 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024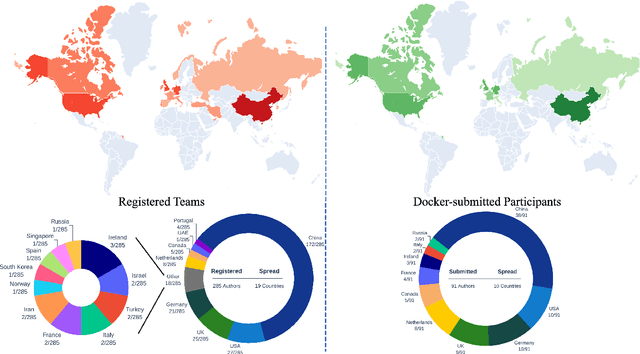
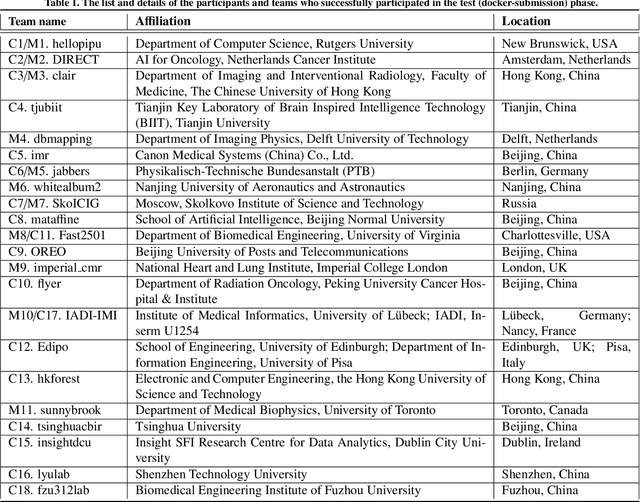
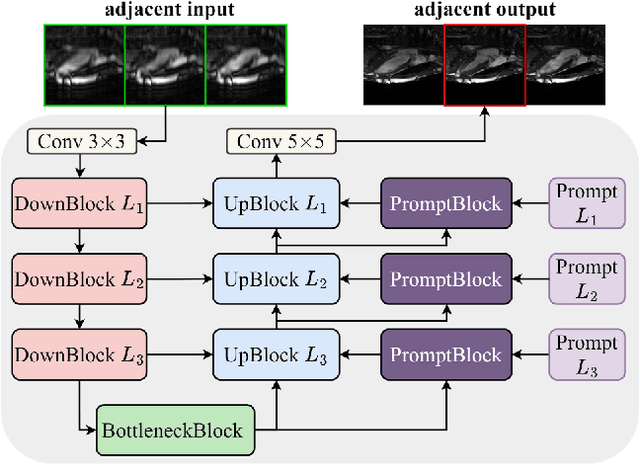
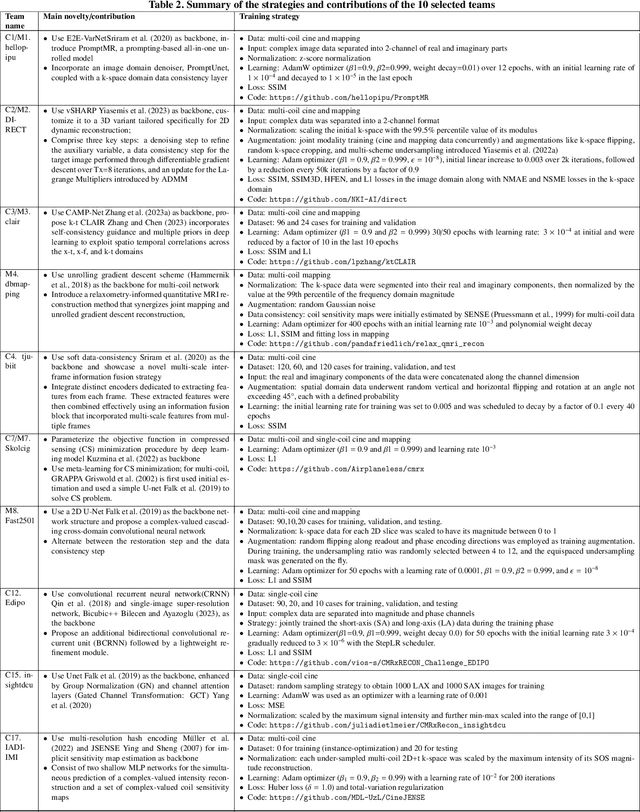
