 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHQC-NBV: A Hybrid Quantum-Classical View Planning Approach
May 08, 2025Efficient view planning is a fundamental challenge in computer vision and robotic perception, critical for tasks ranging from search and rescue operations to autonomous navigation. While classical approaches, including sampling-based and deterministic methods, have shown promise in planning camera viewpoints for scene exploration, they often struggle with computational scalability and solution optimality in complex settings. This study introduces HQC-NBV, a hybrid quantum-classical framework for view planning that leverages quantum properties to efficiently explore the parameter space while maintaining robustness and scalability. We propose a specific Hamiltonian formulation with multi-component cost terms and a parameter-centric variational ansatz with bidirectional alternating entanglement patterns that capture the hierarchical dependencies between viewpoint parameters. Comprehensive experiments demonstrate that quantum-specific components provide measurable performance advantages. Compared to the classical methods, our approach achieves up to 49.2% higher exploration efficiency across diverse environments. Our analysis of entanglement architecture and coherence-preserving terms provides insights into the mechanisms of quantum advantage in robotic exploration tasks. This work represents a significant advancement in integrating quantum computing into robotic perception systems, offering a paradigm-shifting solution for various robot vision tasks.
Semantic-aware Next-Best-View for Multi-DoFs Mobile System in Search-and-Acquisition based Visual Perception
Apr 25, 2024Efficient visual perception using mobile systems is crucial, particularly in unknown environments such as search and rescue operations, where swift and comprehensive perception of objects of interest is essential. In such real-world applications, objects of interest are often situated in complex environments, making the selection of the 'Next Best' view based solely on maximizing visibility gain suboptimal. Semantics, providing a higher-level interpretation of perception, should significantly contribute to the selection of the next viewpoint for various perception tasks. In this study, we formulate a novel information gain that integrates both visibility gain and semantic gain in a unified form to select the semantic-aware Next-Best-View. Additionally, we design an adaptive strategy with termination criterion to support a two-stage search-and-acquisition manoeuvre on multiple objects of interest aided by a multi-degree-of-freedoms (Multi-DoFs) mobile system. Several semantically relevant reconstruction metrics, including perspective directivity and region of interest (ROI)-to-full reconstruction volume ratio, are introduced to evaluate the performance of the proposed approach. Simulation experiments demonstrate the advantages of the proposed approach over existing methods, achieving improvements of up to 27.13% for the ROI-to-full reconstruction volume ratio and a 0.88234 average perspective directivity. Furthermore, the planned motion trajectory exhibits better perceiving coverage toward the target.
CSDNet: Detect Salient Object in Depth-Thermal via A Lightweight Cross Shallow and Deep Perception Network
Mar 15, 2024While we enjoy the richness and informativeness of multimodal data, it also introduces interference and redundancy of information. To achieve optimal domain interpretation with limited resources, we propose CSDNet, a lightweight \textbf{C}ross \textbf{S}hallow and \textbf{D}eep Perception \textbf{Net}work designed to integrate two modalities with less coherence, thereby discarding redundant information or even modality. We implement our CSDNet for Salient Object Detection (SOD) task in robotic perception. The proposed method capitalises on spatial information prescreening and implicit coherence navigation across shallow and deep layers of the depth-thermal (D-T) modality, prioritising integration over fusion to maximise the scene interpretation. To further refine the descriptive capabilities of the encoder for the less-known D-T modalities, we also propose SAMAEP to guide an effective feature mapping to the generalised feature space. Our approach is tested on the VDT-2048 dataset, leveraging the D-T modality outperforms those of SOTA methods using RGB-T or RGB-D modalities for the first time, achieves comparable performance with the RGB-D-T triple-modality benchmark method with 5.97 times faster at runtime and demanding 0.0036 times fewer FLOPs. Demonstrates the proposed CSDNet effectively integrates the information from the D-T modality. The code will be released upon acceptance.
