 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Contrast to Consistency: Rethinking Event-based Continuous-Time Optical Flow Estimation
May 26, 2026Estimating continuous optical flow is a fundamental yet challenging problem in dynamic visual perception. Event-based cameras, with microsecond latency and high dynamic range, capture brightness changes asynchronously, offering a unique opportunity to model motion with fine temporal precision. However, the scarcity of temporally dense ground-truth annotations limits the effectiveness of supervised learning, while contrast maximization (CM) frameworks, focused on sharpening the Image of Warped Events (IWE), often neglect temporal continuity and structural coherence, leading to distorted trajectories under complex motion. To overcome these challenges, we propose a hybrid-supervised framework for continuous-time optical flow estimation, grounded in the principle of Spatio-temporal Structural Consistency (STSC). This paradigm jointly enforces local structural stability and trajectory continuity, ensuring physically coherent motion across time. To further enhance representation and robustness, we design a bidirectionally complementary multi-scale architecture and employ a curriculum-guided hybrid training strategy, enabling a smooth transition from supervised point constraints to self-supervised manifold regularization. Comprehensive experiments across multiple benchmarks show that our method achieves state-of-the-art performance in both continuous-time and standard optical flow estimation, demonstrating the effectiveness of the proposed learning paradigm.
Scaling Dense Event-Stream Pretraining from Visual Foundation Models
Mar 04, 2026Learning versatile, fine-grained representations from irregular event streams is pivotal yet nontrivial, primarily due to the heavy annotation that hinders scalability in dataset size, semantic richness, and application scope. To mitigate this dilemma, we launch a novel self-supervised pretraining method that distills visual foundation models (VFMs) to push the boundaries of event representation at scale. Specifically, we curate an extensive synchronized image-event collection to amplify cross-modal alignment. Nevertheless, due to inherent mismatches in sparsity and granularity between image-event domains, existing distillation paradigms are prone to semantic collapse in event representations, particularly at high resolutions. To bridge this gap, we propose to extend the alignment objective to semantic structures provided off-the-shelf by VFMs, indicating a broader receptive field and stronger supervision. The key ingredient of our method is a structure-aware distillation loss that grounds higher-quality image-event correspondences for alignment, optimizing dense event representations. Extensive experiments demonstrate that our approach takes a great leap in downstream benchmarks, significantly surpassing traditional methods and existing pretraining techniques. This breakthrough manifests in enhanced generalization, superior data efficiency and elevated transferability.
Towards Syn-to-Real IQA: A Novel Perspective on Reshaping Synthetic Data Distributions
Jan 01, 2026Blind Image Quality Assessment (BIQA) has advanced significantly through deep learning, but the scarcity of large-scale labeled datasets remains a challenge. While synthetic data offers a promising solution, models trained on existing synthetic datasets often show limited generalization ability. In this work, we make a key observation that representations learned from synthetic datasets often exhibit a discrete and clustered pattern that hinders regression performance: features of high-quality images cluster around reference images, while those of low-quality images cluster based on distortion types. Our analysis reveals that this issue stems from the distribution of synthetic data rather than model architecture. Consequently, we introduce a novel framework SynDR-IQA, which