 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFedDST: Personalized Federated Learning with Decentralized Selection Training
Feb 11, 2025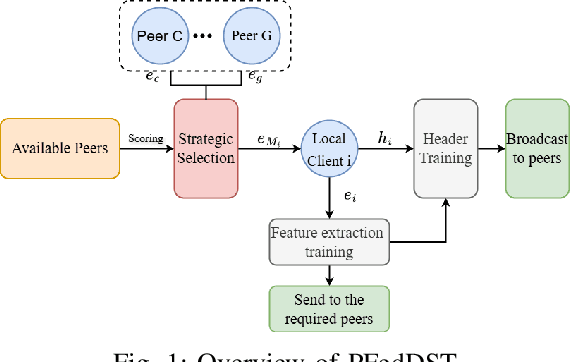
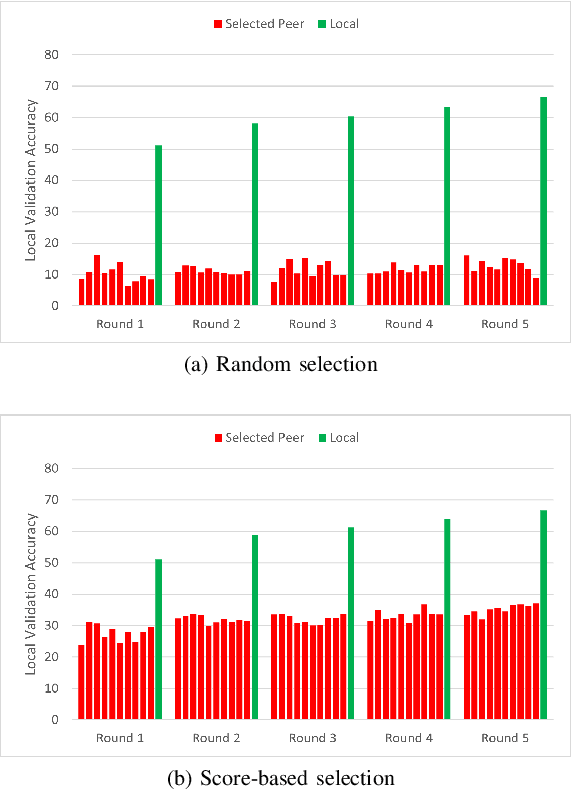
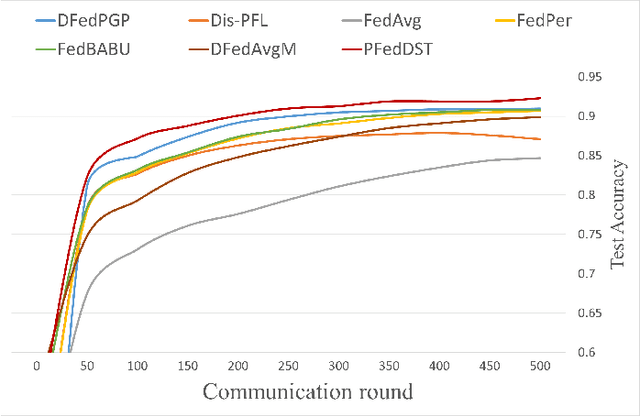
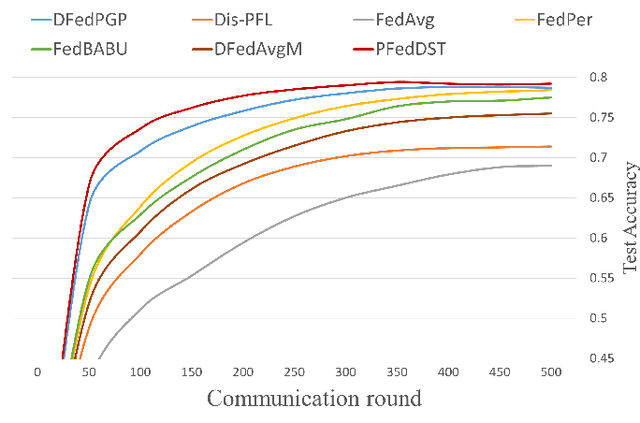
Distributed Learning (DL) enables the training of machine learning models across multiple devices, yet it faces challenges like non-IID data distributions and device capability disparities, which can impede training efficiency. Communication bottlenecks further complicate traditional Federated Learning (FL) setups. To mitigate these issues, we introduce the Personalized Federated Learning with Decentralized Selection Training (PFedDST) framework. PFedDST enhances model training by allowing devices to strategically evaluate and select peers based on a comprehensive communication score. This score integrates loss, task similarity, and selection frequency, ensuring optimal peer connections. This selection strategy is tailored to increase local personalization and promote beneficial peer collaborations to strengthen the stability and efficiency of the training process. Our experiments demonstrate that PFedDST not only enhances model accuracy but also accelerates convergence. This approach outperforms state-of-the-art methods in handling data heterogeneity, delivering both faster and more effective training in diverse and decentralized systems.
