 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting SAM for Cross-Domain Few-Shot Segmentation via Conditional Point Sparsification
Feb 05, 2026Motivated by the success of the Segment Anything Model (SAM) in promptable segmentation, recent studies leverage SAM to develop training-free solutions for few-shot segmentation, which aims to predict object masks in the target image based on a few reference exemplars. These SAM-based methods typically rely on point matching between reference and target images and use the matched dense points as prompts for mask prediction. However, we observe that dense points perform poorly in Cross-Domain Few-Shot Segmentation (CD-FSS), where target images are from medical or satellite domains. We attribute this issue to large domain shifts that disrupt the point-image interactions learned by SAM, and find that point density plays a crucial role under such conditions. To address this challenge, we propose Conditional Point Sparsification (CPS), a training-free approach that adaptively guides SAM interactions for cross-domain images based on reference exemplars. Leveraging ground-truth masks, the reference images provide reliable guidance for adaptively sparsifying dense matched points, enabling more accurate segmentation results. Extensive experiments demonstrate that CPS outperforms existing training-free SAM-based methods across diverse CD-FSS datasets.
Unleashing the Potential of Mamba: Boosting a LiDAR 3D Sparse Detector by Using Cross-Model Knowledge Distillation
Sep 17, 2024



The LiDAR-based 3D object detector that strikes a balance between accuracy and speed is crucial for achieving real-time perception in autonomous driving and robotic navigation systems. To enhance the accuracy of point cloud detection, integrating global context for visual understanding improves the point clouds ability to grasp overall spatial information. However, many existing LiDAR detection models depend on intricate feature transformation and extraction processes, leading to poor real-time performance and high resource consumption, which limits their practical effectiveness. In this work, we propose a Faster LiDAR 3D object detection framework, called FASD, which implements heterogeneous model distillation by adaptively uniform cross-model voxel features. We aim to distill the transformer's capacity for high-performance sequence modeling into Mamba models with low FLOPs, achieving a significant improvement in accuracy through knowledge transfer. Specifically, Dynamic Voxel Group and Adaptive Attention strategies are integrated into the sparse backbone, creating a robust teacher model with scale-adaptive attention for effective global visual context modeling. Following feature alignment with the Adapter, we transfer knowledge from the Transformer to the Mamba through latent space feature supervision and span-head distillation, resulting in improved performance and an efficient student model. We evaluated the framework on the Waymo and nuScenes datasets, achieving a 4x reduction in resource consumption and a 1-2\% performance improvement over the current SoTA methods.
DROP: Decouple Re-Identification and Human Parsing with Task-specific Features for Occluded Person Re-identification
Jan 31, 2024The paper introduces the Decouple Re-identificatiOn and human Parsing (DROP) method for occluded person re-identification (ReID). Unlike mainstream approaches using global features for simultaneous multi-task learning of ReID and human parsing, or relying on semantic information for attention guidance, DROP argues that the inferior performance of the former is due to distinct granularity requirements for ReID and human parsing features. ReID focuses on instance part-level differences between pedestrian parts, while human parsing centers on semantic spatial context, reflecting the internal structure of the human body. To address this, DROP decouples features for ReID and human parsing, proposing detail-preserving upsampling to combine varying resolution feature maps. Parsing-specific features for human parsing are decoupled, and human position information is exclusively added to the human parsing branch. In the ReID branch, a part-aware compactness loss is introduced to enhance instance-level part differences. Experimental results highlight the efficacy of DROP, especially achieving a Rank-1 accuracy of 76.8% on Occluded-Duke, surpassing two mainstream methods. The codebase is accessible at https://github.com/shuguang-52/DROP.
