 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICON: Indirect Prompt Injection Defense for Agents based on Inference-Time Correction
Feb 24, 2026Large Language Model (LLM) agents are susceptible to Indirect Prompt Injection (IPI) attacks, where malicious instructions in retrieved content hijack the agent's execution. Existing defenses typically rely on strict filtering or refusal mechanisms, which suffer from a critical limitation: over-refusal, prematurely terminating valid agentic workflows. We propose ICON, a probing-to-mitigation framework that neutralizes attacks while preserving task continuity. Our key insight is that IPI attacks leave distinct over-focusing signatures in the latent space. We introduce a Latent Space Trace Prober to detect attacks based on high intensity scores. Subsequently, a Mitigating Rectifier performs surgical attention steering that selectively manipulate adversarial query key dependencies while amplifying task relevant elements to restore the LLM's functional trajectory. Extensive evaluations on multiple backbones show that ICON achieves a competitive 0.4% ASR, matching commercial grade detectors, while yielding a over 50% task utility gain. Furthermore, ICON demonstrates robust Out of Distribution(OOD) generalization and extends effectively to multi-modal agents, establishing a superior balance between security and efficiency.
AdapTools: Adaptive Tool-based Indirect Prompt Injection Attacks on Agentic LLMs
Feb 24, 2026The integration of external data services (e.g., Model Context Protocol, MCP) has made large language model-based agents increasingly powerful for complex task execution. However, this advancement introduces critical security vulnerabilities, particularly indirect prompt injection (IPI) attacks. Existing attack methods are limited by their reliance on static patterns and evaluation on simple language models, failing to address the fast-evolving nature of modern AI agents. We introduce AdapTools, a novel adaptive IPI attack framework that selects stealthier attack tools and generates adaptive attack prompts to create a rigorous security evaluation environment. Our approach comprises two key components: (1) Adaptive Attack Strategy Construction, which develops transferable adversarial strategies for prompt optimization, and (2) Attack Enhancement, which identifies stealthy tools capable of circumventing task-relevance defenses. Comprehensive experimental evaluation shows that AdapTools achieves a 2.13 times improvement in attack success rate while degrading system utility by a factor of 1.78. Notably, the framework maintains its effectiveness even against state-of-the-art defense mechanisms. Our method advances the understanding of IPI attacks and provides a useful reference for future research.
A Linear Fractional Transformation Model and Calibration Method for Light Field Camera
Nov 06, 2025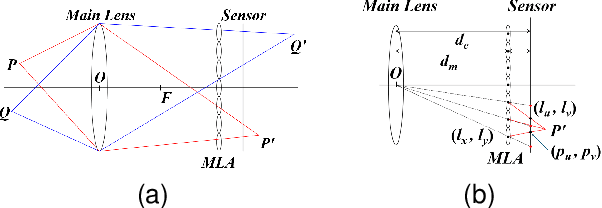
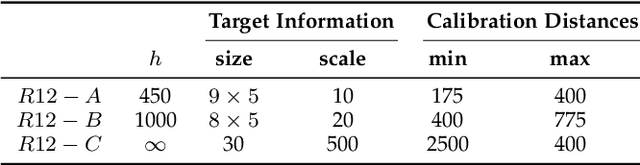
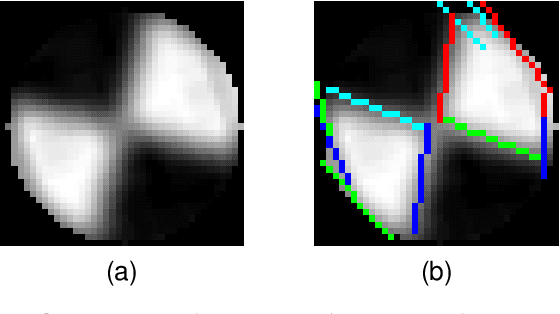
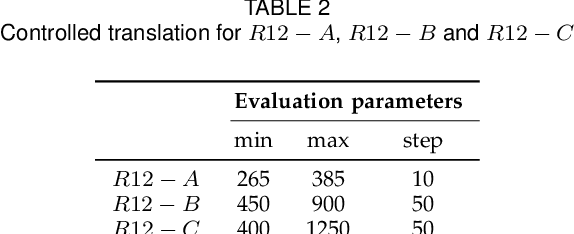
Accurate calibration of internal parameters is a crucial yet challenging prerequisite for 3D reconstruction using light field cameras. In this paper, we propose a linear fractional transformation(LFT) parameter $α$ to decoupled the main lens and micro lens array (MLA). The proposed method includes an analytical solution based on least squares, followed by nonlinear refinement. The method for detecting features from the raw images is also introduced. Experimental results on both physical and simulated data have verified the performance of proposed method. Based on proposed model, the simulation of raw light field images becomes faster, which is crucial for data-driven deep learning methods. The corresponding code can be obtained from the author's website.
