 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompLex: Music Theory Lexicon Constructed by Autonomous Agents for Automatic Music Generation
Aug 27, 2025Generative artificial intelligence in music has made significant strides, yet it still falls short of the substantial achievements seen in natural language processing, primarily due to the limited availability of music data. Knowledge-informed approaches have been shown to enhance the performance of music generation models, even when only a few pieces of musical knowledge are integrated. This paper seeks to leverage comprehensive music theory in AI-driven music generation tasks, such as algorithmic composition and style transfer, which traditionally require significant manual effort with existing techniques. We introduce a novel automatic music lexicon construction model that generates a lexicon, named CompLex, comprising 37,432 items derived from just 9 manually input category keywords and 5 sentence prompt templates. A new multi-agent algorithm is proposed to automatically detect and mitigate hallucinations. CompLex demonstrates impressive performance improvements across three state-of-the-art text-to-music generation models, encompassing both symbolic and audio-based methods. Furthermore, we evaluate CompLex in terms of completeness, accuracy, non-redundancy, and executability, confirming that it possesses the key characteristics of an effective lexicon.
GLA-GCN: Global-local Adaptive Graph Convolutional Network for 3D Human Pose Estimation from Monocular Video
Jul 22, 2023



3D human pose estimation has been researched for decades with promising fruits. 3D human pose lifting is one of the promising research directions toward the task where both estimated pose and ground truth pose data are used for training. Existing pose lifting works mainly focus on improving the performance of estimated pose, but they usually underperform when testing on the ground truth pose data. We observe that the performance of the estimated pose can be easily improved by preparing good quality 2D pose, such as fine-tuning the 2D pose or using advanced 2D pose detectors. As such, we concentrate on improving the 3D human pose lifting via ground truth data for the future improvement of more quality estimated pose data. Towards this goal, a simple yet effective model called Global-local Adaptive Graph Convolutional Network (GLA-GCN) is proposed in this work. Our GLA-GCN globally models the spatiotemporal structure via a graph representation and backtraces local joint features for 3D human pose estimation via individually connected layers. To validate our model design, we conduct extensive experiments on three benchmark datasets: Human3.6M, HumanEva-I, and MPI-INF-3DHP. Experimental results show that our GLA-GCN implemented with ground truth 2D poses significantly outperforms state-of-the-art methods (e.g., up to around 3%, 17%, and 14% error reductions on Human3.6M, HumanEva-I, and MPI-INF-3DHP, respectively). GitHub: https://github.com/bruceyo/GLA-GCN.
Visual Tuning