reshapes synthetic data distribution to enhance BIQA generalization. Based on theoretical derivations of sample diversity and redundancy's impact on generalization error, SynDR-IQA employs two strategies: distribution-aware diverse content upsampling, which enhances visual diversity while preserving content distribution, and density-aware redundant cluster downsampling, which balances samples by reducing the density of densely clustered areas. Extensive experiments across three cross-dataset settings (synthetic-to-authentic, synthetic-to-algorithmic, and synthetic-to-synthetic) demonstrate the effectiveness of our method. The code is available at https://github.com/Li-aobo/SynDR-IQA.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025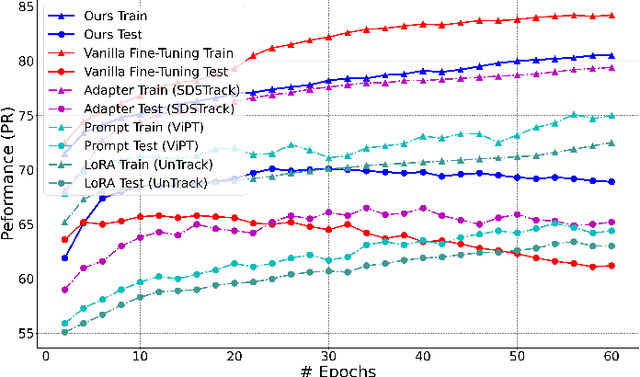

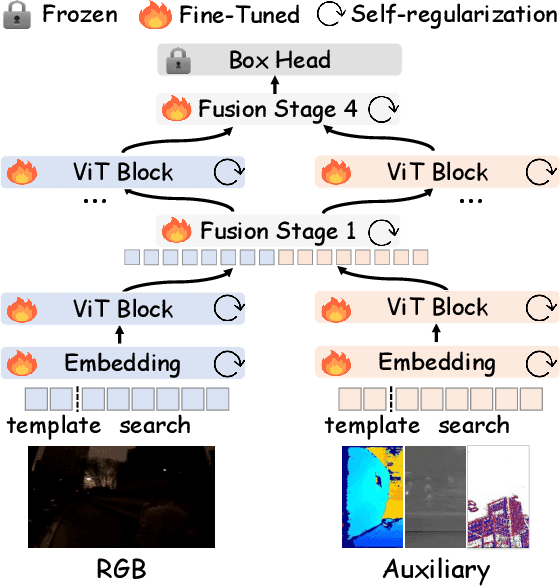
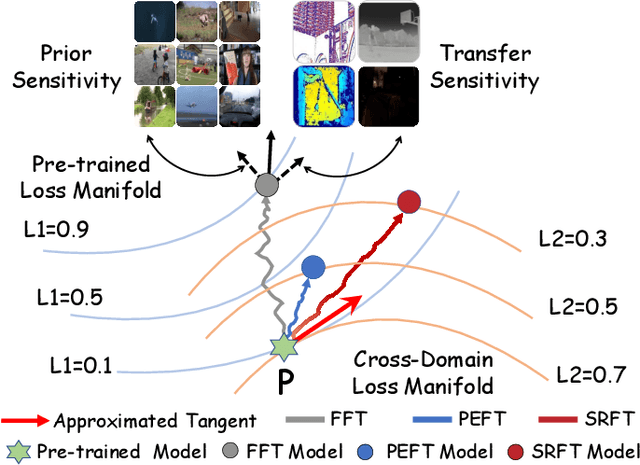
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
Language-Guided Visual Perception Disentanglement for Image Quality Assessment and Conditional Image Generation
Mar 04, 2025Contrastive vision-language models, such as CLIP, have demonstrated excellent zero-shot capability across semantic recognition tasks, mainly attributed to the training on a large-scale I&1T (one Image with one Text) dataset. This kind of multimodal representations often blend semantic and perceptual elements, placing a particular emphasis on semantics. However, this could be problematic for popular tasks like image quality assessment (IQA) and conditional image generation (CIG), which typically need to have fine control on perceptual and semantic features. Motivated by the above facts, this paper presents a new multimodal disentangled representation learning framework, which leverages disentangled text to guide image disentanglement. To this end, we first build an I&2T (one Image with a perceptual Text and a semantic Text) dataset, which consists of disentangled perceptual and semantic text descriptions for an image. Then, the disentangled text descriptions are utilized as supervisory signals to disentangle pure perceptual representations from CLIP's original `coarse' feature space, dubbed DeCLIP. Finally, the decoupled feature representations are used for both image quality assessment (technical quality and aesthetic quality) and conditional image generation. Extensive experiments and comparisons have demonstrated the advantages of the proposed method on the two popular tasks. The dataset, code, and model will be available.
E-Motion: Future Motion Simulation via Event Sequence Diffusion
Oct 11, 2024Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems.
Bridging the Synthetic-to-Authentic Gap: Distortion-Guided Unsupervised Domain Adaptation for Blind Image Quality Assessment
May 07, 2024The annotation of blind image quality assessment (BIQA) is labor-intensive and time-consuming, especially for authentic images. Training on synthetic data is expected to be beneficial, but synthetically trained models often suffer from poor generalization in real domains due to domain gaps. In this work, we make a key observation that introducing more distortion types in the synthetic dataset may not improve or even be harmful to generalizing authentic image quality assessment. To solve this challenge, we propose distortion-guided unsupervised domain adaptation for BIQA (DGQA), a novel framework that leverages adaptive multi-domain selection via prior knowledge from distortion to match the data distribution between the source domains and the target domain, thereby reducing negative transfer from the outlier source domains. Extensive experiments on two cross-domain settings (synthetic distortion to authentic distortion and synthetic distortion to algorithmic distortion) have demonstrated the effectiveness of our proposed DGQA. Besides, DGQA is orthogonal to existing model-based BIQA methods, and can be used in combination with such models to improve performance with less training data.