Measuring Heterogeneity in Machine Learning with Distributed Energy Distance
Jan 27, 2025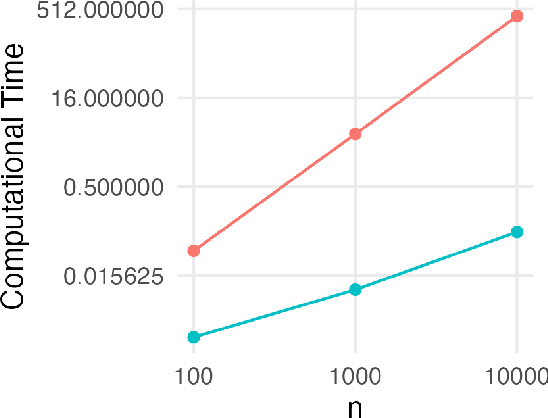
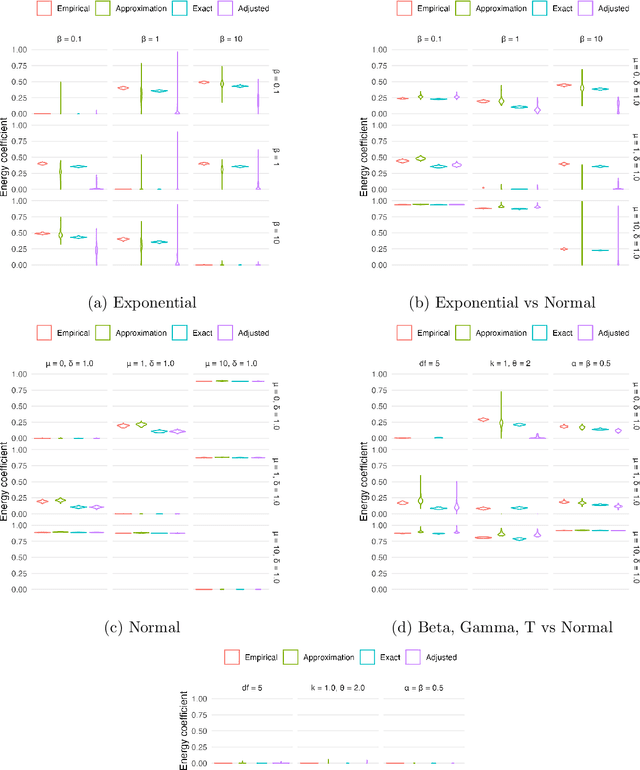

In distributed and federated learning, heterogeneity across data sources remains a major obstacle to effective model aggregation and convergence. We focus on feature heterogeneity and introduce energy distance as a sensitive measure for quantifying distributional discrepancies. While we show that energy distance is robust for detecting data distribution shifts, its direct use in large-scale systems can be prohibitively expensive. To address this, we develop Taylor approximations that preserve key theoretical quantitative properties while reducing computational overhead. Through simulation studies, we show how accurately capturing feature discrepancies boosts convergence in distributed learning. Finally, we propose a novel application of energy distance to assign penalty weights for aligning predictions across heterogeneous nodes, ultimately enhancing coordination in federated and distributed settings.