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023
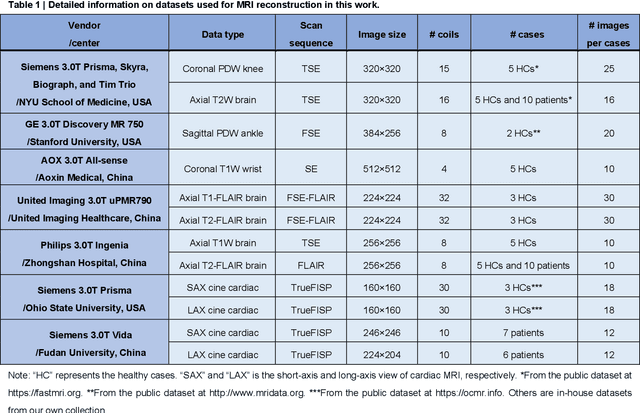
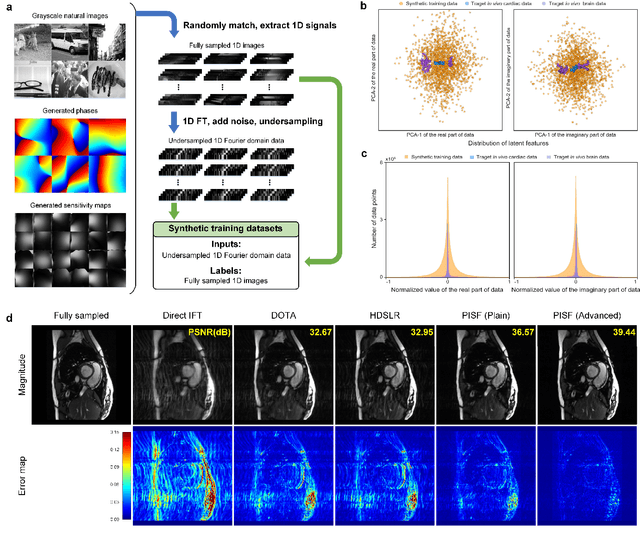
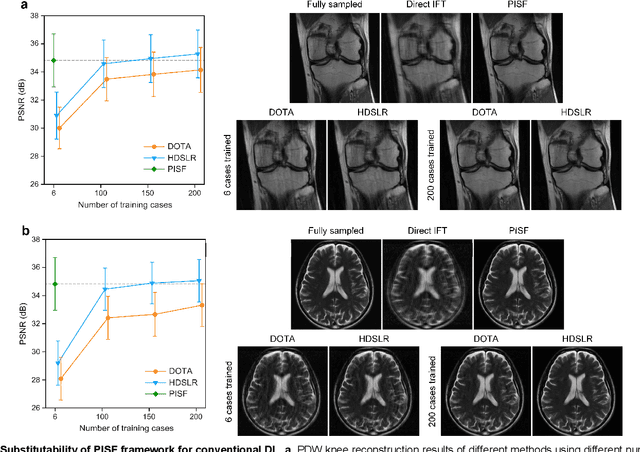
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.
