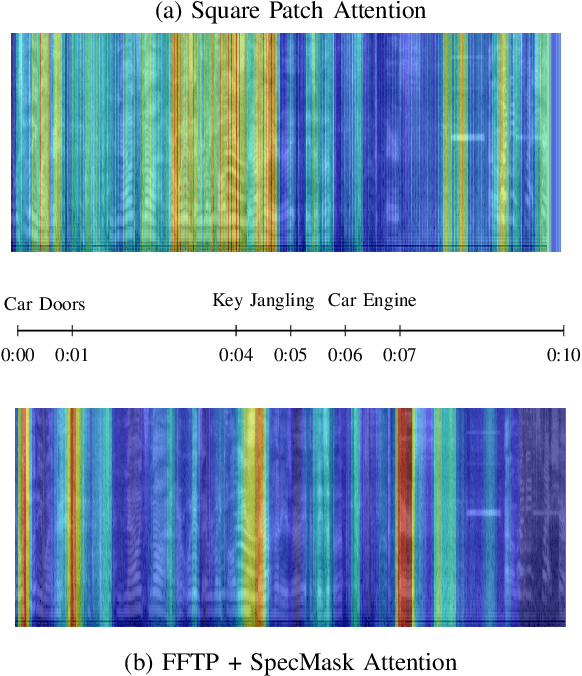
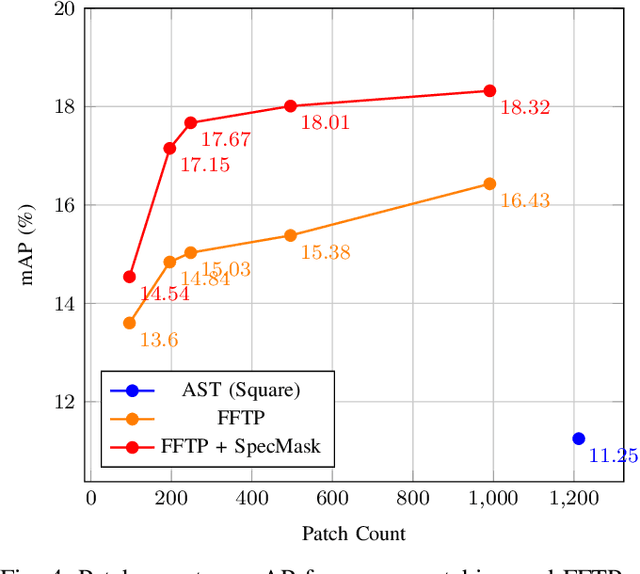
Transformers and State-Space Models (SSMs) have advanced audio classification by modeling spectrograms as sequences of patches. However, existing models such as the Audio Spectrogram Transformer (AST) and Audio Mamba (AuM) adopt square patching from computer vision, which disrupts continuous frequency patterns and produces an excessive number of patches, slowing training, and increasing computation. We propose Full-Frequency Temporal Patching (FFTP), a patching strategy that better matches the time-frequency asymmetry of spectrograms by spanning full frequency bands with localized temporal context, preserving harmonic structure, and significantly reducing patch count and computation. We also introduce SpecMask, a patch-aligned spectrogram augmentation that combines full-frequency and localized time-frequency masks under a fixed masking budget, enhancing temporal robustness while preserving spectral continuity. When applied on both AST and AuM, our patching method with SpecMask improves mAP by up to +6.76 on AudioSet-18k and accuracy by up to +8.46 on SpeechCommandsV2, while reducing computation by up to 83.26%, demonstrating both performance and efficiency gains.