May 10, 2023Fine-tuning visual models has been widely shown promising performance on many downstream visual tasks. With the surprising development of pre-trained visual foundation models, visual tuning jumped out of the standard modus operandi that fine-tunes the whole pre-trained model or just the fully connected layer. Instead, recent advances can achieve superior performance than full-tuning the whole pre-trained parameters by updating far fewer parameters, enabling edge devices and downstream applications to reuse the increasingly large foundation models deployed on the cloud. With the aim of helping researchers get the full picture and future directions of visual tuning, this survey characterizes a large and thoughtful selection of recent works, providing a systematic and comprehensive overview of existing work and models. Specifically, it provides a detailed background of visual tuning and categorizes recent visual tuning techniques into five groups: prompt tuning, adapter tuning, parameter tuning, and remapping tuning. Meanwhile, it offers some exciting research directions for prospective pre-training and various interactions in visual tuning.
Towards a Unified View on Visual Parameter-Efficient Transfer Learning
Oct 03, 2022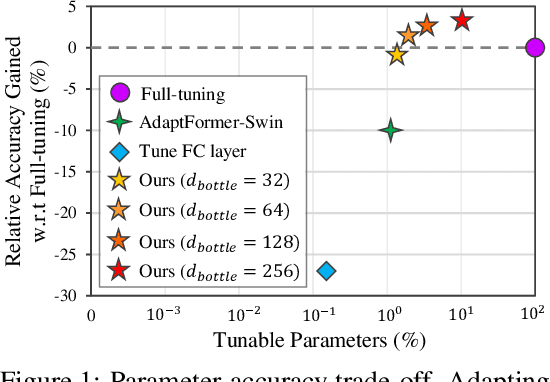
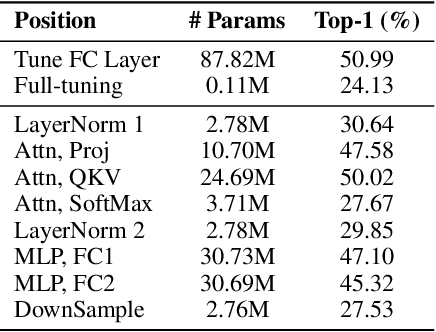
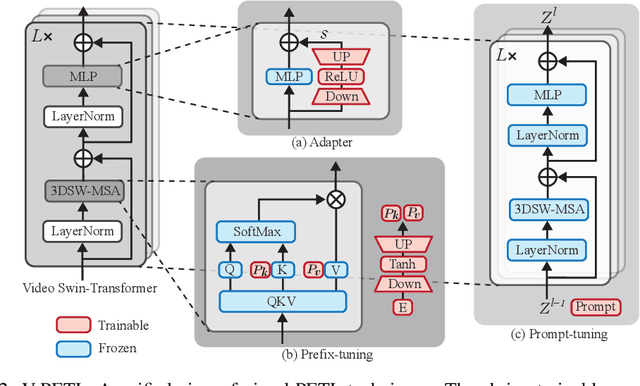
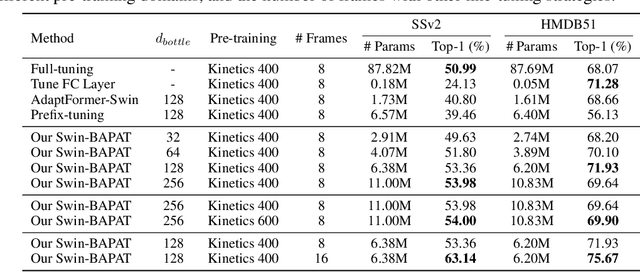
Since the release of various large-scale natural language processing (NLP) pre-trained models, parameter efficient transfer learning (PETL) has become a popular paradigm capable of achieving impressive performance on various downstream tasks. PETL aims at making good use of the representation knowledge in the pre-trained large models by fine-tuning a small number of parameters. Recently, it has also attracted increasing attention to developing various PETL techniques for vision tasks. Popular PETL techniques such as Prompt-tuning and Adapter have been proposed for high-level visual downstream tasks such as image classification and video recognition. However, Prefix-tuning remains under-explored for vision tasks. In this work, we intend to adapt large video-based models to downstream tasks with a good parameter-accuracy trade-off. Towards this goal, we propose a framework with a unified view called visual-PETL (V-PETL) to investigate the different aspects affecting the trade-off. Specifically, we analyze the positional importance of trainable parameters and differences between NLP and vision tasks in terms of data structures and pre-training mechanisms while implementing various PETL techniques, especially for the under-explored prefix-tuning technique. Based on a comprehensive understanding of differences between NLP and video data, we propose a new variation of prefix-tuning module called parallel attention (PATT) for video-based downstream tasks. An extensive empirical analysis on two video datasets via different frozen backbones has been carried and the findings show that the proposed PATT can effectively contribute to other PETL techniques. An effective scheme Swin-BAPAT derived from the proposed V-PETL framework achieves significantly better performance than the state-of-the-art AdaptFormer-Swin with slightly more parameters and outperforms full-tuning with far less parameters.
Prompt-Matched Semantic Segmentation
Aug 22, 2022
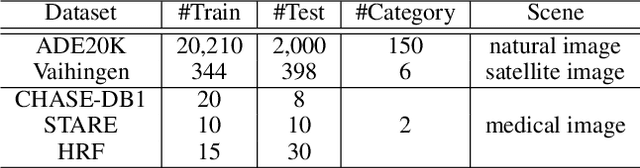
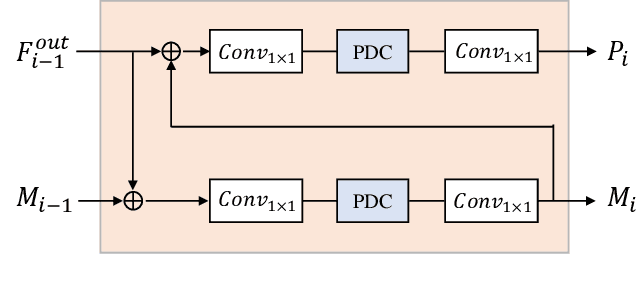
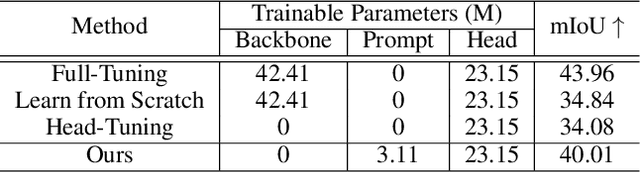
The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.