Transfer Learning Enhanced Generative Adversarial Networks for Multi-Channel MRI Reconstruction
May 17, 2021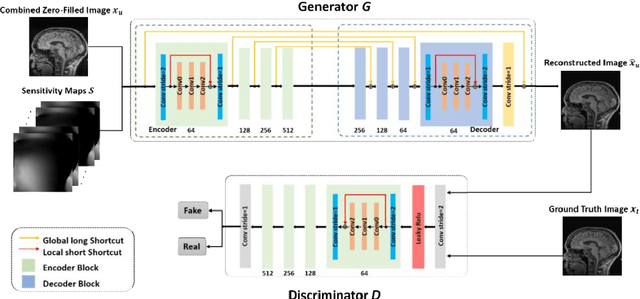
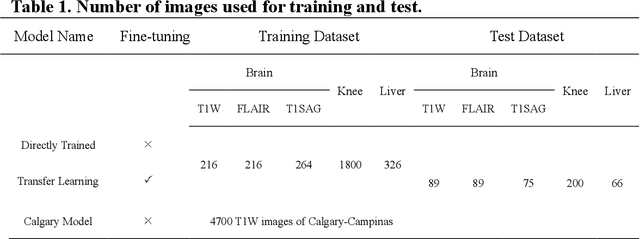
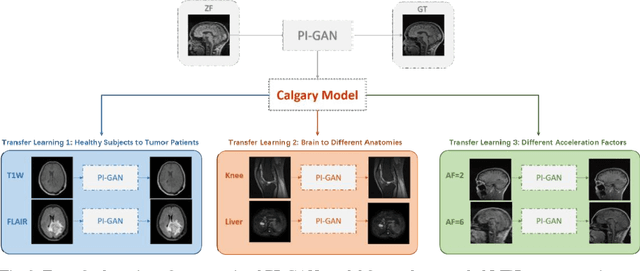
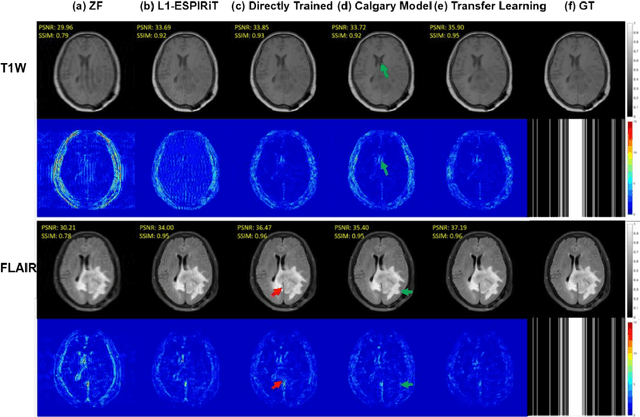
Deep learning based generative adversarial networks (GAN) can effectively perform image reconstruction with under-sampled MR data. In general, a large number of training samples are required to improve the reconstruction performance of a certain model. However, in real clinical applications, it is difficult to obtain tens of thousands of raw patient data to train the model since saving k-space data is not in the routine clinical flow. Therefore, enhancing the generalizability of a network based on small samples is urgently needed. In this study, three novel applications were explored based on parallel imaging combined with the GAN model (PI-GAN) and transfer learning. The model was pre-trained with public Calgary brain images and then fine-tuned for use in (1) patients with tumors in our center; (2) different anatomies, including knee and liver; (3) different k-space sampling masks with acceleration factors (AFs) of 2 and 6. As for the brain tumor dataset, the transfer learning results could remove the artifacts found in PI-GAN and yield smoother brain edges. The transfer learning results for the knee and liver were superior to those of the PI-GAN model trained with its own dataset using a smaller number of training cases. However, the learning procedure converged more slowly in the knee datasets compared to the learning in the brain tumor datasets. The reconstruction performance was improved by transfer learning both in the models with AFs of 2 and 6. Of these two models, the one with AF=2 showed better results. The results also showed that transfer learning with the pre-trained model could solve the problem of inconsistency between the training and test datasets and facilitate generalization to unseen data.