 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSDNet: Detect Salient Object in Depth-Thermal via A Lightweight Cross Shallow and Deep Perception Network
Mar 15, 2024While we enjoy the richness and informativeness of multimodal data, it also introduces interference and redundancy of information. To achieve optimal domain interpretation with limited resources, we propose CSDNet, a lightweight \textbf{C}ross \textbf{S}hallow and \textbf{D}eep Perception \textbf{Net}work designed to integrate two modalities with less coherence, thereby discarding redundant information or even modality. We implement our CSDNet for Salient Object Detection (SOD) task in robotic perception. The proposed method capitalises on spatial information prescreening and implicit coherence navigation across shallow and deep layers of the depth-thermal (D-T) modality, prioritising integration over fusion to maximise the scene interpretation. To further refine the descriptive capabilities of the encoder for the less-known D-T modalities, we also propose SAMAEP to guide an effective feature mapping to the generalised feature space. Our approach is tested on the VDT-2048 dataset, leveraging the D-T modality outperforms those of SOTA methods using RGB-T or RGB-D modalities for the first time, achieves comparable performance with the RGB-D-T triple-modality benchmark method with 5.97 times faster at runtime and demanding 0.0036 times fewer FLOPs. Demonstrates the proposed CSDNet effectively integrates the information from the D-T modality. The code will be released upon acceptance.
Miriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Jul 10, 2023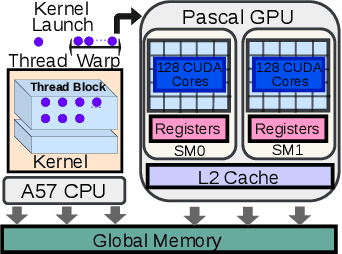

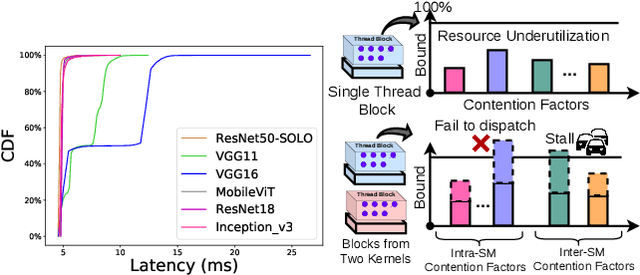

Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.
Deep Learning-enabled Spatial Phase Unwrapping for 3D Measurement
Aug 06, 2022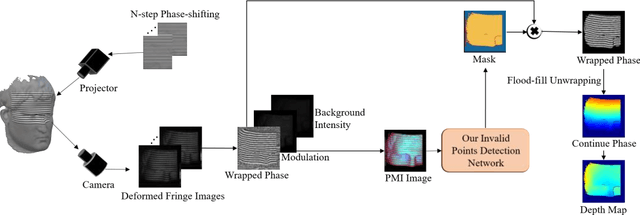

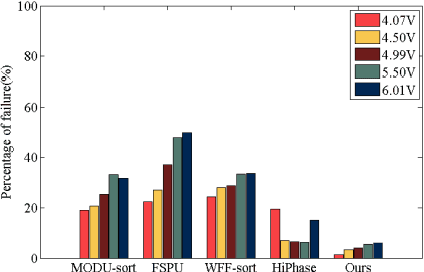
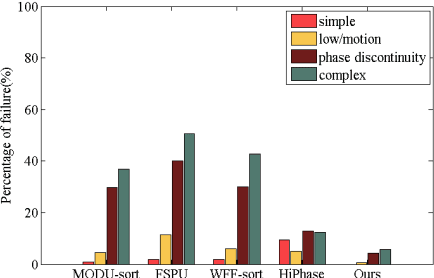
In terms of 3D imaging speed and system cost, the single-camera system projecting single-frequency patterns is the ideal option among all proposed Fringe Projection Profilometry (FPP) systems. This system necessitates a robust spatial phase unwrapping (SPU) algorithm. However, robust SPU remains a challenge in complex scenes. Quality-guided SPU algorithms need more efficient ways to identify the unreliable points in phase maps before unwrapping. End-to-end deep learning SPU methods face generality and interpretability problems. This paper proposes a hybrid method combining deep learning and traditional path-following for robust SPU in FPP. This hybrid SPU scheme demonstrates better robustness than traditional quality-guided SPU methods, better interpretability than end-to-end deep learning scheme, and generality on unseen data. Experiments on the real dataset of multiple illumination conditions and multiple FPP systems differing in image resolution, the number of fringes, fringe direction, and optics wavelength verify the effectiveness of the proposed method.
