 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillDrive: End-to-End Multi-Mode Autonomous Driving Distillation by Isomorphic Hetero-Source Planning Model
Aug 07, 2025End-to-end autonomous driving has been recently seen rapid development, exerting a profound influence on both industry and academia. However, the existing work places excessive focus on ego-vehicle status as their sole learning objectives and lacks of planning-oriented understanding, which limits the robustness of the overall decision-making prcocess. In this work, we introduce DistillDrive, an end-to-end knowledge distillation-based autonomous driving model that leverages diversified instance imitation to enhance multi-mode motion feature learning. Specifically, we employ a planning model based on structured scene representations as the teacher model, leveraging its diversified planning instances as multi-objective learning targets for the end-to-end model. Moreover, we incorporate reinforcement learning to enhance the optimization of state-to-decision mappings, while utilizing generative modeling to construct planning-oriented instances, fostering intricate interactions within the latent space. We validate our model on the nuScenes and NAVSIM datasets, achieving a 50\% reduction in collision rate and a 3-point improvement in closed-loop performance compared to the baseline model. Code and model are publicly available at https://github.com/YuruiAI/DistillDrive
Unimodal-driven Distillation in Multimodal Emotion Recognition with Dynamic Fusion
Mar 31, 2025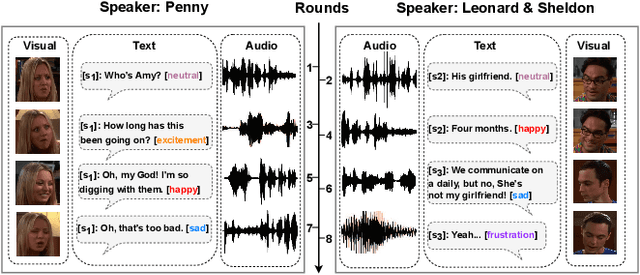
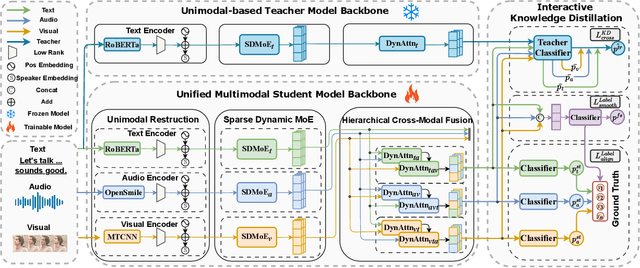
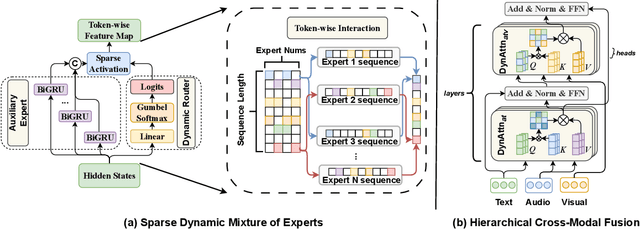
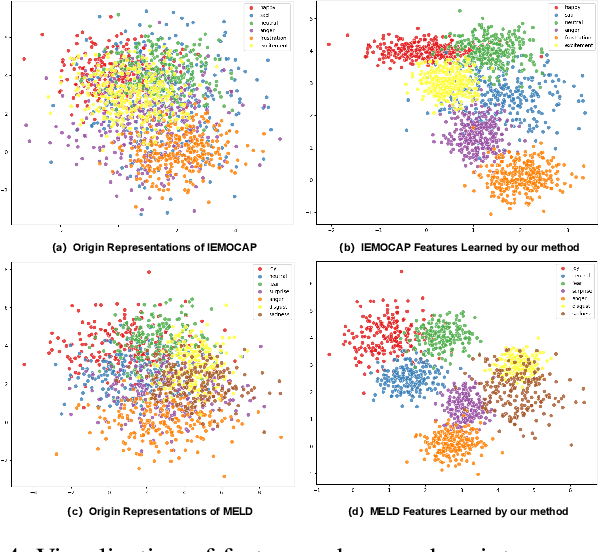
Multimodal Emotion Recognition in Conversations (MERC) identifies emotional states across text, audio and video, which is essential for intelligent dialogue systems and opinion analysis. Existing methods emphasize heterogeneous modal fusion directly for cross-modal integration, but often suffer from disorientation in multimodal learning due to modal heterogeneity and lack of instructive guidance. In this work, we propose SUMMER, a novel heterogeneous multimodal integration framework leveraging Mixture of Experts with Hierarchical Cross-modal Fusion and Interactive Knowledge Distillation. Key components include a Sparse Dynamic Mixture of Experts (SDMoE) for capturing dynamic token-wise interactions, a Hierarchical Cross-Modal Fusion (HCMF) for effective fusion of heterogeneous modalities, and Interactive Knowledge Distillation (IKD), which uses a pre-trained unimodal teacher to guide multimodal fusion in latent and logit spaces. Experiments on IEMOCAP and MELD show SUMMER outperforms state-of-the-art methods, particularly in recognizing minority and semantically similar emotions.
Source-Free Collaborative Domain Adaptation via Multi-Perspective Feature Enrichment for Functional MRI Analysis
Aug 24, 2023



Resting-state functional MRI (rs-fMRI) is increasingly employed in multi-site research to aid neurological disorder analysis. Existing studies usually suffer from significant cross-site/domain data heterogeneity caused by site effects such as differences in scanners/protocols. Many methods have been proposed to reduce fMRI heterogeneity between source and target domains, heavily relying on the availability of source data. But acquiring source data is challenging due to privacy concerns and/or data storage burdens in multi-site studies. To this end, we design a source-free collaborative domain adaptation (SCDA) framework for fMRI analysis, where only a pretrained source model and unlabeled target data are accessible. Specifically, a multi-perspective feature enrichment method (MFE) is developed for target fMRI analysis, consisting of multiple collaborative branches to dynamically capture fMRI features of unlabeled target data from multiple views. Each branch has a data-feeding module, a spatiotemporal feature encoder, and a class predictor. A mutual-consistency constraint is designed to encourage pair-wise consistency of latent features of the same input generated from these branches for robust representation learning. To facilitate efficient cross-domain knowledge transfer without source data, we initialize MFE using parameters of a pretrained source model. We also introduce an unsupervised pretraining strategy using 3,806 unlabeled fMRIs from three large-scale auxiliary databases, aiming to obtain a general feature encoder. Experimental results on three public datasets and one private dataset demonstrate the efficacy of our method in cross-scanner and cross-study prediction tasks. The model pretrained on large-scale rs-fMRI data has been released to the public.