 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Syn-to-Real IQA: A Novel Perspective on Reshaping Synthetic Data Distributions
Jan 01, 2026Blind Image Quality Assessment (BIQA) has advanced significantly through deep learning, but the scarcity of large-scale labeled datasets remains a challenge. While synthetic data offers a promising solution, models trained on existing synthetic datasets often show limited generalization ability. In this work, we make a key observation that representations learned from synthetic datasets often exhibit a discrete and clustered pattern that hinders regression performance: features of high-quality images cluster around reference images, while those of low-quality images cluster based on distortion types. Our analysis reveals that this issue stems from the distribution of synthetic data rather than model architecture. Consequently, we introduce a novel framework SynDR-IQA, which reshapes synthetic data distribution to enhance BIQA generalization. Based on theoretical derivations of sample diversity and redundancy's impact on generalization error, SynDR-IQA employs two strategies: distribution-aware diverse content upsampling, which enhances visual diversity while preserving content distribution, and density-aware redundant cluster downsampling, which balances samples by reducing the density of densely clustered areas. Extensive experiments across three cross-dataset settings (synthetic-to-authentic, synthetic-to-algorithmic, and synthetic-to-synthetic) demonstrate the effectiveness of our method. The code is available at https://github.com/Li-aobo/SynDR-IQA.
From Prompt Optimization to Multi-Dimensional Credibility Evaluation: Enhancing Trustworthiness of Chinese LLM-Generated Liver MRI Reports
Oct 27, 2025Large language models (LLMs) have demonstrated promising performance in generating diagnostic conclusions from imaging findings, thereby supporting radiology reporting, trainee education, and quality control. However, systematic guidance on how to optimize prompt design across different clinical contexts remains underexplored. Moreover, a comprehensive and standardized framework for assessing the trustworthiness of LLM-generated radiology reports is yet to be established. This study aims to enhance the trustworthiness of LLM-generated liver MRI reports by introducing a Multi-Dimensional Credibility Assessment (MDCA) framework and providing guidance on institution-specific prompt optimization. The proposed framework is applied to evaluate and compare the performance of several advanced LLMs, including Kimi-K2-Instruct-0905, Qwen3-235B-A22B-Instruct-2507, DeepSeek-V3, and ByteDance-Seed-OSS-36B-Instruct, using the SiliconFlow platform.
A Pilot Empirical Study on When and How to Use Knowledge Graphs as Retrieval Augmented Generation
Feb 28, 2025The integration of Knowledge Graphs (KGs) into the Retrieval Augmented Generation (RAG) framework has attracted significant interest, with early studies showing promise in mitigating hallucinations and improving model accuracy. However, a systematic understanding and comparative analysis of the rapidly emerging KG-RAG methods are still lacking. This paper seeks to lay the foundation for systematically answering the question of when and how to use KG-RAG by analyzing their performance in various application scenarios associated with different technical configurations. After outlining the mind map using KG-RAG framework and summarizing its popular pipeline, we conduct a pilot empirical study of KG-RAG works to reimplement and evaluate 6 KG-RAG methods across 7 datasets in diverse scenarios, analyzing the impact of 9 KG-RAG configurations in combination with 17 LLMs. Our results underscore the critical role of appropriate application conditions and optimal configurations of KG-RAG components.
Histology Virtual Staining with Mask-Guided Adversarial Transfer Learning for Tertiary Lymphoid Structure Detection
Aug 26, 2024Histological Tertiary Lymphoid Structures (TLSs) are increasingly recognized for their correlation with the efficacy of immunotherapy in various solid tumors. Traditionally, the identification and characterization of TLSs rely on immunohistochemistry (IHC) staining techniques, utilizing markers such as CD20 for B cells. Despite the specificity of IHC, Hematoxylin-Eosin (H&E) staining offers a more accessible and cost-effective choice. Capitalizing on the prevalence of H&E staining slides, we introduce a novel Mask-Guided Adversarial Transfer Learning method designed for virtual pathological staining. This method adeptly captures the nuanced color variations across diverse tissue types under various staining conditions, such as nucleus, red blood cells, positive reaction regions, without explicit label information, and adeptly synthesizes realistic IHC-like virtual staining patches, even replicating the positive reaction. Further, we propose the Virtual IHC Pathology Analysis Network (VIPA-Net), an integrated framework encompassing a Mask-Guided Transfer Module and an H&E-Based Virtual Staining TLS Detection Module. VIPA-Net synergistically harnesses both H\&E staining slides and the synthesized virtual IHC patches to enhance the detection of TLSs within H&E Whole Slide Images (WSIs). We evaluate the network with a comprehensive dataset comprising 1019 annotated slides from The Cancer Genome Atlas (TCGA). Experimental results compellingly illustrate that the VIPA-Net substantially elevates TLS detection accuracy, effectively circumventing the need for actual CD20 staining across the public dataset.
Bridging the Synthetic-to-Authentic Gap: Distortion-Guided Unsupervised Domain Adaptation for Blind Image Quality Assessment
May 07, 2024The annotation of blind image quality assessment (BIQA) is labor-intensive and time-consuming, especially for authentic images. Training on synthetic data is expected to be beneficial, but synthetically trained models often suffer from poor generalization in real domains due to domain gaps. In this work, we make a key observation that introducing more distortion types in the synthetic dataset may not improve or even be harmful to generalizing authentic image quality assessment. To solve this challenge, we propose distortion-guided unsupervised domain adaptation for BIQA (DGQA), a novel framework that leverages adaptive multi-domain selection via prior knowledge from distortion to match the data distribution between the source domains and the target domain, thereby reducing negative transfer from the outlier source domains. Extensive experiments on two cross-domain settings (synthetic distortion to authentic distortion and synthetic distortion to algorithmic distortion) have demonstrated the effectiveness of our proposed DGQA. Besides, DGQA is orthogonal to existing model-based BIQA methods, and can be used in combination with such models to improve performance with less training data.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024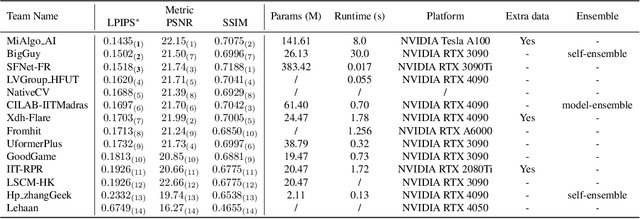
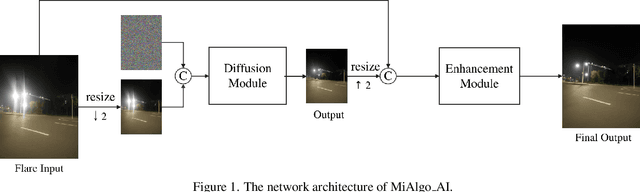
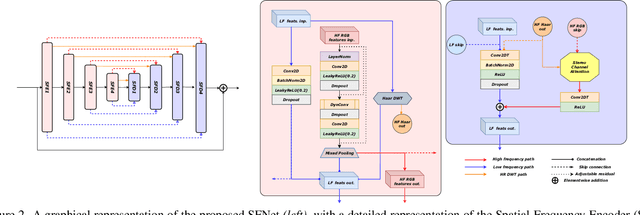
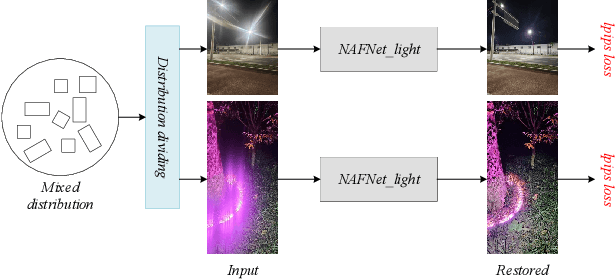
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Scaling and Masking: A New Paradigm of Data Sampling for Image and Video Quality Assessment
Jan 05, 2024