Interpretable Data Fusion for Distributed Learning: A Representative Approach via Gradient Matching
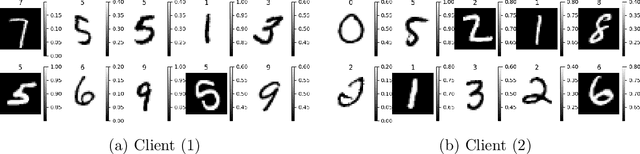
May 06, 2024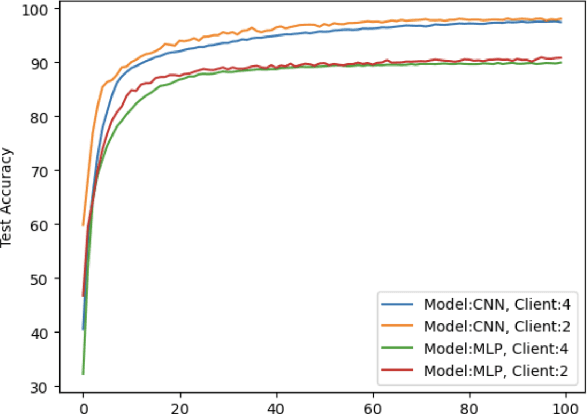
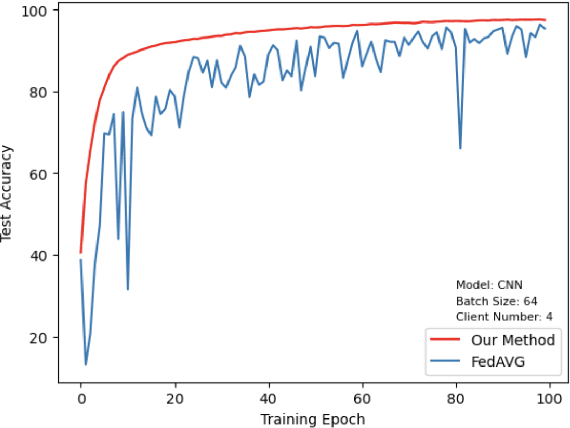
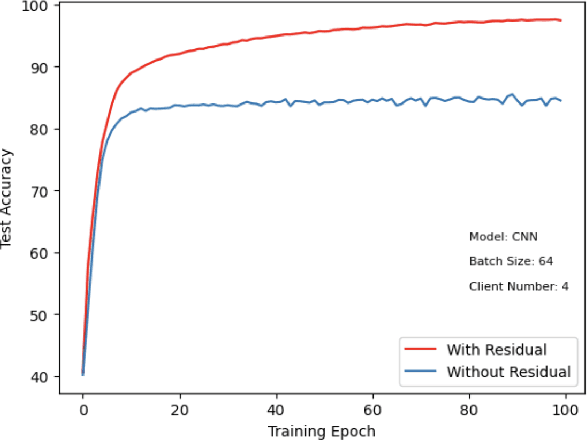

This paper introduces a representative-based approach for distributed learning that transforms multiple raw data points into a virtual representation. Unlike traditional distributed learning methods such as Federated Learning, which do not offer human interpretability, our method makes complex machine learning processes accessible and comprehensible. It achieves this by condensing extensive datasets into digestible formats, thus fostering intuitive human-machine interactions. Additionally, this approach maintains privacy and communication efficiency, and it matches the training performance of models using raw data. Simulation results show that our approach is competitive with or outperforms traditional Federated Learning in accuracy and convergence, especially in scenarios with complex models and a higher number of clients. This framework marks a step forward in integrating human intuition with machine intelligence, which potentially enhances human-machine learning interfaces and collaborative efforts.