Skeleton Focused Human Activity Recognition in RGB Video
Apr 29, 2020
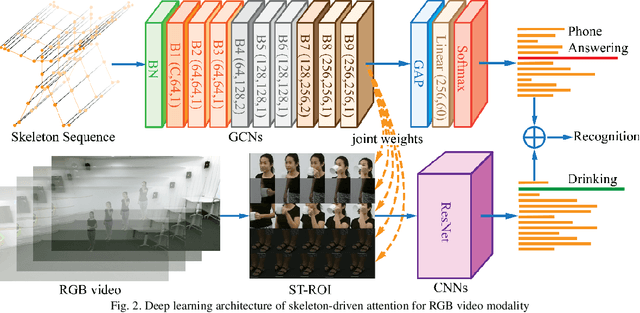
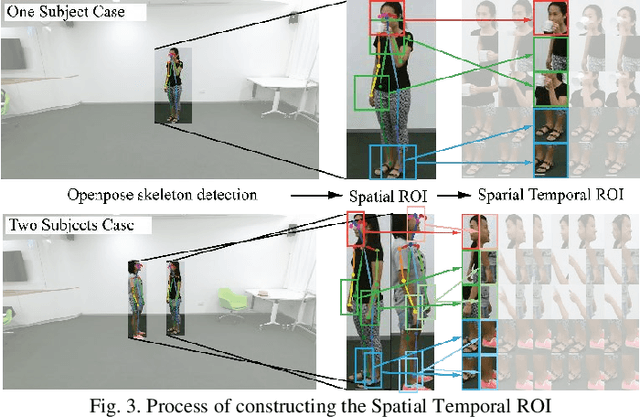

The data-driven approach that learns an optimal representation of vision features like skeleton frames or RGB videos is currently a dominant paradigm for activity recognition. While great improvements have been achieved from existing single modal approaches with increasingly larger datasets, the fusion of various data modalities at the feature level has seldom been attempted. In this paper, we propose a multimodal feature fusion model that utilizes both skeleton and RGB modalities to infer human activity. The objective is to improve the activity recognition accuracy by effectively utilizing the mutual complemental information among different data modalities. For the skeleton modality, we propose to use a graph convolutional subnetwork to learn the skeleton representation. Whereas for the RGB modality, we will use the spatial-temporal region of interest from RGB videos and take the attention features from the skeleton modality to guide the learning process. The model could be either individually or uniformly trained by the back-propagation algorithm in an end-to-end manner. The experimental results for the NTU-RGB+D and Northwestern-UCLA Multiview datasets achieved state-of-the-art performance, which indicates that the proposed skeleton-driven attention mechanism for the RGB modality increases the mutual communication between different data modalities and brings more discriminative features for inferring human activities.
Effective Human Activity Recognition Based on Small Datasets
Apr 29, 2020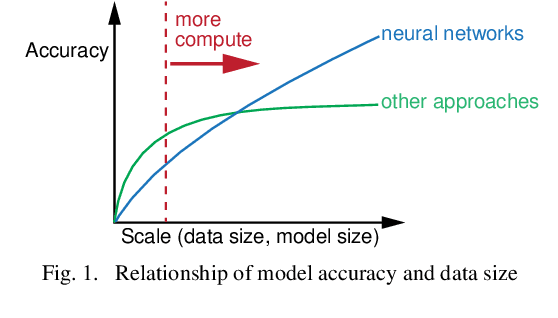
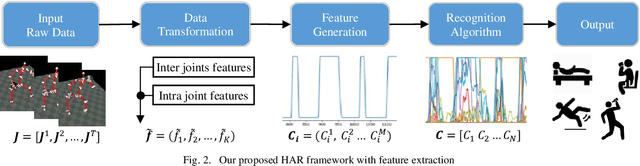
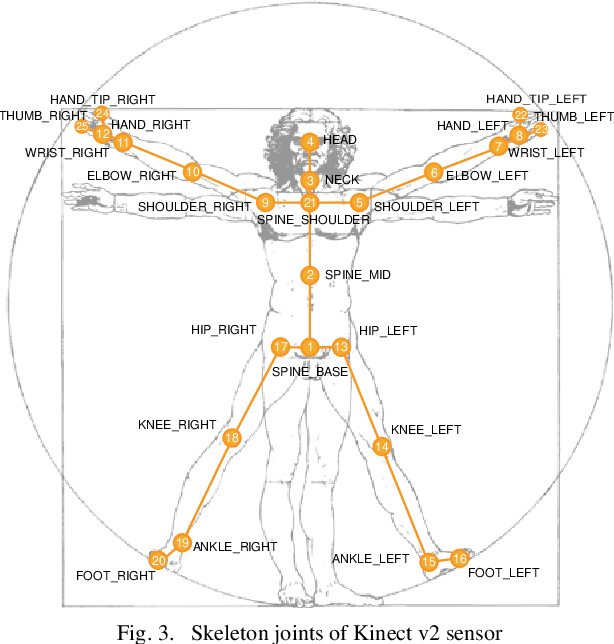
Most recent work on vision-based human activity recognition (HAR) focuses on designing complex deep learning models for the task. In so doing, there is a requirement for large datasets to be collected. As acquiring and processing large training datasets are usually very expensive, the problem of how dataset size can be reduced without affecting recognition accuracy has to be tackled. To do so, we propose a HAR method that consists of three steps: (i) data transformation involving the generation of new features based on transforming of raw data, (ii) feature extraction involving the learning of a classifier based on the AdaBoost algorithm and the use of training data consisting of the transformed features, and (iii) parameter determination and pattern recognition involving the determination of parameters based on the features generated in (ii) and the use of the parameters as training data for deep learning algorithms to be used to recognize human activities. Compared to existing approaches, this proposed approach has the advantageous characteristics that it is simple and robust. The proposed approach has been tested with a number of experiments performed on a relatively small real dataset. The experimental results indicate that using the proposed method, human activities can be more accurately recognized even with smaller training data size.