ETT-CKGE: Efficient Task-driven Tokens for Continual Knowledge Graph Embedding
Jun 09, 2025Continual Knowledge Graph Embedding (CKGE) seeks to integrate new knowledge while preserving past information. However, existing methods struggle with efficiency and scalability due to two key limitations: (1) suboptimal knowledge preservation between snapshots caused by manually designed node/relation importance scores that ignore graph dependencies relevant to the downstream task, and (2) computationally expensive graph traversal for node/relation importance calculation, leading to slow training and high memory overhead. To address these limitations, we introduce ETT-CKGE (Efficient, Task-driven, Tokens for Continual Knowledge Graph Embedding), a novel task-guided CKGE method that leverages efficient task-driven tokens for efficient and effective knowledge transfer between snapshots. Our method introduces a set of learnable tokens that directly capture task-relevant signals, eliminating the need for explicit node scoring or traversal. These tokens serve as consistent and reusable guidance across snapshots, enabling efficient token-masked embedding alignment between snapshots. Importantly, knowledge transfer is achieved through simple matrix operations, significantly reducing training time and memory usage. Extensive experiments across six benchmark datasets demonstrate that ETT-CKGE consistently achieves superior or competitive predictive performance, while substantially improving training efficiency and scalability compared to state-of-the-art CKGE methods. The code is available at: https://github.com/lijingzhu1/ETT-CKGE/tree/main
Topology-Guided Knowledge Distillation for Efficient Point Cloud Processing
May 12, 2025Point cloud processing has gained significant attention due to its critical role in applications such as autonomous driving and 3D object recognition. However, deploying high-performance models like Point Transformer V3 in resource-constrained environments remains challenging due to their high computational and memory demands. This work introduces a novel distillation framework that leverages topology-aware representations and gradient-guided knowledge distillation to effectively transfer knowledge from a high-capacity teacher to a lightweight student model. Our approach captures the underlying geometric structures of point clouds while selectively guiding the student model's learning process through gradient-based feature alignment. Experimental results in the Nuscenes, SemanticKITTI, and Waymo datasets demonstrate that the proposed method achieves competitive performance, with an approximately 16x reduction in model size and a nearly 1.9x decrease in inference time compared to its teacher model. Notably, on NuScenes, our method achieves state-of-the-art performance among knowledge distillation techniques trained solely on LiDAR data, surpassing prior knowledge distillation baselines in segmentation performance. Our implementation is available publicly at: https://github.com/HySonLab/PointDistill
ACAM-KD: Adaptive and Cooperative Attention Masking for Knowledge Distillation
Mar 08, 2025



Dense visual prediction tasks, such as detection and segmentation, are crucial for time-critical applications (e.g., autonomous driving and video surveillance). While deep models achieve strong performance, their efficiency remains a challenge. Knowledge distillation (KD) is an effective model compression technique, but existing feature-based KD methods rely on static, teacher-driven feature selection, failing to adapt to the student's evolving learning state or leverage dynamic student-teacher interactions. To address these limitations, we propose Adaptive student-teacher Cooperative Attention Masking for Knowledge Distillation (ACAM-KD), which introduces two key components: (1) Student-Teacher Cross-Attention Feature Fusion (STCA-FF), which adaptively integrates features from both models for a more interactive distillation process, and (2) Adaptive Spatial-Channel Masking (ASCM), which dynamically generates importance masks to enhance both spatial and channel-wise feature selection. Unlike conventional KD methods, ACAM-KD adapts to the student's evolving needs throughout the entire distillation process. Extensive experiments on multiple benchmarks validate its effectiveness. For instance, on COCO2017, ACAM-KD improves object detection performance by up to 1.4 mAP over the state-of-the-art when distilling a ResNet-50 student from a ResNet-101 teacher. For semantic segmentation on Cityscapes, it boosts mIoU by 3.09 over the baseline with DeepLabV3-MobileNetV2 as the student model.