Measuring Heterogeneity in Machine Learning with Distributed Energy Distance
Jan 27, 2025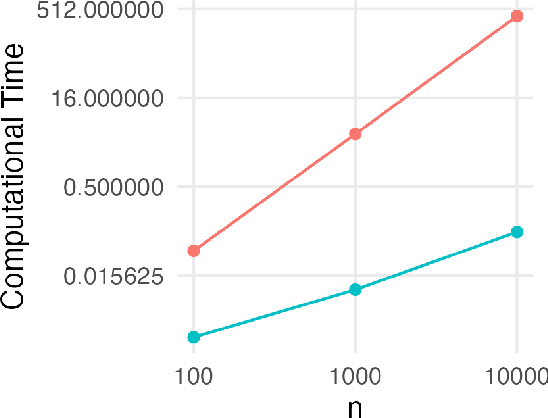
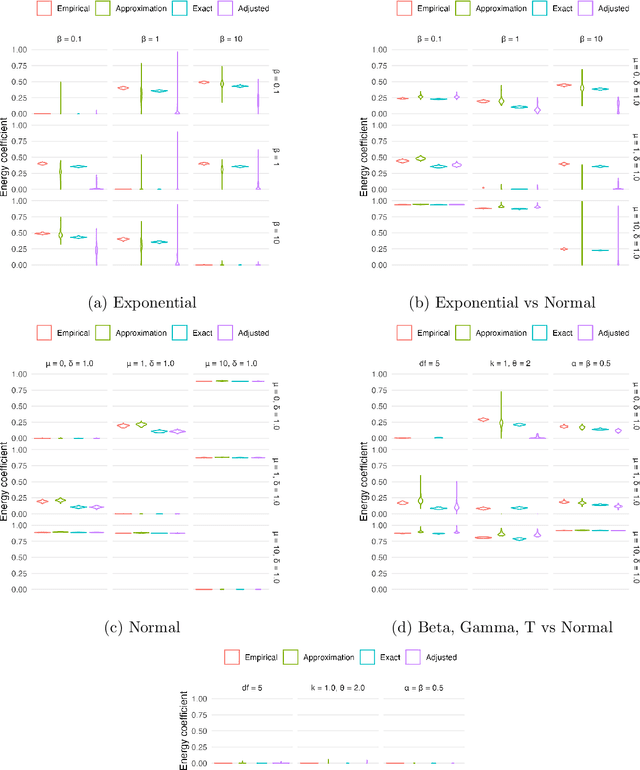

In distributed and federated learning, heterogeneity across data sources remains a major obstacle to effective model aggregation and convergence. We focus on feature heterogeneity and introduce energy distance as a sensitive measure for quantifying distributional discrepancies. While we show that energy distance is robust for detecting data distribution shifts, its direct use in large-scale systems can be prohibitively expensive. To address this, we develop Taylor approximations that preserve key theoretical quantitative properties while reducing computational overhead. Through simulation studies, we show how accurately capturing feature discrepancies boosts convergence in distributed learning. Finally, we propose a novel application of energy distance to assign penalty weights for aligning predictions across heterogeneous nodes, ultimately enhancing coordination in federated and distributed settings.