Towards Privacy-Preserving Person Re-identification via Person Identify Shift
Jul 15, 2022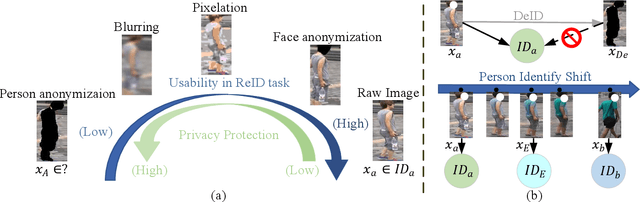
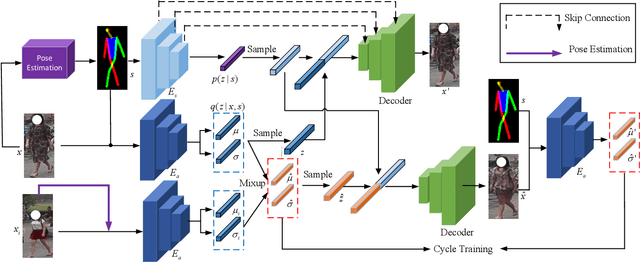

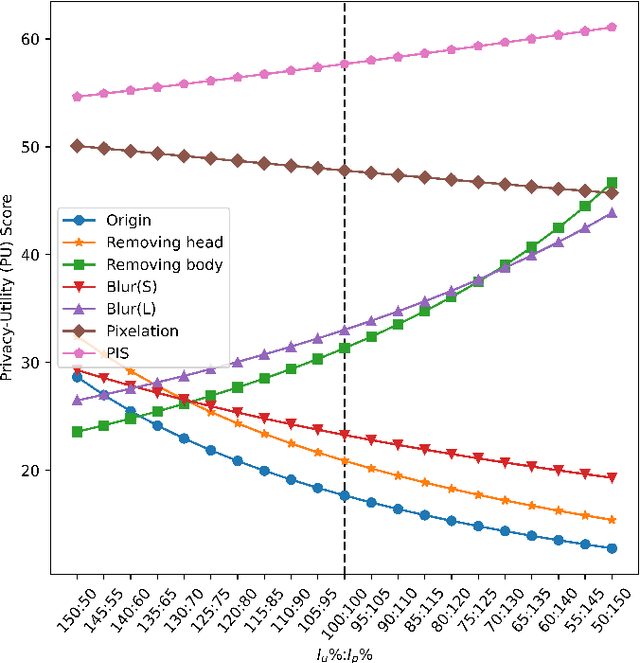
Recently privacy concerns of person re-identification (ReID) raise more and more attention and preserving the privacy of the pedestrian images used by ReID methods become essential. De-identification (DeID) methods alleviate privacy issues by removing the identity-related of the ReID data. However, most of the existing DeID methods tend to remove all personal identity-related information and compromise the usability of de-identified data on the ReID task. In this paper, we aim to develop a technique that can achieve a good trade-off between privacy protection and data usability for person ReID. To achieve this, we propose a novel de-identification method designed explicitly for person ReID, named Person Identify Shift (PIS). PIS removes the absolute identity in a pedestrian image while preserving the identity relationship between image pairs. By exploiting the interpolation property of variational auto-encoder, PIS shifts each pedestrian image from the current identity to another with a new identity, resulting in images still preserving the relative identities. Experimental results show that our method has a better trade-off between privacy-preserving and model performance than existing de-identification methods and can defend against human and model attacks for data privacy.
Rethinking the Zigzag Flattening for Image Reading
Mar 15, 2022


Sequence ordering of word vector matters a lot to text reading, which has been proven in natural language processing (NLP). However, the rule of different sequence ordering in computer vision (CV) was not well explored, e.g., why the "zigzag" flattening (ZF) is commonly utilized as a default option to get the image patches ordering in vision transformers (ViTs). Notably, when decomposing multi-scale images, the ZF could not maintain the invariance of feature point positions. To this end, we investigate the Hilbert fractal flattening (HF) as another method for sequence ordering in CV and contrast it against ZF. The HF has proven to be superior to other curves in maintaining spatial locality, when performing multi-scale transformations of dimensional space. And it can be easily plugged into most deep neural networks (DNNs). Extensive experiments demonstrate that it can yield consistent and significant performance boosts for a variety of architectures. Finally, we hope that our studies spark further research about the flattening strategy of image reading.
