 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton Focused Human Activity Recognition in RGB Video
Apr 29, 2020
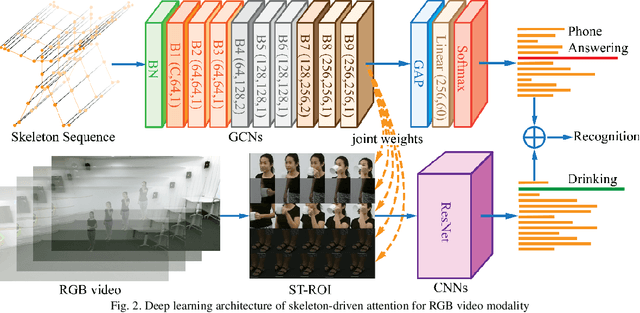
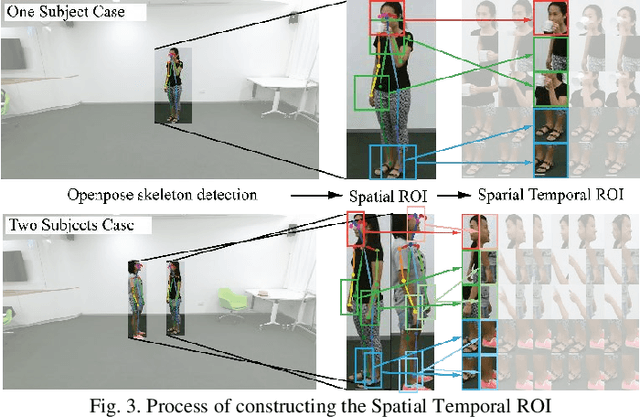

The data-driven approach that learns an optimal representation of vision features like skeleton frames or RGB videos is currently a dominant paradigm for activity recognition. While great improvements have been achieved from existing single modal approaches with increasingly larger datasets, the fusion of various data modalities at the feature level has seldom been attempted. In this paper, we propose a multimodal feature fusion model that utilizes both skeleton and RGB modalities to infer human activity. The objective is to improve the activity recognition accuracy by effectively utilizing the mutual complemental information among different data modalities. For the skeleton modality, we propose to use a graph convolutional subnetwork to learn the skeleton representation. Whereas for the RGB modality, we will use the spatial-temporal region of interest from RGB videos and take the attention features from the skeleton modality to guide the learning process. The model could be either individually or uniformly trained by the back-propagation algorithm in an end-to-end manner. The experimental results for the NTU-RGB+D and Northwestern-UCLA Multiview datasets achieved state-of-the-art performance, which indicates that the proposed skeleton-driven attention mechanism for the RGB modality increases the mutual communication between different data modalities and brings more discriminative features for inferring human activities.
Effective Human Activity Recognition Based on Small Datasets
Apr 29, 2020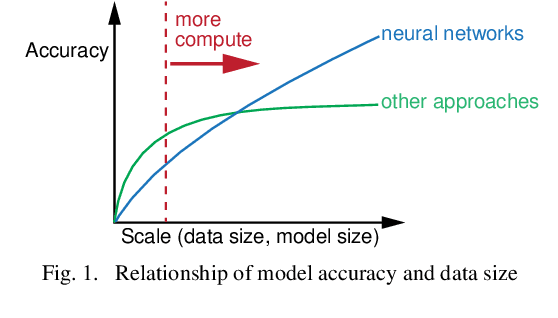
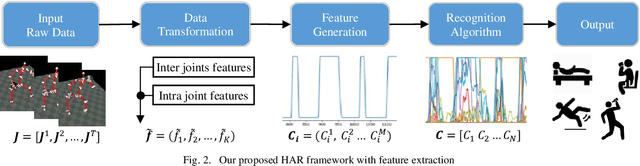
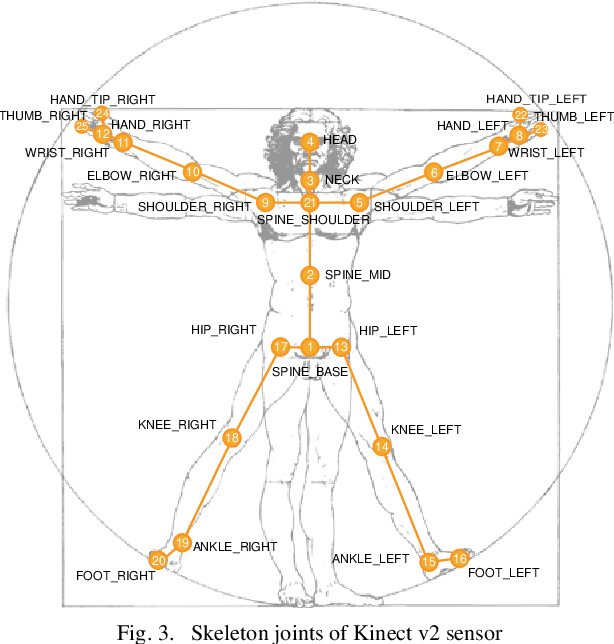
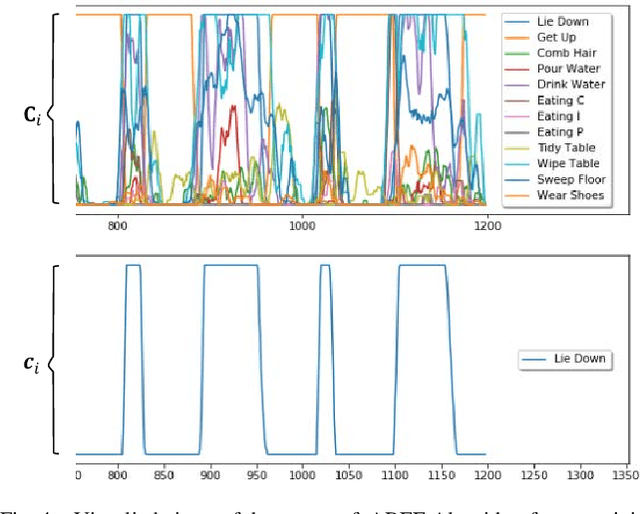
Most recent work on vision-based human activity recognition (HAR) focuses on designing complex deep learning models for the task. In so doing, there is a requirement for large datasets to be collected. As acquiring and processing large training datasets are usually very expensive, the problem of how dataset size can be reduced without affecting recognition accuracy has to be tackled. To do so, we propose a HAR method that consists of three steps: (i) data transformation involving the generation of new features based on transforming of raw data, (ii) feature extraction involving the learning of a classifier based on the AdaBoost algorithm and the use of training data consisting of the transformed features, and (iii) parameter determination and pattern recognition involving the determination of parameters based on the features generated in (ii) and the use of the parameters as training data for deep learning algorithms to be used to recognize human activities. Compared to existing approaches, this proposed approach has the advantageous characteristics that it is simple and robust. The proposed approach has been tested with a number of experiments performed on a relatively small real dataset. The experimental results indicate that using the proposed method, human activities can be more accurately recognized even with smaller training data size.