MvKeTR: Chest CT Report Generation with Multi-View Perception and Knowledge Enhancement
Nov 27, 2024

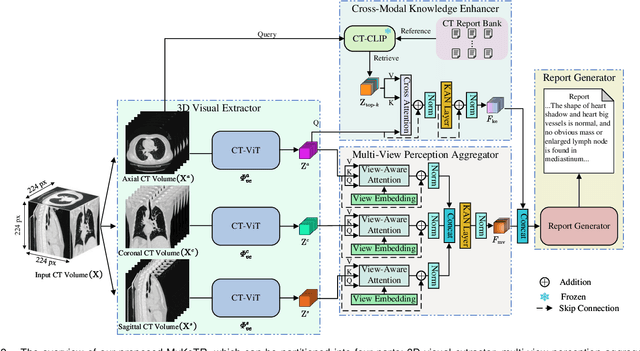

CT report generation (CTRG) aims to automatically generate diagnostic reports for 3D volumes, relieving clinicians' workload and improving patient care. Despite clinical value, existing works fail to effectively incorporate diagnostic information from multiple anatomical views and lack related clinical expertise essential for accurate and reliable diagnosis. To resolve these limitations, we propose a novel Multi-view perception Knowledge-enhanced Tansformer (MvKeTR) to mimic the diagnostic workflow of clinicians. Just as radiologists first examine CT scans from multiple planes, a Multi-View Perception Aggregator (MVPA) with view-aware attention effectively synthesizes diagnostic information from multiple anatomical views. Then, inspired by how radiologists further refer to relevant clinical records to guide diagnostic decision-making, a Cross-Modal Knowledge Enhancer (CMKE) retrieves the most similar reports based on the query volume to incorporate domain knowledge into the diagnosis procedure. Furthermore, instead of traditional MLPs, we employ Kolmogorov-Arnold Networks (KANs) with learnable nonlinear activation functions as the fundamental building blocks of both modules to better capture intricate diagnostic patterns in CT interpretation. Extensive experiments on the public CTRG-Chest-548K dataset demonstrate that our method outpaces prior state-of-the-art models across all metrics.
An Oversampling-enhanced Multi-class Imbalanced Classification Framework for Patient Health Status Prediction Using Patient-reported Outcomes
Nov 16, 2024



Patient-reported outcomes (PROs) directly collected from cancer patients being treated with radiation therapy play a vital role in assisting clinicians in counseling patients regarding likely toxicities. Precise prediction and evaluation of symptoms or health status associated with PROs are fundamental to enhancing decision-making and planning for the required services and support as patients transition into survivorship. However, the raw PRO data collected from hospitals exhibits some intrinsic challenges such as incomplete item reports and imbalance patient toxicities. To the end, in this study, we explore various machine learning techniques to predict patient outcomes related to health status such as pain levels and sleep discomfort using PRO datasets from a cancer photon/proton therapy center. Specifically, we deploy six advanced machine learning classifiers -- Random Forest (RF), XGBoost, Gradient Boosting (GB), Support Vector Machine (SVM), Multi-Layer Perceptron with Bagging (MLP-Bagging), and Logistic Regression (LR) -- to tackle a multi-class imbalance classification problem across three prevalent cancer types: head and neck, prostate, and breast cancers. To address the class imbalance issue, we employ an oversampling strategy, adjusting the training set sample sizes through interpolations of in-class neighboring samples, thereby augmenting minority classes without deviating from the original skewed class distribution. Our experimental findings across multiple PRO datasets indicate that the RF and XGB methods achieve robust generalization performance, evidenced by weighted AUC and detailed confusion matrices, in categorizing outcomes as mild, intermediate, and severe post-radiation therapy. These results underscore the models' effectiveness and potential utility in clinical settings.
Non-Uniform Sampling Reconstruction for Symmetrical NMR Spectroscopy by Exploiting Inherent Symmetry
Sep 24, 2023



Symmetrical NMR spectroscopy constitutes a vital branch of multidimensional NMR spectroscopy, providing a powerful tool for the structural elucidation of biological macromolecules. Non-Uniform Sampling (NUS) serves as an effective strategy for averting the prohibitive acquisition time of multidimensional NMR spectroscopy by only sampling a few points according to NUS sampling schedules and reconstructing missing points via algorithms. However, current sampling schedules are unable to maintain the accurate recovery of cross peaks that are weak but important. In this work, we propose a novel sampling schedule termed as SCPG (Symmetrical Copy Poisson Gap) and employ CS (Compressed Sensing) methods for reconstruction. We theoretically prove that the symmetrical constraint, apart from sparsity, is implicitly implemented when SCPG is combined with CS methods. The simulated and experimental data substantiate the advantage of SCPG over state-of-the-art 2D Woven PG in the NUS reconstruction of symmetrical NMR spectroscopy.