Quality assessment of images and videos emphasizes both local details and global semantics, whereas general data sampling methods (e.g., resizing, cropping or grid-based fragment) fail to catch them simultaneously. To address the deficiency, current approaches have to adopt multi-branch models and take as input the multi-resolution data, which burdens the model complexity. In this work, instead of stacking up models, a more elegant data sampling method (named as SAMA, scaling and masking) is explored, which compacts both the local and global content in a regular input size. The basic idea is to scale the data into a pyramid first, and reduce the pyramid into a regular data dimension with a masking strategy. Benefiting from the spatial and temporal redundancy in images and videos, the processed data maintains the multi-scale characteristics with a regular input size, thus can be processed by a single-branch model. We verify the sampling method in image and video quality assessment. Experiments show that our sampling method can improve the performance of current single-branch models significantly, and achieves competitive performance to the multi-branch models without extra model complexity. The source code will be available at https://github.com/Sissuire/SAMA.
GLA-GCN: Global-local Adaptive Graph Convolutional Network for 3D Human Pose Estimation from Monocular Video
Jul 22, 2023



3D human pose estimation has been researched for decades with promising fruits. 3D human pose lifting is one of the promising research directions toward the task where both estimated pose and ground truth pose data are used for training. Existing pose lifting works mainly focus on improving the performance of estimated pose, but they usually underperform when testing on the ground truth pose data. We observe that the performance of the estimated pose can be easily improved by preparing good quality 2D pose, such as fine-tuning the 2D pose or using advanced 2D pose detectors. As such, we concentrate on improving the 3D human pose lifting via ground truth data for the future improvement of more quality estimated pose data. Towards this goal, a simple yet effective model called Global-local Adaptive Graph Convolutional Network (GLA-GCN) is proposed in this work. Our GLA-GCN globally models the spatiotemporal structure via a graph representation and backtraces local joint features for 3D human pose estimation via individually connected layers. To validate our model design, we conduct extensive experiments on three benchmark datasets: Human3.6M, HumanEva-I, and MPI-INF-3DHP. Experimental results show that our GLA-GCN implemented with ground truth 2D poses significantly outperforms state-of-the-art methods (e.g., up to around 3%, 17%, and 14% error reductions on Human3.6M, HumanEva-I, and MPI-INF-3DHP, respectively). GitHub: https://github.com/bruceyo/GLA-GCN.
Can Machines Generate Personalized Music? A Hybrid Favorite-aware Method for User Preference Music Transfer
Jan 21, 2022



User preference music transfer (UPMT) is a new problem in music style transfer that can be applied to many scenarios but remains understudied.