PFedDST: Personalized Federated Learning with Decentralized Selection Training
Feb 11, 2025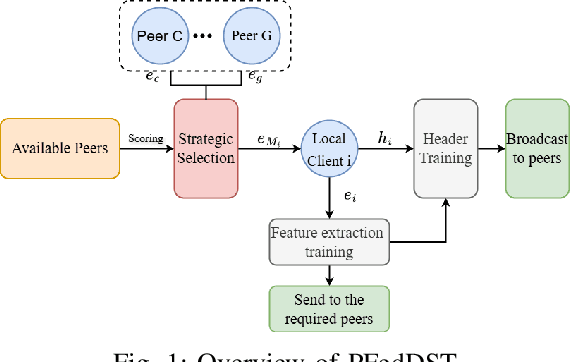
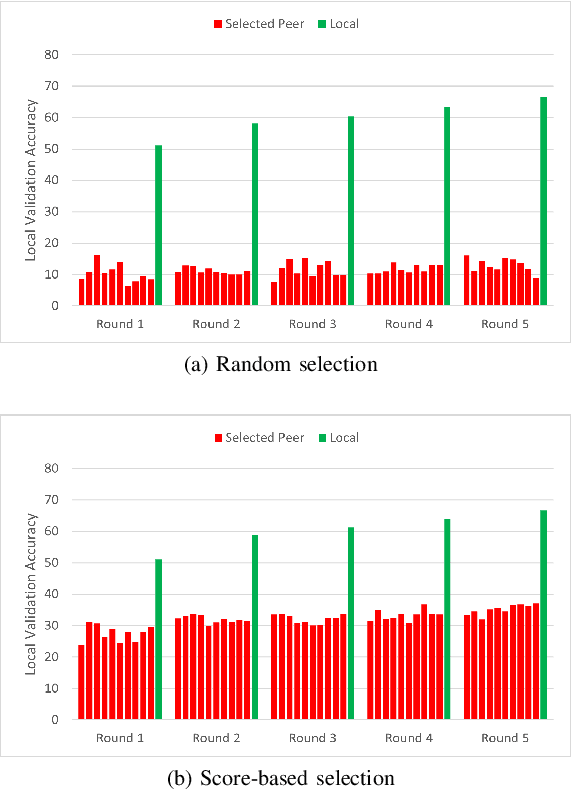
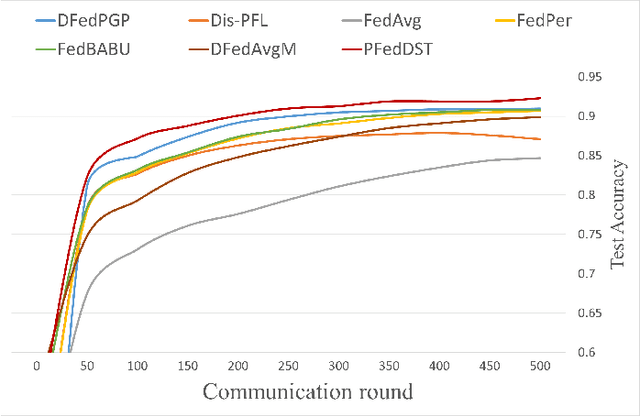
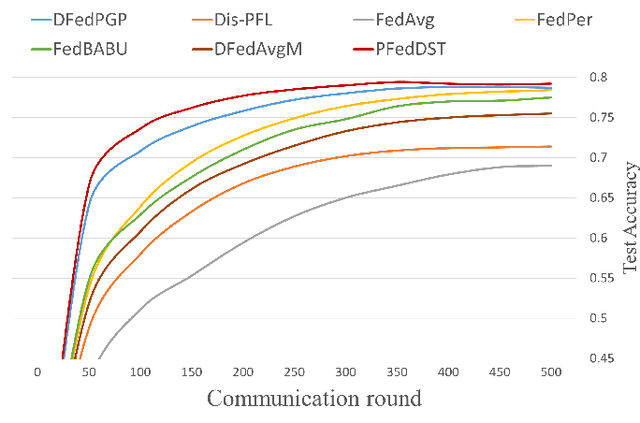
Distributed Learning (DL) enables the training of machine learning models across multiple devices, yet it faces challenges like non-IID data distributions and device capability disparities, which can impede training efficiency. Communication bottlenecks further complicate traditional Federated Learning (FL) setups. To mitigate these issues, we introduce the Personalized Federated Learning with Decentralized Selection Training (PFedDST) framework. PFedDST enhances model training by allowing devices to strategically evaluate and select peers based on a comprehensive communication score. This score integrates loss, task similarity, and selection frequency, ensuring optimal peer connections. This selection strategy is tailored to increase local personalization and promote beneficial peer collaborations to strengthen the stability and efficiency of the training process. Our experiments demonstrate that PFedDST not only enhances model accuracy but also accelerates convergence. This approach outperforms state-of-the-art methods in handling data heterogeneity, delivering both faster and more effective training in diverse and decentralized systems.