Denoising Distillation Makes Event-Frame Transformers as Accurate Gaze Trackers
Mar 31, 2024



This paper tackles the problem of passive gaze estimation using both event and frame data. Considering inherently different physiological structures, it's intractable to accurately estimate purely based on a given state. Thus, we reformulate the gaze estimation as the quantification of state transitions from the current state to several prior registered anchor states. Technically, we propose a two-stage learning-based gaze estimation framework to divide the whole gaze estimation process into a coarse-to-fine process of anchor state selection and final gaze location. Moreover, to improve generalization ability, we align a group of local experts with a student network, where a novel denoising distillation algorithm is introduced to utilize denoising diffusion technique to iteratively remove inherent noise of event data. Extensive experiments demonstrate the effectiveness of the proposed method, which greatly surpasses state-of-the-art methods by a large extent of 15$\%$. The code will be publicly available at https://github.com/jdjdli/Denoise_distill_EF_gazetracker.
Fast Window-Based Event Denoising with Spatiotemporal Correlation Enhancement
Feb 14, 2024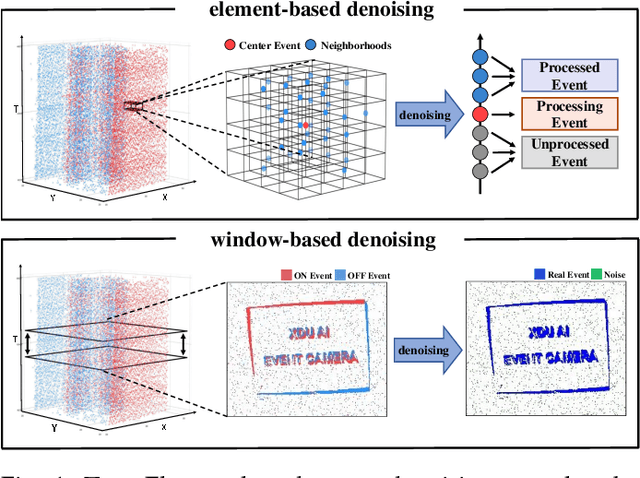
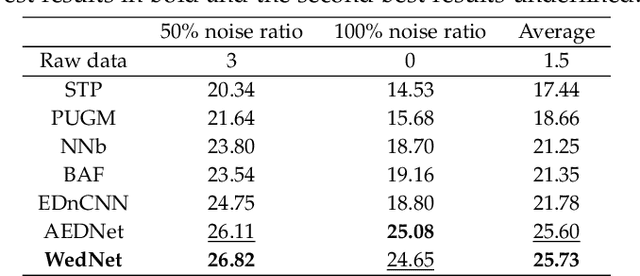
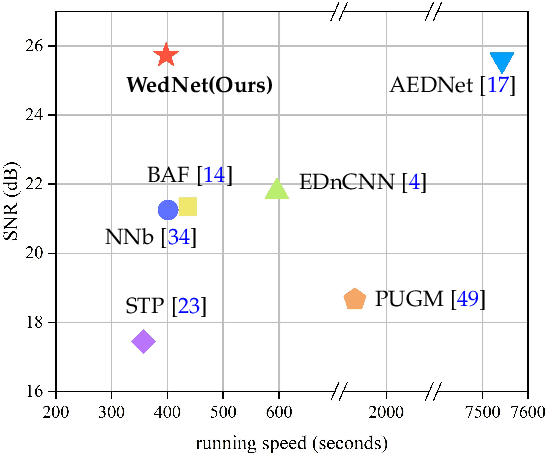
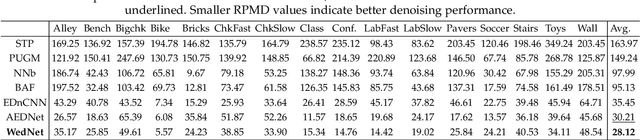
Previous deep learning-based event denoising methods mostly suffer from poor interpretability and difficulty in real-time processing due to their complex architecture designs. In this paper, we propose window-based event denoising, which simultaneously deals with a stack of events while existing element-based denoising focuses on one event each time. Besides, we give the theoretical analysis based on probability distributions in both temporal and spatial domains to improve interpretability. In temporal domain, we use timestamp deviations between processing events and central event to judge the temporal correlation and filter out temporal-irrelevant events. In spatial domain, we choose maximum a posteriori (MAP) to discriminate real-world event and noise, and use the learned convolutional sparse coding to optimize the objective function. Based on the theoretical analysis, we build Temporal Window (TW) module and Soft Spatial Feature Embedding (SSFE) module to process temporal and spatial information separately, and construct a novel multi-scale window-based event denoising network, named MSDNet. The high denoising accuracy and fast running speed of our MSDNet enables us to achieve real-time denoising in complex scenes. Extensive experimental results verify the effectiveness and robustness of our MSDNet. Our algorithm can remove event noise effectively and efficiently and improve the performance of downstream tasks.