AI-enabled Automatic Multimodal Fusion of Cone-Beam CT and Intraoral Scans for Intelligent 3D Tooth-Bone Reconstruction and Clinical Applications
Mar 11, 2022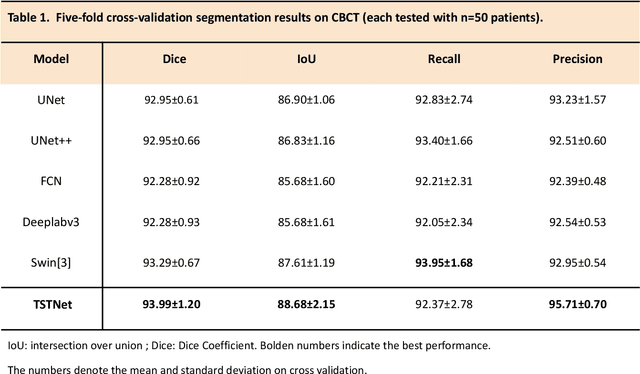
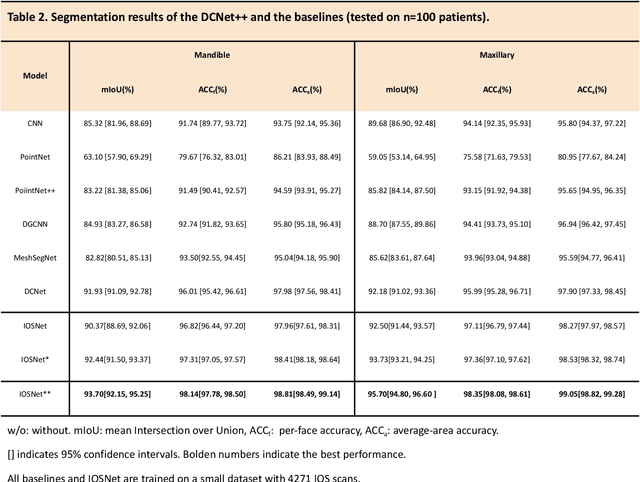

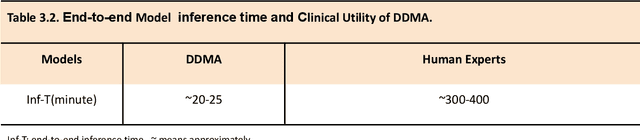
A critical step in virtual dental treatment planning is to accurately delineate all tooth-bone structures from CBCT with high fidelity and accurate anatomical information. Previous studies have established several methods for CBCT segmentation using deep learning. However, the inherent resolution discrepancy of CBCT and the loss of occlusal and dentition information largely limited its clinical applicability. Here, we present a Deep Dental Multimodal Analysis (DDMA) framework consisting of a CBCT segmentation model, an intraoral scan (IOS) segmentation model (the most accurate digital dental model), and a fusion model to generate 3D fused crown-root-bone structures with high fidelity and accurate occlusal and dentition information. Our model was trained with a large-scale dataset with 503 CBCT and 28,559 IOS meshes manually annotated by experienced human experts. For CBCT segmentation, we use a five-fold cross validation test, each with 50 CBCT, and our model achieves an average Dice coefficient and IoU of 93.99% and 88.68%, respectively, significantly outperforming the baselines. For IOS segmentations, our model achieves an mIoU of 93.07% and 95.70% on the maxillary and mandible on a test set of 200 IOS meshes, which are 1.77% and 3.52% higher than the state-of-art method. Our DDMA framework takes about 20 to 25 minutes to generate the fused 3D mesh model following the sequential processing order, compared to over 5 hours by human experts. Notably, our framework has been incorporated into a software by a clear aligner manufacturer, and real-world clinical cases demonstrate that our model can visualize crown-root-bone structures during the entire orthodontic treatment and can predict risks like dehiscence and fenestration. These findings demonstrate the potential of multi-modal deep learning to improve the quality of digital dental models and help dentists make better clinical decisions.