A Staged Approach using Machine Learning and Uncertainty Quantification to Predict the Risk of Hip Fracture
May 30, 2024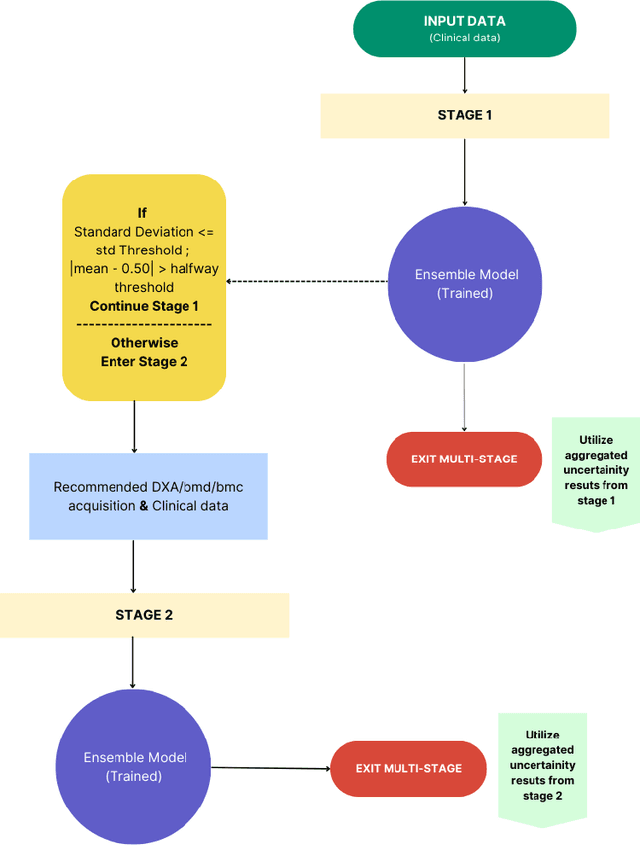
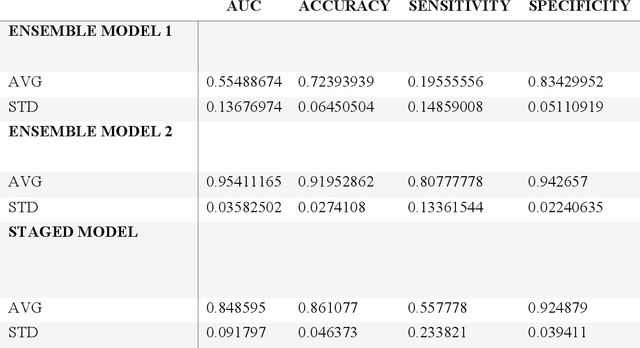
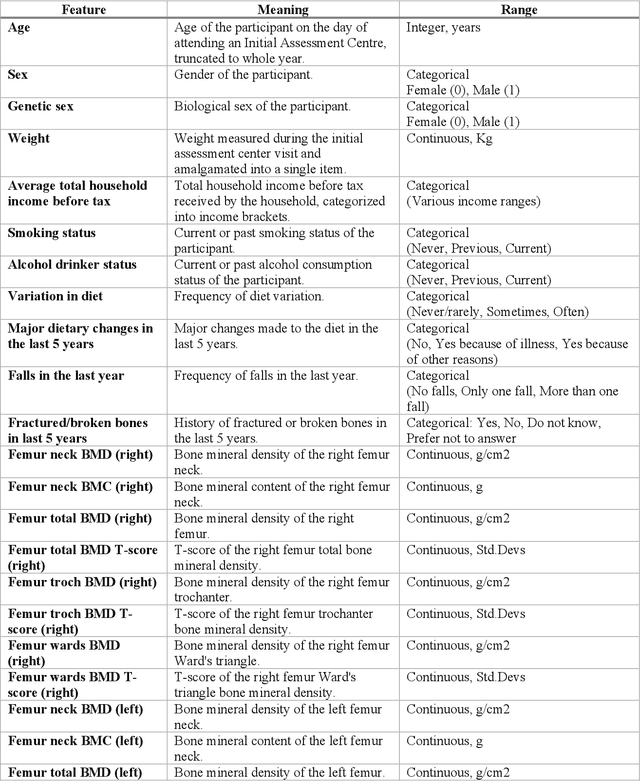
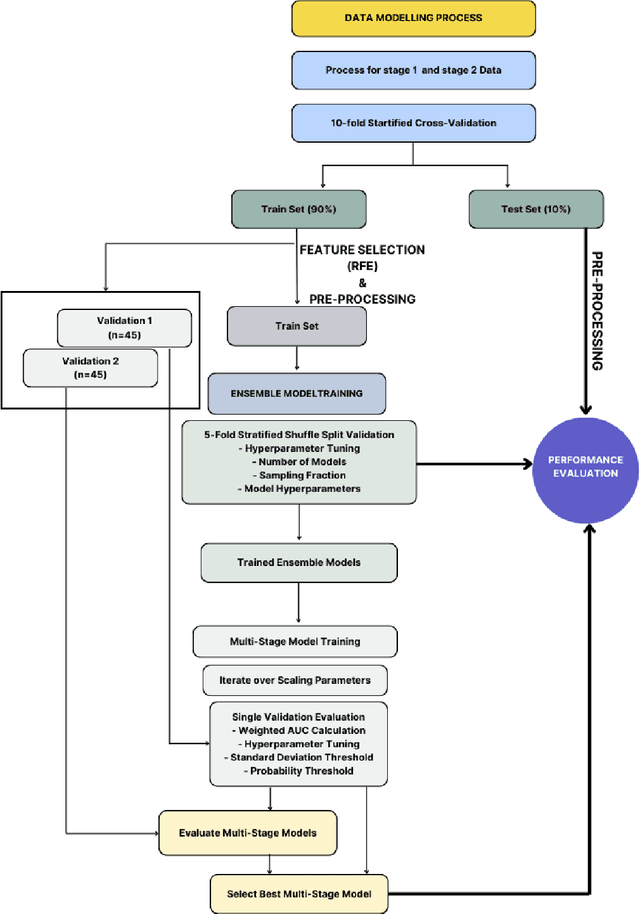
Despite advancements in medical care, hip fractures impose a significant burden on individuals and healthcare systems. This paper focuses on the prediction of hip fracture risk in older and middle-aged adults, where falls and compromised bone quality are predominant factors. We propose a novel staged model that combines advanced imaging and clinical data to improve predictive performance. By using CNNs to extract features from hip DXA images, along with clinical variables, shape measurements, and texture features, our method provides a comprehensive framework for assessing fracture risk. A staged machine learning-based model was developed using two ensemble models: Ensemble 1 (clinical variables only) and Ensemble 2 (clinical variables and DXA imaging features). This staged approach used uncertainty quantification from Ensemble 1 to decide if DXA features are necessary for further prediction. Ensemble 2 exhibited the highest performance, achieving an AUC of 0.9541, an accuracy of 0.9195, a sensitivity of 0.8078, and a specificity of 0.9427. The staged model also performed well, with an AUC of 0.8486, an accuracy of 0.8611, a sensitivity of 0.5578, and a specificity of 0.9249, outperforming Ensemble 1, which had an AUC of 0.5549, an accuracy of 0.7239, a sensitivity of 0.1956, and a specificity of 0.8343. Furthermore, the staged model suggested that 54.49% of patients did not require DXA scanning. It effectively balanced accuracy and specificity, offering a robust solution when DXA data acquisition is not always feasible. Statistical tests confirmed significant differences between the models, highlighting the advantages of the advanced modeling strategies. Our staged approach could identify individuals at risk with a high accuracy but reduce the unnecessary DXA scanning. It has great promise to guide interventions to prevent hip fractures with reduced cost and radiation.