CMRxRecon: An open cardiac MRI dataset for the competition of accelerated image reconstruction
Sep 19, 2023



Cardiac magnetic resonance imaging (CMR) has emerged as a valuable diagnostic tool for cardiac diseases. However, a limitation of CMR is its slow imaging speed, which causes patient discomfort and introduces artifacts in the images. There has been growing interest in deep learning-based CMR imaging algorithms that can reconstruct high-quality images from highly under-sampled k-space data. However, the development of deep learning methods requires large training datasets, which have not been publicly available for CMR. To address this gap, we released a dataset that includes multi-contrast, multi-view, multi-slice and multi-coil CMR imaging data from 300 subjects. Imaging studies include cardiac cine and mapping sequences. Manual segmentations of the myocardium and chambers of all the subjects are also provided within the dataset. Scripts of state-of-the-art reconstruction algorithms were also provided as a point of reference. Our aim is to facilitate the advancement of state-of-the-art CMR image reconstruction by introducing standardized evaluation criteria and making the dataset freely accessible to the research community. Researchers can access the dataset at https://www.synapse.org/#!Synapse:syn51471091/wiki/.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023
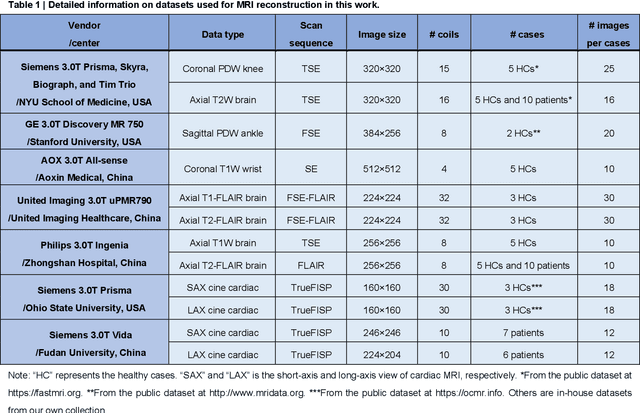
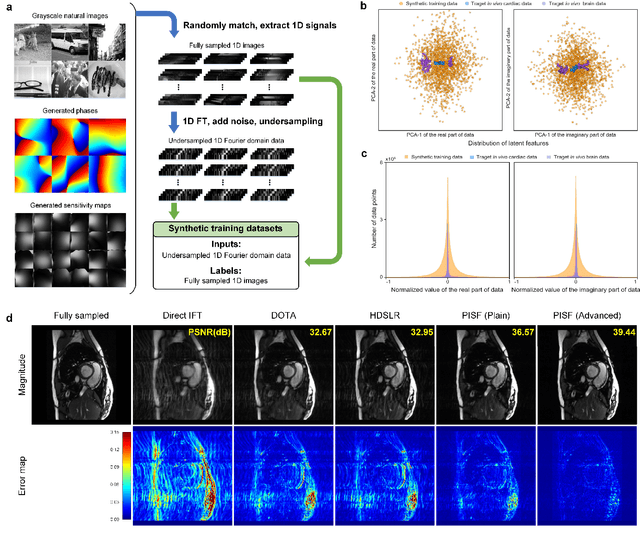
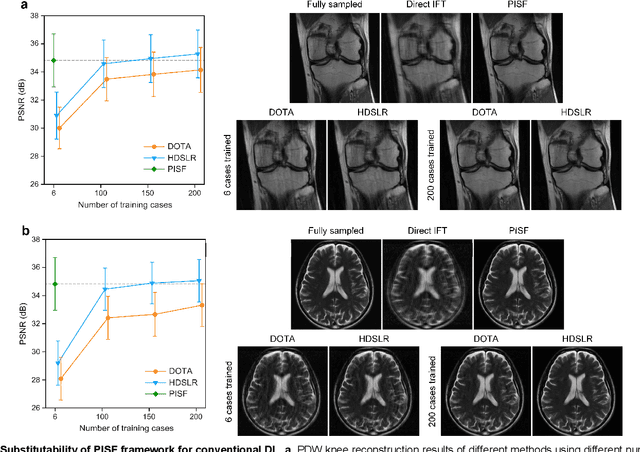
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.
Convex Dual Theory Analysis of Two-Layer Convolutional Neural Networks with Soft-Thresholding
Apr 14, 2023



Soft-thresholding has been widely used in neural networks. Its basic network structure is a two-layer convolution neural network with soft-thresholding. Due to the network's nature of nonlinearity and nonconvexity, the training process heavily depends on an appropriate initialization of network parameters, resulting in the difficulty of obtaining a globally optimal solution. To address this issue, a convex dual network is designed here. We theoretically analyze the network convexity and numerically confirm that the strong duality holds. This conclusion is further verified in the linear fitting and denoising experiments. This work provides a new way to convexify soft-thresholding neural networks.