Moses: Efficient Exploitation of Cross-device Transferable Features for Tensor Program Optimization
Jan 15, 2022
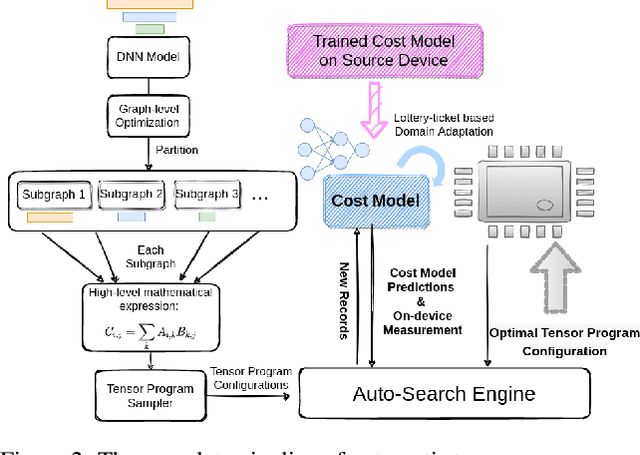
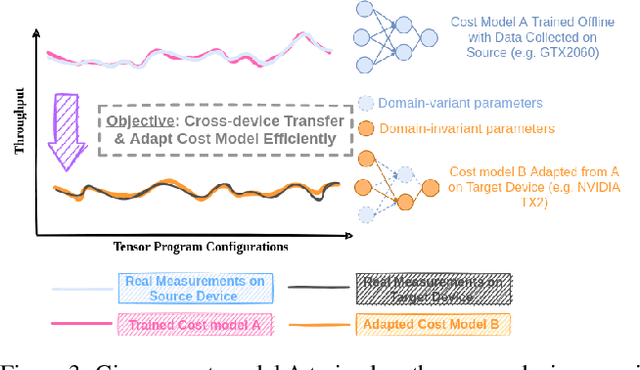
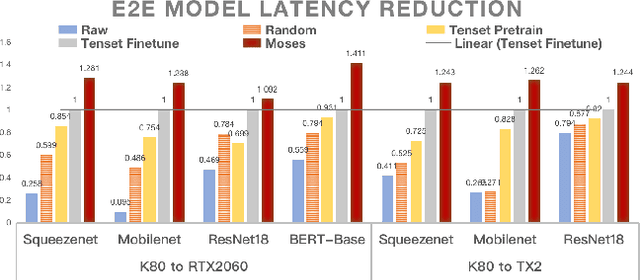
Achieving efficient execution of machine learning models has attracted significant attention recently. To generate tensor programs efficiently, a key component of DNN compilers is the cost model that can predict the performance of each configuration on specific devices. However, due to the rapid emergence of hardware platforms, it is increasingly labor-intensive to train domain-specific predictors for every new platform. Besides, current design of cost models cannot provide transferable features between different hardware accelerators efficiently and effectively. In this paper, we propose Moses, a simple and efficient design based on the lottery ticket hypothesis, which fully takes advantage of the features transferable to the target device via domain adaptation. Compared with state-of-the-art approaches, Moses achieves up to 1.53X efficiency gain in the search stage and 1.41X inference speedup on challenging DNN benchmarks.