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
May 20, 2024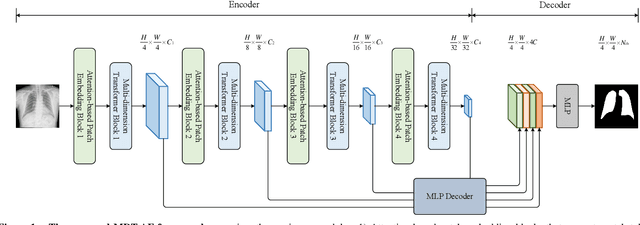
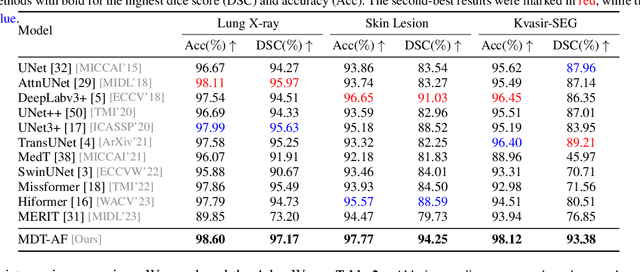
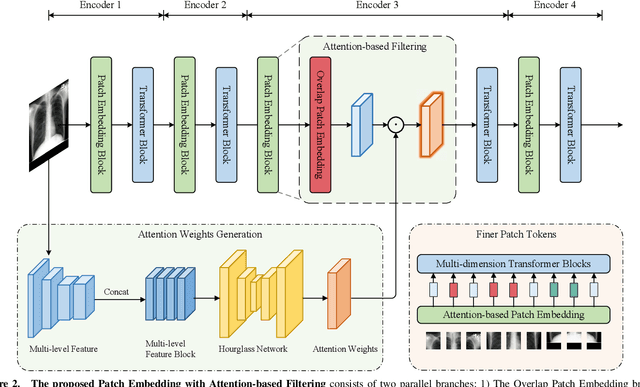
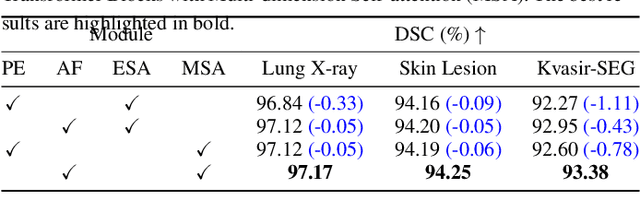
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
SKGHOI: Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection
Mar 15, 2023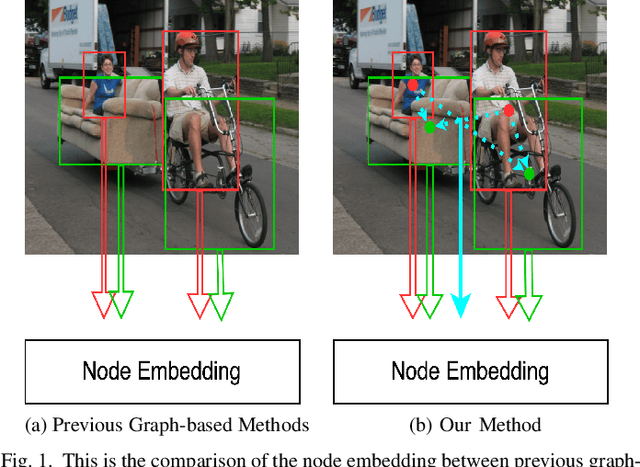
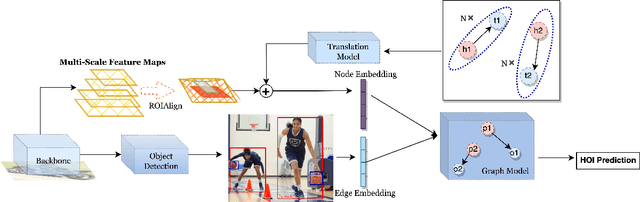

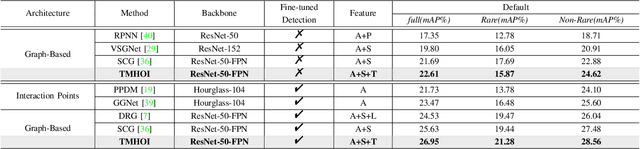
Detecting human-object interactions (HOIs) is a challenging problem in computer vision. Existing techniques for HOI detection heavily rely on appearance-based features, which may not capture other essential characteristics for accurate detection. Furthermore, the use of transformer-based models for sentiment representation of human-object pairs can be computationally expensive. To address these challenges, we propose a novel graph-based approach, SKGHOI (Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection), that effectively captures the sentiment representation of HOIs by integrating both spatial and semantic knowledge. In a graph, SKGHOI takes the components of interaction as nodes, and the spatial relationships between them as edges. Our approach employs a spatial encoder and a semantic encoder to extract spatial and semantic information, respectively, and then combines these encodings to create a knowledge graph that captures the sentiment representation of HOIs. Compared to existing techniques, SKGHOI is computationally efficient and allows for the incorporation of prior knowledge, making it practical for use in real-world applications. We demonstrate the effectiveness of our proposed method on the widely-used HICO-DET datasets, where it outperforms existing state-of-the-art graph-based methods by a significant margin. Our results indicate that the SKGHOI approach has the potential to significantly improve the accuracy and efficiency of HOI detection, and we anticipate that it will be of great interest to researchers and practitioners working on this challenging task.