 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Contrastive Learning and Masked Image Modeling for Scene Text Recognition
Nov 19, 2024



Context-aware methods have achieved remarkable advancements in supervised scene text recognition by leveraging semantic priors from words. Considering the heterogeneity of text and background in STR, we propose that such contextual priors can be reinterpreted as the relations between textual elements, serving as effective self-supervised labels for representation learning. However, textual relations are restricted to the finite size of the dataset due to lexical dependencies, which causes over-fitting problem, thus compromising the representation quality. To address this, our work introduces a unified framework of Relational Contrastive Learning and Masked Image Modeling for STR (RCMSTR), which explicitly models the enriched textual relations. For the RCL branch, we first introduce the relational rearrangement module to cultivate new relations on the fly. Based on this, we further conduct relational contrastive learning to model the intra- and inter-hierarchical relations for frames, sub-words and words. On the other hand, MIM can naturally boost the context information via masking, where we find that the block masking strategy is more effective for STR. For the effective integration of RCL and MIM, we also introduce a novel decoupling design aimed at mitigating the impact of masked images on contrastive learning. Additionally, to enhance the compatibility of MIM with CNNs, we propose the adoption of sparse convolutions and directly sharing the weights with dense convolutions in training. The proposed RCMSTR demonstrates superior performance in various evaluation protocols for different STR-related downstream tasks, outperforming the existing state-of-the-art self-supervised STR techniques. Ablation studies and qualitative experimental results further validate the effectiveness of our method. The code and pre-trained models will be available at https://github.com/ThunderVVV/RCMSTR .
Semantic-aware Next-Best-View for Multi-DoFs Mobile System in Search-and-Acquisition based Visual Perception
Apr 25, 2024Efficient visual perception using mobile systems is crucial, particularly in unknown environments such as search and rescue operations, where swift and comprehensive perception of objects of interest is essential. In such real-world applications, objects of interest are often situated in complex environments, making the selection of the 'Next Best' view based solely on maximizing visibility gain suboptimal. Semantics, providing a higher-level interpretation of perception, should significantly contribute to the selection of the next viewpoint for various perception tasks. In this study, we formulate a novel information gain that integrates both visibility gain and semantic gain in a unified form to select the semantic-aware Next-Best-View. Additionally, we design an adaptive strategy with termination criterion to support a two-stage search-and-acquisition manoeuvre on multiple objects of interest aided by a multi-degree-of-freedoms (Multi-DoFs) mobile system. Several semantically relevant reconstruction metrics, including perspective directivity and region of interest (ROI)-to-full reconstruction volume ratio, are introduced to evaluate the performance of the proposed approach. Simulation experiments demonstrate the advantages of the proposed approach over existing methods, achieving improvements of up to 27.13% for the ROI-to-full reconstruction volume ratio and a 0.88234 average perspective directivity. Furthermore, the planned motion trajectory exhibits better perceiving coverage toward the target.
CSDNet: Detect Salient Object in Depth-Thermal via A Lightweight Cross Shallow and Deep Perception Network
Mar 15, 2024While we enjoy the richness and informativeness of multimodal data, it also introduces interference and redundancy of information. To achieve optimal domain interpretation with limited resources, we propose CSDNet, a lightweight \textbf{C}ross \textbf{S}hallow and \textbf{D}eep Perception \textbf{Net}work designed to integrate two modalities with less coherence, thereby discarding redundant information or even modality. We implement our CSDNet for Salient Object Detection (SOD) task in robotic perception. The proposed method capitalises on spatial information prescreening and implicit coherence navigation across shallow and deep layers of the depth-thermal (D-T) modality, prioritising integration over fusion to maximise the scene interpretation. To further refine the descriptive capabilities of the encoder for the less-known D-T modalities, we also propose SAMAEP to guide an effective feature mapping to the generalised feature space. Our approach is tested on the VDT-2048 dataset, leveraging the D-T modality outperforms those of SOTA methods using RGB-T or RGB-D modalities for the first time, achieves comparable performance with the RGB-D-T triple-modality benchmark method with 5.97 times faster at runtime and demanding 0.0036 times fewer FLOPs. Demonstrates the proposed CSDNet effectively integrates the information from the D-T modality. The code will be released upon acceptance.
Prompt-Matched Semantic Segmentation
Aug 22, 2022
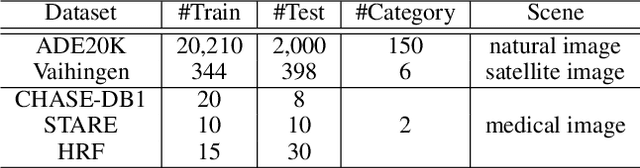
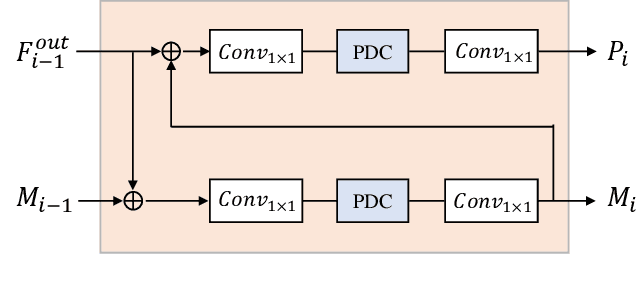
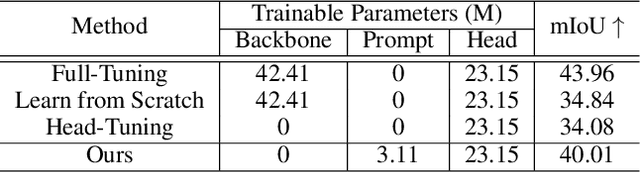
The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.
Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection
Jun 13, 2022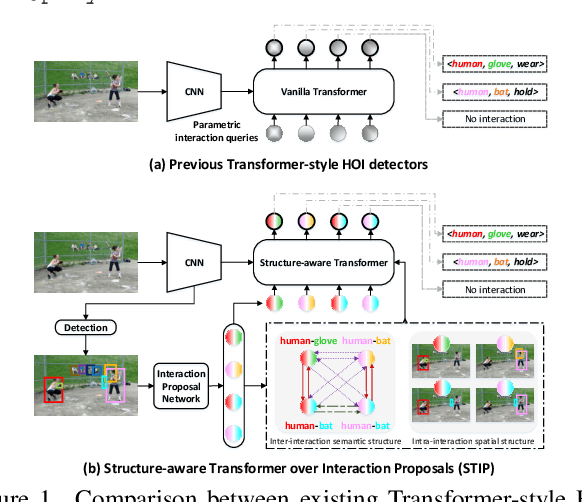
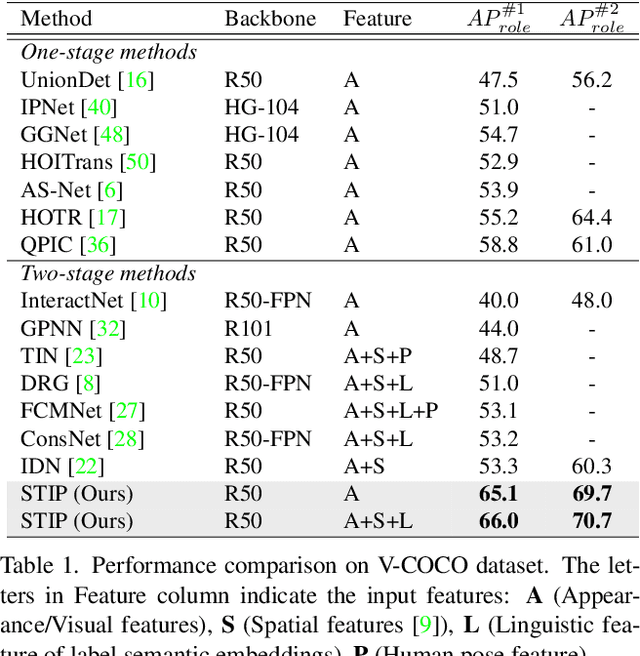
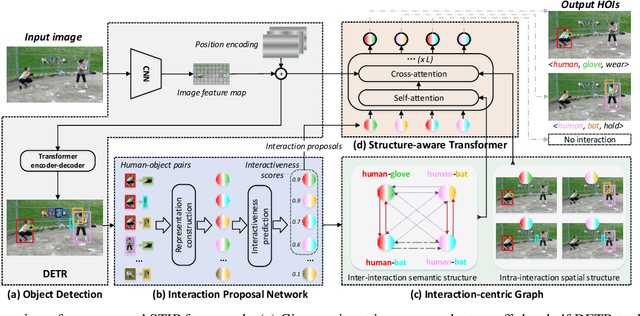
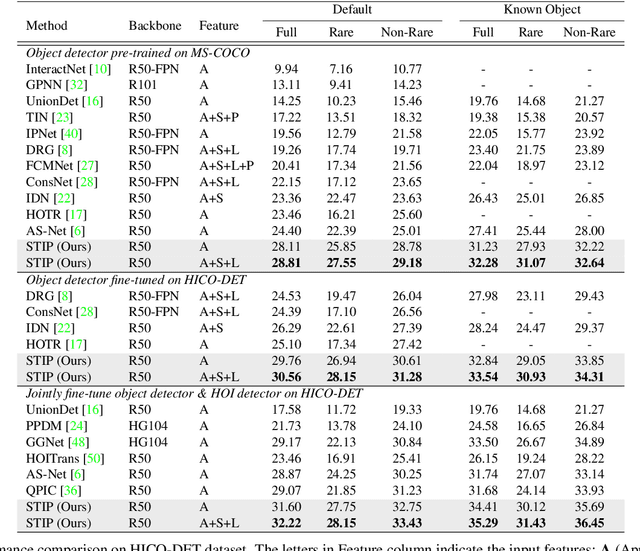
Recent high-performing Human-Object Interaction (HOI) detection techniques have been highly influenced by Transformer-based object detector (i.e., DETR). Nevertheless, most of them directly map parametric interaction queries into a set of HOI predictions through vanilla Transformer in a one-stage manner. This leaves rich inter- or intra-interaction structure under-exploited. In this work, we design a novel Transformer-style HOI detector, i.e., Structure-aware Transformer over Interaction Proposals (STIP), for HOI detection. Such design decomposes the process of HOI set prediction into two subsequent phases, i.e., an interaction proposal generation is first performed, and then followed by transforming the non-parametric interaction proposals into HOI predictions via a structure-aware Transformer. The structure-aware Transformer upgrades vanilla Transformer by encoding additionally the holistically semantic structure among interaction proposals as well as the locally spatial structure of human/object within each interaction proposal, so as to strengthen HOI predictions. Extensive experiments conducted on V-COCO and HICO-DET benchmarks have demonstrated the effectiveness of STIP, and superior results are reported when comparing with the state-of-the-art HOI detectors. Source code is available at \url{https://github.com/zyong812/STIP}.