High-efficient deep learning-based DTI reconstruction with flexible diffusion gradient encoding scheme
Aug 02, 2023Purpose: To develop and evaluate a novel dynamic-convolution-based method called FlexDTI for high-efficient diffusion tensor reconstruction with flexible diffusion encoding gradient schemes. Methods: FlexDTI was developed to achieve high-quality DTI parametric mapping with flexible number and directions of diffusion encoding gradients. The proposed method used dynamic convolution kernels to embed diffusion gradient direction information into feature maps of the corresponding diffusion signal. Besides, our method realized the generalization of a flexible number of diffusion gradient directions by setting the maximum number of input channels of the network. The network was trained and tested using data sets from the Human Connectome Project and a local hospital. Results from FlexDTI and other advanced tensor parameter estimation methods were compared. Results: Compared to other methods, FlexDTI successfully achieves high-quality diffusion tensor-derived variables even if the number and directions of diffusion encoding gradients are variable. It increases peak signal-to-noise ratio (PSNR) by about 10 dB on Fractional Anisotropy (FA) and Mean Diffusivity (MD), compared with the state-of-the-art deep learning method with flexible diffusion encoding gradient schemes. Conclusion: FlexDTI can well learn diffusion gradient direction information to achieve generalized DTI reconstruction with flexible diffusion gradient schemes. Both flexibility and reconstruction quality can be taken into account in this network.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023
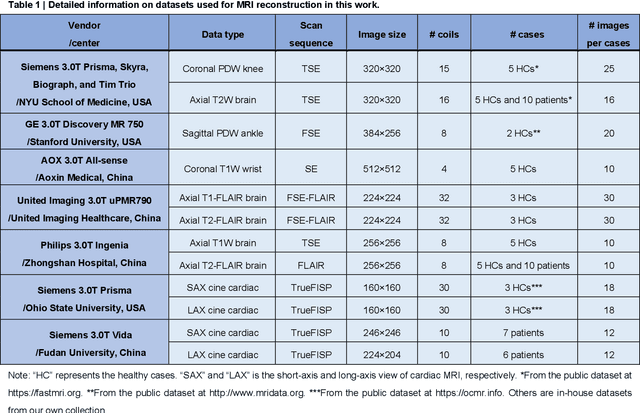
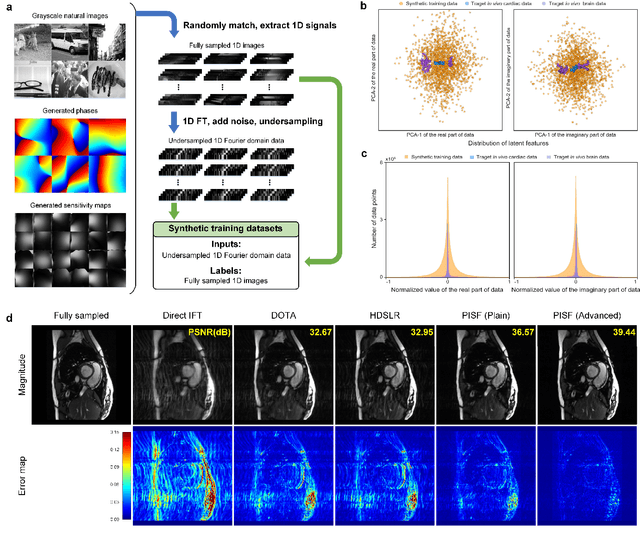
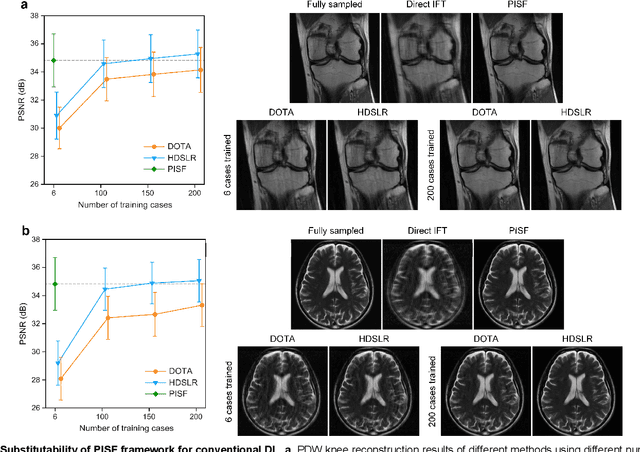
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.
Convex Dual Theory Analysis of Two-Layer Convolutional Neural Networks with Soft-Thresholding
Apr 14, 2023



Soft-thresholding has been widely used in neural networks. Its basic network structure is a two-layer convolution neural network with soft-thresholding. Due to the network's nature of nonlinearity and nonconvexity, the training process heavily depends on an appropriate initialization of network parameters, resulting in the difficulty of obtaining a globally optimal solution. To address this issue, a convex dual network is designed here. We theoretically analyze the network convexity and numerically confirm that the strong duality holds. This conclusion is further verified in the linear fitting and denoising experiments. This work provides a new way to convexify soft-thresholding neural networks.