Self-supervised Learning of LiDAR 3D Point Clouds via 2D-3D Neural Calibration
Jan 23, 2024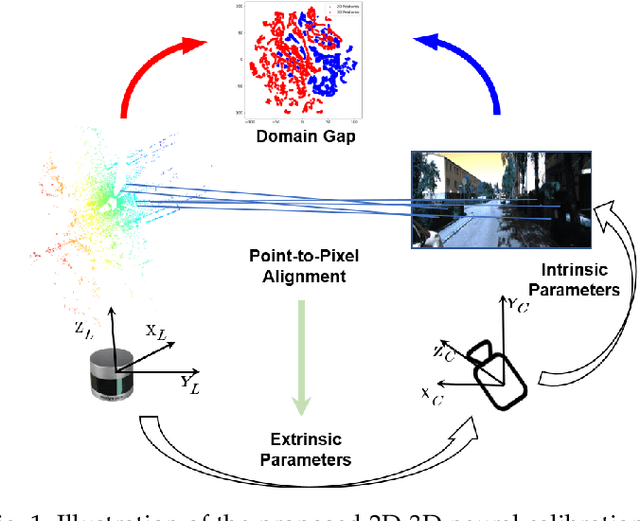
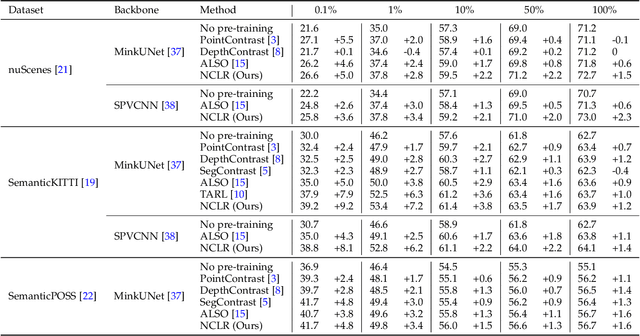
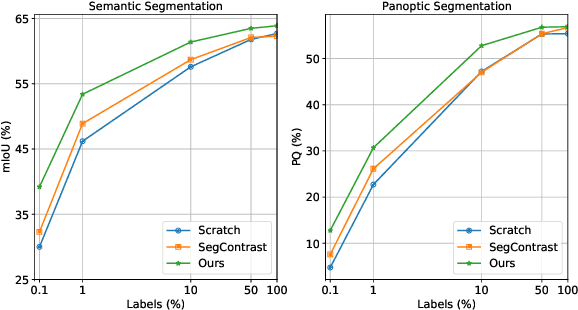
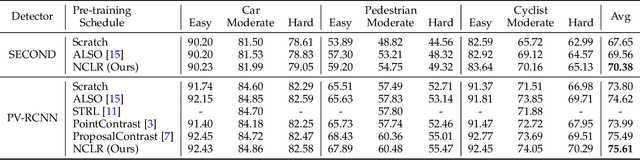
This paper introduces a novel self-supervised learning framework for enhancing 3D perception in autonomous driving scenes. Specifically, our approach, named NCLR, focuses on 2D-3D neural calibration, a novel pretext task that estimates the rigid transformation aligning camera and LiDAR coordinate systems. First, we propose the learnable transformation alignment to bridge the domain gap between image and point cloud data, converting features into a unified representation space for effective comparison and matching. Second, we identify the overlapping area between the image and point cloud with the fused features. Third, we establish dense 2D-3D correspondences to estimate the rigid transformation. The framework not only learns fine-grained matching from points to pixels but also achieves alignment of the image and point cloud at a holistic level, understanding their relative pose. We demonstrate NCLR's efficacy by applying the pre-trained backbone to downstream tasks, such as LiDAR-based 3D semantic segmentation, object detection, and panoptic segmentation. Comprehensive experiments on various datasets illustrate the superiority of NCLR over existing self-supervised methods. The results confirm that joint learning from different modalities significantly enhances the network's understanding abilities and effectiveness of learned representation. Code will be available at \url{https://github.com/Eaphan/NCLR}.