GSC Loss: A Gaussian Score Calibrating Loss for Deep Learning
Mar 02, 2022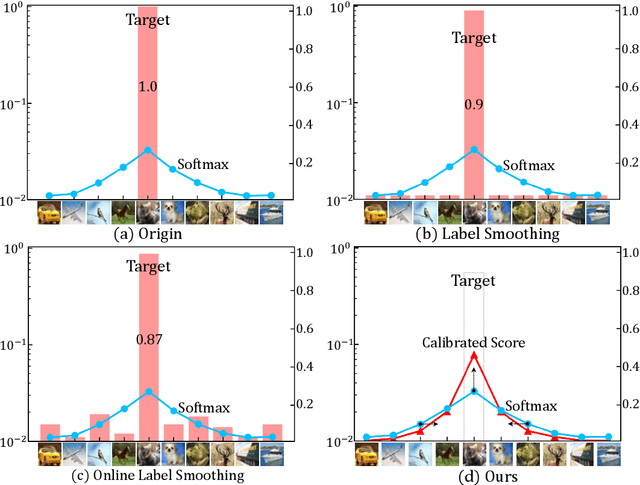
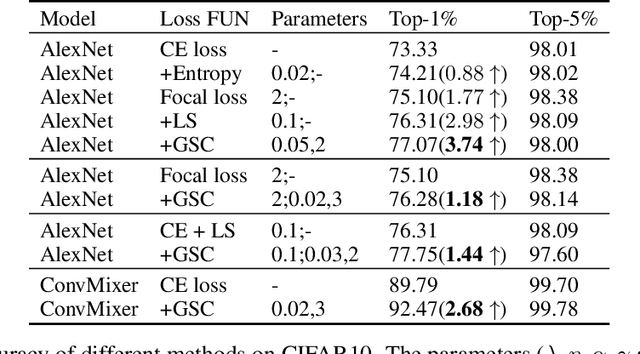
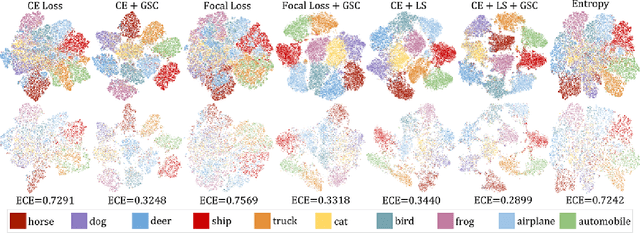
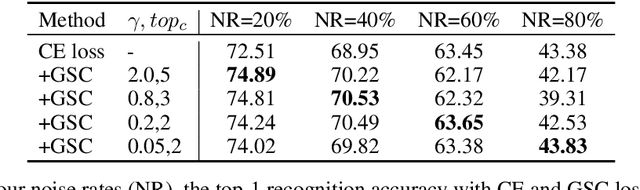
Cross entropy (CE) loss integrated with softmax is an orthodox component in most classification-based frameworks, but it fails to obtain an accurate probability distribution of predicted scores that is critical for further decision-making of poor-classified samples. The prediction score calibration provides a solution to learn the distribution of predicted scores which can explicitly make the model obtain a discriminative representation. Considering the entropy function can be utilized to measure the uncertainty of predicted scores. But, the gradient variation of it is not in line with the expectations of model optimization. To this end, we proposed a general Gaussian Score Calibrating (GSC) loss to calibrate the predicted scores produced by the deep neural networks (DNN). Extensive experiments on over 10 benchmark datasets demonstrate that the proposed GSC loss can yield consistent and significant performance boosts in a variety of visual tasks. Notably, our label-independent GSC loss can be embedded into common improved methods based on the CE loss easily.