 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Matched Semantic Segmentation
Paper and Code
Aug 22, 2022
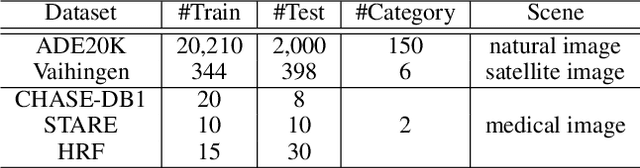
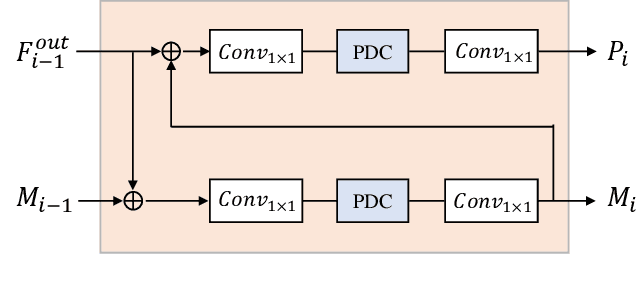
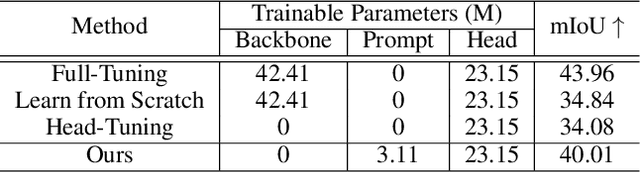
The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.