 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnimodal-driven Distillation in Multimodal Emotion Recognition with Dynamic Fusion
Mar 31, 2025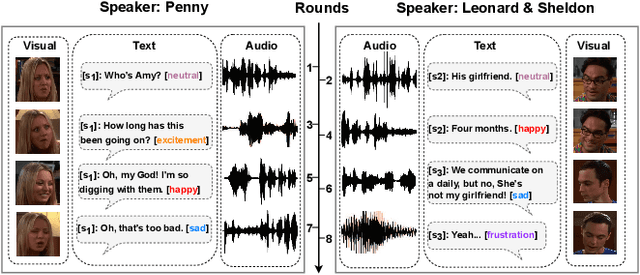
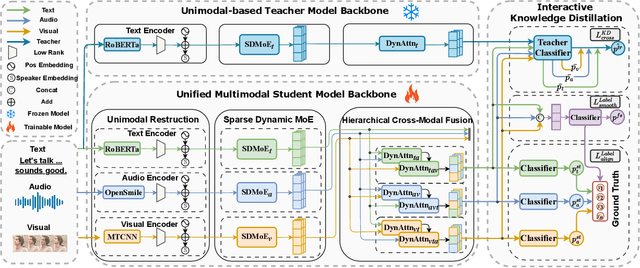
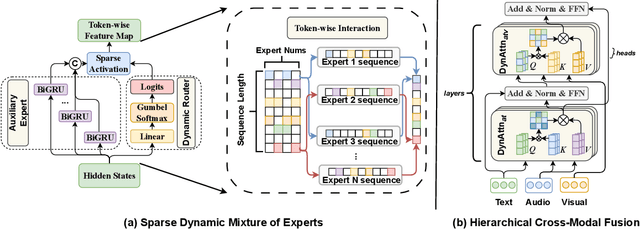
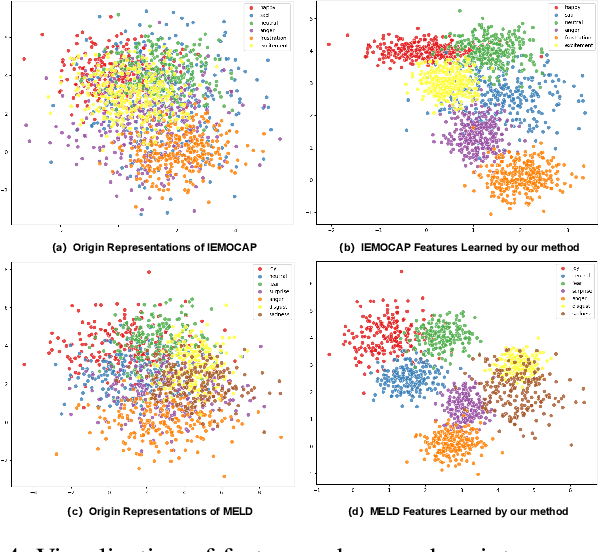
Multimodal Emotion Recognition in Conversations (MERC) identifies emotional states across text, audio and video, which is essential for intelligent dialogue systems and opinion analysis. Existing methods emphasize heterogeneous modal fusion directly for cross-modal integration, but often suffer from disorientation in multimodal learning due to modal heterogeneity and lack of instructive guidance. In this work, we propose SUMMER, a novel heterogeneous multimodal integration framework leveraging Mixture of Experts with Hierarchical Cross-modal Fusion and Interactive Knowledge Distillation. Key components include a Sparse Dynamic Mixture of Experts (SDMoE) for capturing dynamic token-wise interactions, a Hierarchical Cross-Modal Fusion (HCMF) for effective fusion of heterogeneous modalities, and Interactive Knowledge Distillation (IKD), which uses a pre-trained unimodal teacher to guide multimodal fusion in latent and logit spaces. Experiments on IEMOCAP and MELD show SUMMER outperforms state-of-the-art methods, particularly in recognizing minority and semantically similar emotions.
Unleashing the Potential of Mamba: Boosting a LiDAR 3D Sparse Detector by Using Cross-Model Knowledge Distillation
Sep 17, 2024



The LiDAR-based 3D object detector that strikes a balance between accuracy and speed is crucial for achieving real-time perception in autonomous driving and robotic navigation systems. To enhance the accuracy of point cloud detection, integrating global context for visual understanding improves the point clouds ability to grasp overall spatial information. However, many existing LiDAR detection models depend on intricate feature transformation and extraction processes, leading to poor real-time performance and high resource consumption, which limits their practical effectiveness. In this work, we propose a Faster LiDAR 3D object detection framework, called FASD, which implements heterogeneous model distillation by adaptively uniform cross-model voxel features. We aim to distill the transformer's capacity for high-performance sequence modeling into Mamba models with low FLOPs, achieving a significant improvement in accuracy through knowledge transfer. Specifically, Dynamic Voxel Group and Adaptive Attention strategies are integrated into the sparse backbone, creating a robust teacher model with scale-adaptive attention for effective global visual context modeling. Following feature alignment with the Adapter, we transfer knowledge from the Transformer to the Mamba through latent space feature supervision and span-head distillation, resulting in improved performance and an efficient student model. We evaluated the framework on the Waymo and nuScenes datasets, achieving a 4x reduction in resource consumption and a 1-2\% performance improvement over the current SoTA methods.